亚马逊AWS官方博客
使用 Amazon Neptune 构建基于图数据库的应用
在社交网络、推荐引擎和欺诈检测等应用场景中,您需要在数据之间创建关系并快速查询这些关系,此时,图数据库将比关系数据库更具优势。因为使用关系数据库构建这些类型的应用程序面临着许多挑战。您将需要创建多个具有多个外键的表,SQL 查询需要嵌套查询和复杂的联接,它们很快就会变得不灵活,而且随着数据量逐渐增加,查询的性能也会降低。
Amazon Neptune是一个高性能图数据库,并对图的存储和查询进行了优化,可以存储数十亿个关系并将图形查询延迟降低到毫秒级。它也是一个托管的图数据库,能快速创建图数据库集群,减少了运维和管理图数据库的工作,让我们把工作重心放在业务开发和创新上。Amazon Neptune 支持常见的图形模型 Property Graph 和 W3C 的 RDF 及其关联的查询语言 Apache TinkerPop Gremlin 和 SPARQL,从而使您能够轻松构建查询以有效地分析高度互连数据集。它支持社交网络分析、建议引擎、欺诈检测、知识图谱、药物开发和网络安全等应用案例。
下面我们将一步步告诉大家如何创建和使用Amazon Neptune。
1.创建Amazon Netpune
我们可以登录AWS Console,找到Neptune的界面,如下图:
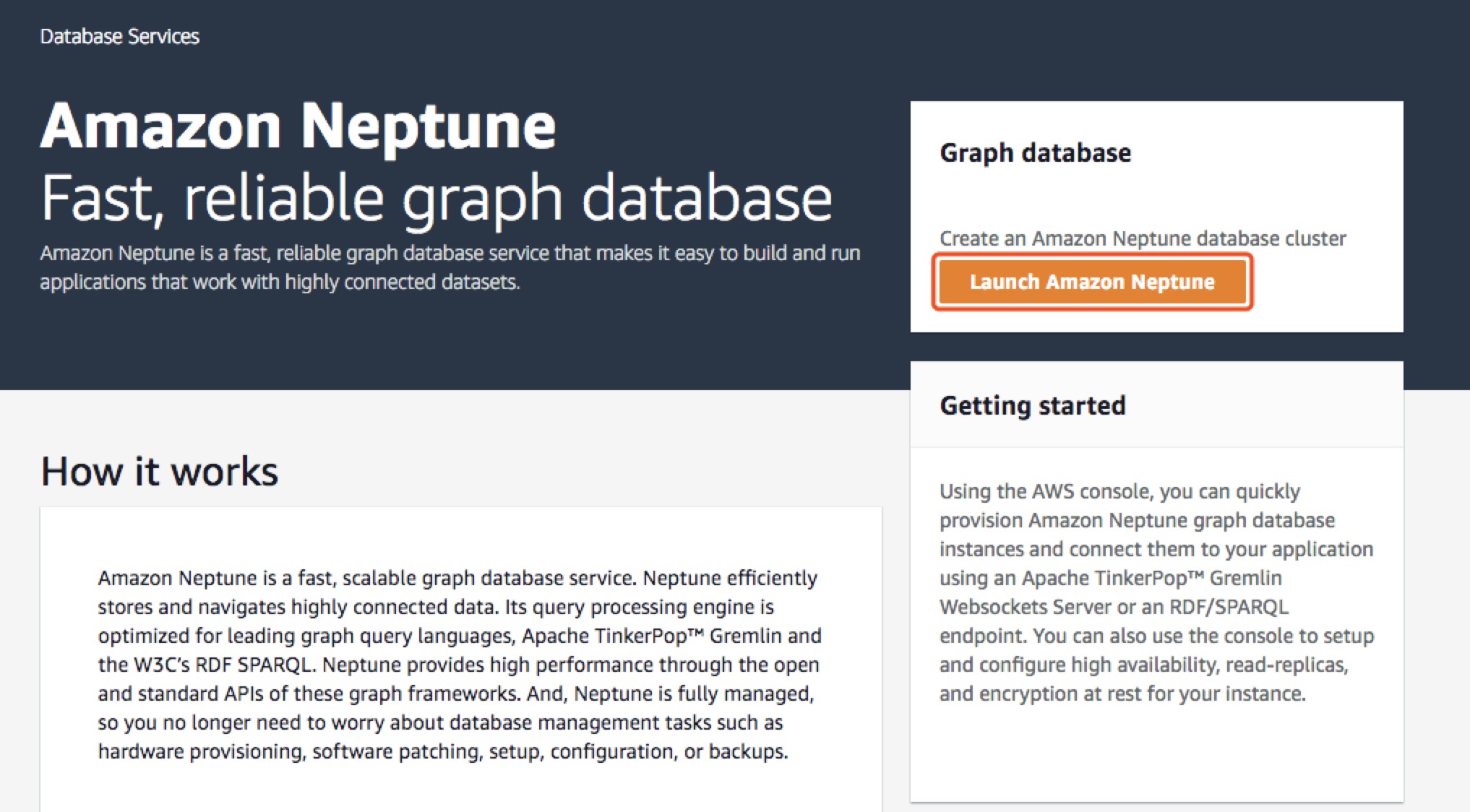
选择点击 “Launch Amazon Neptune”的图标。会看到下面详细信息界面:

在此界面上可以指定是否在不同区域创建只读副本。只读副本不仅可以支持只读类型的工作负载,还可以提高集群的高可用性。当主实例出现故障,会自动故障转移到您在三个可用区之一中创建的多达 15 个 Neptune 副本中的一个。输入完后点击 “Next”,进入网络和安全配置页面。

对于生产数据库,我们推荐用户将Amazon Neptune放在自己创建的VPC中,并且将数据库放在私有子网组中,访问数据库时可以通过VPN或堡垒机的方式在私有子网中维护您的数据库。另外通过安全组来设置访问客户端的端口及IP等。安全组是白名单的机制,意味着只有您设置的IP源及端口可以访问您的数据库,从而保障数据库的安全。
通过上面几个界面的操作,等待几分钟左右, Amazon Neptune数据库集群成功。
2.设置访问Amazon Neptune数据库的安全组
数据库创建完后,需要设置安全组,让需要的客户端能够访问数据库。您可以在Amazon Neptune的界面上找当前安全组,并进行修改。如下图:

这里我内网的IP地址域是 172.31.0.0/16,因此设置的是所有内网的机器都能够访问我的数据库。要设置其它规则,和这个类似。
3.连接Amazon Neptune
数据库集群建立好后,我们需要创建一个EC2实例作为客户端访问数据库。登录AWS Console并访问EC2服务,选择Amazon Linux作为客户端。
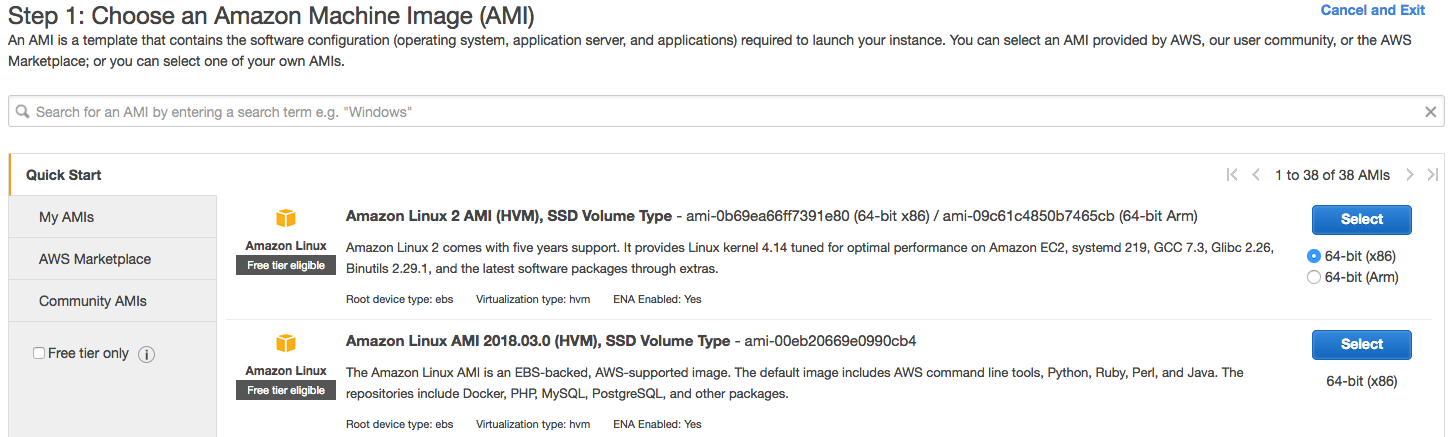
Amazon Linux是列表中第二项。
4.在EC2客户端上安装连接工具
下面我们会使用跟Amazon Neptune在同一个子网中的EC2实例(前面第三步创建)来连接Amazon Neptune的实例。
1)控制台二进制文件需要 Java 8。输入以下命令以在 EC2 实例上安装 Java 8。
2)输入以下命令以在 EC2 实例上将 Java 8 设置为默认运行时。
系统会显示系统安装过的所有java的版本,输入java 8对应的数字。
3)从Apache Tinkerpop3网站下载访问Amazon Neptune的Gremlin客户端
wget https://archive.apache.org/dist/tinkerpop/3.4.1/apache-tinkerpop-gremlin-console-3.4.1-bin.zip
4)解压下载的压缩文件
unzip apache-tinkerpop-gremlin-console-3.4.1-bin.zip
