前言
与MongoDB兼容的Amazon DocumentDB,使用完全托管式文档数据库服务轻松扩展 JSON 工作负载,通过独立扩展计算和存储,支持每秒数以百万计文档的读取请求;自动化硬件预置、修补、设置和其他数据库管理任务;通过自动复制、连续备份和严格的网络隔离实现 99.999999999% 的持久性;将现有 MongoDB 驱动程序和工具与 Apache 2.0 开源 MongoDB 3.6 和 4.0 API 搭配使用。鉴于上述性能优势,越来越多的企业已经或即将使用DocumentDB来管理JSON文档数据库。
对很多行业而言,需要保证数据与业务的持续性,存在关键业务与数据的容灾诉求。亚马逊云科技于2021年6月推出了面向Amazon DocumentDB(兼容MongoDB)的全局集群(Global Cluster)。全局集群是一项新功能,可在发生区域范围的中断时提供灾难恢复,同时通过允许从最近的 Amazon DocumentDB 集群读取来实现低延迟全局读取。客户可以将业务发生Region内的DocumentDB通过该功能同步至其他Region,轻松实现数据层的跨区域容灾。但由于Global Cluster全局集群功能是基于存储的快速复制,所以很遗憾,截止本文发稿时,DocumentDB Global Cluster全局集群仅支持实例级别的数据同步与复制,暂不支持Database或者Collection级别的数据容灾。
亚马逊云科技还有另一款数据库产品Amazon Data Migration Server(DMS),可以实现Database或者Collection级别的数据同步,以低延迟与较低的RPO指标实现数据的跨区域同步与复制,以实现容灾的需求。但在面对容灾场景中的数据保护诉求,DMS暂不支持对删除类型的操作进行过滤。
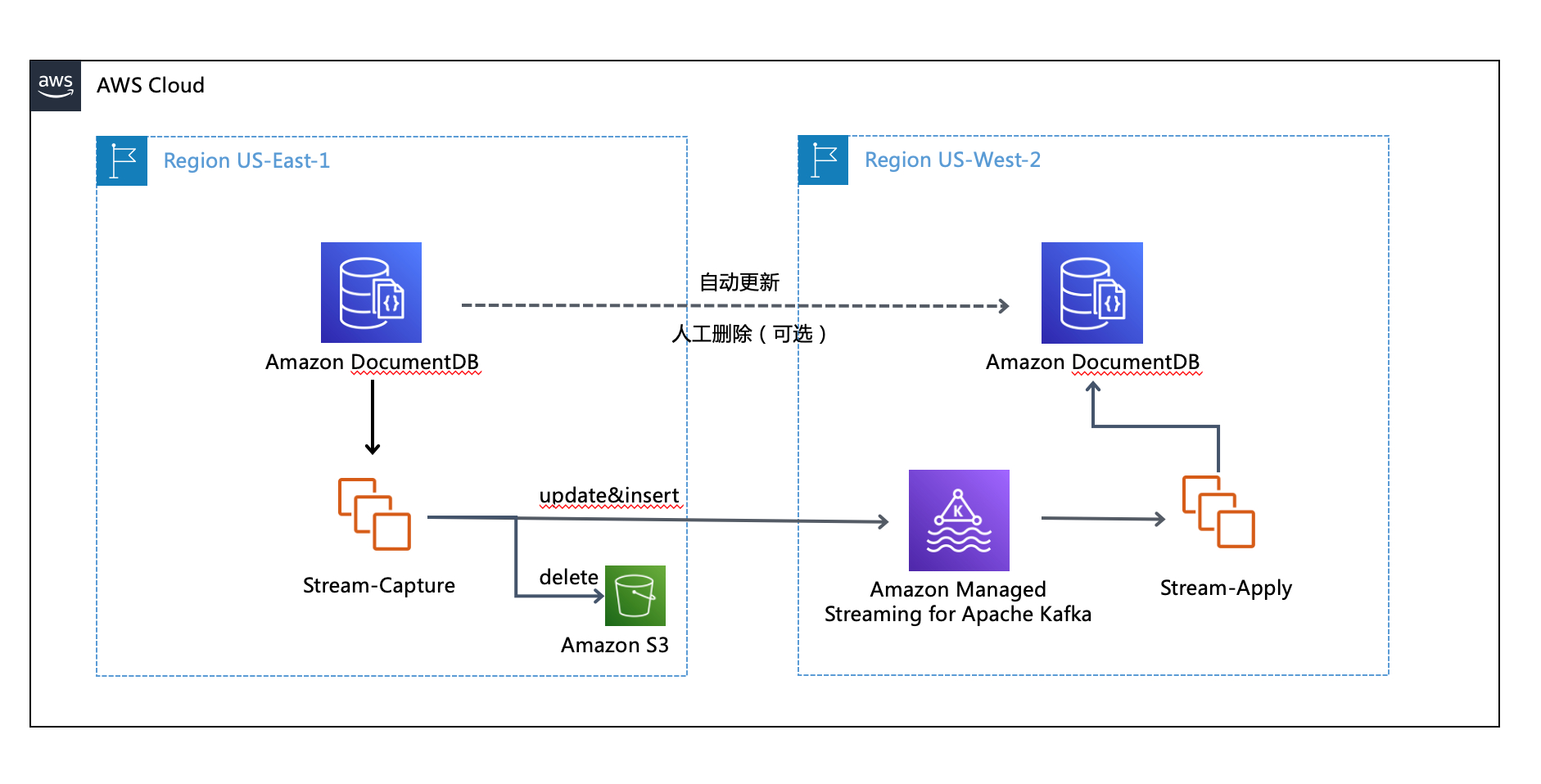
在本文中,我们将向您介绍使用Amazon Managed Streaming for Apache Kafka(MSK)作为消息中间件暂存DocumentDB的改变流事件Change Stream Events,来实现跨Region的数据库同步,并拦截删除类型的操作的整体解决方案。本例中,我们采用us-east-1弗吉尼亚北部区域作为主区域Primary Region,已有DocumentDB主实例,us-west-2俄勒冈区域作为灾备区域DR Region,已有DocumentDB灾备实例,使用了python作为编程语言,除python外您还可以使用其他主流编程语言譬如Java,Node.JS实现业务逻辑,但由于驱动原因,暂不支持Ruby;另外请使用Amazon DocumentDB v4.0以上版本。参考架构图如下图所示:

主region的stream-capture主机环境设置
1.在主region的stream-capture主机上设置OS参数环境
Code部分:
##设置环境变量,请替换红色的文字部分为您实际的值,本文中默认采用bar.foo为改变流监控collection,您可以替换为您自定义的其他DB与collection
##设置环境变量,请替换红色的文字部分为您实际的值,本文中默认采用bar.foo为改变流监控collection,您可以替换为您自定义的其他DB与collection
echo -e "USERNAME="Your Primary MongoDB User"\nexport USERNAME\nPASSWORD="Your Primary MongoDB password"\nexport PASSWORD\nmongo_host="Primary MongoDB Cluster URI"\nexport mongo_host\nstate_tbl="YOUR STATE COLLECTION"\nexport state_tbl\nstate_db="YOUR STATE DB"\nexport state_db\nwatched_db_name="bar"\nexport watched_db_name\nwatched_tbl_name="foo"\nexport watched_tbl_name\nevents_remain=1\nexport events_remain\nDocuments_per_run=100000\nexport Documents_per_run\nkfk_host="YOUR KFK URI\nexport kfk_host\nkfk_topic="changevents"\nexport kfk_topic\nbucket_name="YOUR S3 BUCKET"\nexport bucket_name\nS3_prefix=""\nexport S3_prefix"" >> .bash_profile
##应用环境变量
source .bash_profile
2. 在主region的stream-capture主机上安装pymongo与boto3
请参考如何在 Amazon Linux 2 上使用 Boto 3 库创建 Python 3 虚拟环境
完成python3与boto3的安装与配置,本文不再复述
##安装pymongo
sudo pip install pymongo
3. 在主region的stream-capture主机上安装MongoDB客户端与证书
##下载SSL证书到/tmp下
wget -P /tmp https://s3.amazonaws.com/rds-downloads/rds-combined-ca-bundle.pem
##配置MongoDB的YUM REPO
sudo echo -e "[mongodb-org-5.0]\nname=MongoDB Repository\nbaseurl=https://repo.mongodb.org/yum/amazon/2/mongodb-org/5.0/x86_64/\ngpgcheck=1\nenabled=\ngpgkey=https://www.mongodb.org/static/pgp/server-5.0.asc" >> /etc/yum.repos.d/mongodb-org-5.0.repo
##安装MongoDB 客户端
sudo yum install -y mongodb-org-shell
创建MSK的Topic用以接受改变流事件
请参照本文档【开始使用MSK第3步:创建主题】来创建MSK的topic,本文不再复述。请将步骤12中的–topic MSKTutorialTopic替换–topic changevents 之后,执行第步骤12
我们将可以看到如下消息:
Created topic changevents.