5)进入解压后的文件夹,并下载Gremlin远程证书
cd apache-tinkerpop-gremlin-console-3.4.1
wget https://www.amazontrust.com/repository/SFSRootCAG2.pem
6)在conf目录中创建名为neptune-remote.yaml的文件,并加入下面信息:
hosts: [your-neptune-endpoint]
port: 8182
connectionPool: { enableSsl: true, trustCertChainFile: “SFSRootCAG2.pem”}
serializer: { className: org.apache.tinkerpop.gremlin.driver.ser.GryoMessageSerializerV3d0, config: { serializeResultToString: true }}
其中红色部分的Endpint是您要连接的数据库的端点,请在AWS Neptune Console上查询,如下图:

在图中你可以看到连接的Endpoint。
7)运行bin目录下的命令进入Gremlin控制台
看到如下界面:

此时我们可以看到gremlin的命令行提示符
8)在gremlin>命令行提示符下,输入前面配置endpoint的文件,让gremlin连接我们创建的neptune数据库。

可以看到gremlin连接了我们配置的Neptune数据库。
9)输入下面命令,控制gremlin发送所有的命令到远程Neptune服务器:

10)为图增加一个顶点,输入下面命令

11)输入下面命令退出
5.加载数据
除了在上一步中所见的通过命令行插入数据到图数据库中,我们也可以将一定格式的数据存储到S3中,然后加载到图数据库中,详情,请参考下面链接加载和查询数据:
https://docs.aws.amazon.com/zh_cn/neptune/latest/userguide/load-api-reference-load.html
6.总结
前面介绍了Amazon Neptune的使用场景及创建和连接一个Amazon Neptune图数据库的基本步骤。Amazon Neptune 是一项快速、可靠且完全托管的图形数据库服务,可以帮助您轻松构建和运行处理高度互连数据集的应用程序。您可以将外部的数据导入到Amazon Neptune中,也可以从头用Amazon Neptune构建图的应用。