启用Amazon DocumentDB改变流
1.使用mongosh客户端登陆主DocumentDB集群
Mongo --host $mongo_host:27017 --ssl --sslCAFile
/tmp/rds-combined-ca-bundle.pem --username $USERNAME --password $PASSWORD
2.对bar.foo启用改变流
db.adminCommand({modifyChangeStreams: 1,database: "bar",collection: "foo", enable: true});
3.确认成功
{ "ok" : 1 }
主region的改变流捕获程序
#!/bin/env python
import json
import logging
import os
import time
import boto3
import datetime
from pymongo import MongoClient
from pymongo.errors import OperationFailure
from kafka import KafkaProducer
db_client = None
kafka_client = None
s3_client = None
logging.basicConfig(Level=logging.ERROR)
# The error code returned when data for the requested resume token has been deleted
err_code_136 = 136
def get_db_client():
# Use a global variable if CX has interest in Lambda function instead of long-running python
global db_client
if db_client is None:
logging.debug('Creating a new DB client.')
try:
username = os.environ[‘USERNAME’]
password = os.environ[‘PASSWORD’]
cluster_uri = os.environ['mongo_host']
db_client = MongoClient(cluster_uri, ssl=True, retryWrites=False, ssl_ca_certs='/tmp/rds-combined-ca-bundle.pem')
# Make an attemp for connecting
db_client.admin.command('ismaster')
db_client["admin"].authenticate(name=username, password=password)
logging.debug('Successfully created a new DB client.')
except Exception as err:
logging.error('Failed to create a new DB client: {}'.format(err))
raise
return db_client
def get_state_tbl_client():
"""Return a DocumentDB client for the collection in which we store processing state."""
try:
db_client = get_db_client()
state_db_name = os.environ['state_db']
state_tbl_name = os.environ['state_tbl']
state_tbl = db_client[state_db_name][state_tbl_name]
except Exception as err:
logging.error('Failed to create new state collection client: {}'.format(err))
raise
return state_tbl
def get_last_position():
last_position = None
logging.debug('Locate the last position.’)
try:
state_tbl = get_state_tbl_client()
if "watched_tbl_name" in os.environ:
position_point = state_tbl.find_one({'currentposition': True, 'watched_db': str(os.environ['watched_db_name']),
'watched_tbl': str(os.environ['watched_tbl_name']), 'db_level': False})
else:
position_point = state_tbl.find_one({'currentposition': True, 'db_level': True,
'watched_db': str(os.environ['watched_db_name'])})
if position_point is not None:
if 'lastProcessed' in position_point:
last_position = position_point['lastProcessed']
else:
if "watched_tbl_name" in os.environ:
state_tbl.insert_one({'watched_db': str(os.environ['watched_db_name']),
'watched_tbl': str(os.environ['watched_tbl_name']), 'currentposition': True, 'db_level': False})
else:
state_tbl.insert_one({'watched_db': str(os.environ['watched_db_name']), 'currentposition': True,
'db_level': True})
except Exception as err:
logging.error('Failed to locate the last processed id: {}'.format(err))
raise
return last_position
def save_last_position(resume_token):
"""Save the resume token by the last successfully processed change event."""
logging.debug('Saving last processed id.')
try:
state_tbl = get_state_tbl_client()
if "watched_tbl_name" in os.environ:
state_tbl.update_one({'watched_db': str(os.environ['watched_db_name']),
'watched_tbl': str(os.environ['watched_tbl_name'])},{'$set': {'lastProcessed': resume_token}})
else:
state_tbl.update_one({'watched_db': str(os.environ['watched_db_name']), 'db_level': True, },
{'$set': {'lastProcessed': resume_token}})
except Exception as err:
logging.error('Failed to save last processed id: {}'.format(err))
raise
def conn_kfk_producer():
# Use a global variable if CX has interest in Lambda function instead of long-running python
global kafka_client
if kafka_client is None:
logging.debug('Creating a new Kafka client.')
try:
kafka_client = KafkaProducer(bootstrap_servers=os.environ['kfk_host'])
except Exception as err:
logging.error('Failed to create a new Kafka client: {}'.format(err))
raise
return kafka_client
def produce_msg(producer_instance, topic_name, key, value):
"""Produce change events to MSK."""
try:
topic_name = os.environ['kfk_topic']
producer_instance = KafkaProducer(key_serializer=lambda key: json.dumps(key).encode('utf-8’),value_serializer=lambda value: json.dumps(value).encode('utf-8’),retries=3)
producer_instance.send(topic_name, key, value)
producer_instance.flush()
except Exception as err:
logging.error('Error in publishing message: {}'.format(err))
raise
def write_S3(event, database, collection, doc_id):
global s3_client
if s3_client is None:
s3_client = boto3.resource('s3')
try:
logging.debug('Publishing message to S3.') #, str(os.environ['S3_prefix'])
if "S3_prefix" in os.environ:
s3_client.Object(os.environ['bucket_name'], str(os.environ['S3_prefix']) + '/' + database + '/' +
collection + '/' + datetime.datetime.now().strftime('%Y/%m/%d/') + doc_id).put(Body=event)
else:
s3_client.Object(os.environ['bucket_name'], database + '/' + collection + '/' +
datetime.datetime.now().strftime('%Y/%m/%d/') + doc_id).put(Body=event)
except Exception as err:
logging.error('Error in publishing message to S3: {}'.format(err))
raise
def main(event, context):
"""Read change events from DocumentDB and push them to MSK&S3."""
events_processed = 0
watcher = None
kafka_client = None
try:
# Kafka client set up
if "kfk_host" in os.environ:
kafka_client = conn_kfk_producer()
logging.debug('Kafka client set up.')
# DocumentDB watched collection set up
db_client = get_db_client()
watched_db = os.environ['watched_db_name']
if "watched_tbl_name" in os.environ:
watched_tbl = os.environ['watched_tbl_name']
watcher = db_client[watched_db][watched_tbl]
else:
watcher = db_client[watched_db]
logging.debug('Watching table {}'.format(watcher))
# DocumentDB sync set up
state_sync_count = int(os.environ['events_remain'])
last_position = get_last_position()
logging.debug("last_position: {}".format(last_position))
with watcher.watch(full_document='updateLookup', resume_after=last_position) as change_stream:
i = 0
state = 0
while change_stream.alive and i < int(os.environ['Documents_per_run']):
i += 1
change_event = change_stream.try_next()
logging.debug('Event: {}'.format(change_event))
if change_event is None:
Time.sleep(0.5)
Continue
else:
op_type = change_event['operationType']
op_id = change_event['_id']['_data']
if op_type == insert':
doc_body = change_event['fullDocument']
doc_id = str(doc_body.pop("_id", None))
insert_body = doc_body
readable = datetime.datetime.fromtimestamp(change_event['clusterTime'].time).isoformat()
doc_body.update({'operation':op_type,'timestamp':str(change_event['clusterTime'].time),'timestampReadable':str(readable)})
doc_body.update({'insert_body':json.dumps(insert_body)})
doc_body.update({'db':str(change_event['ns']['db']),'coll':str(change_event['ns']['coll'])})
payload = {'_id':doc_id}
payload.update(doc_body)
# Publish event to MSK
produce_msg(kafka_client, kfk_topic, op_id, payload)
if op_type == 'update':
doc_id = str(documentKey["_id"])
readable = datetime.datetime.fromtimestamp(change_event['clusterTime'].time).isoformat()
doc_body.update({'operation':op_type,'timestamp':str(change_event['clusterTime'].time),'timestampReadable':str(readable)})
doc_body.update({'updateDescription':json.dumps(updateDescription)})
doc_body.update({'db':str(change_event['ns']['db']),'coll':str(change_event['ns']['coll'])})
payload = {'_id':doc_id}
payload.update(doc_body)
# Publish event to MSK
produce_msg(kafka_client, kfk_topic, op_id, payload)
if op_type == 'delete':
doc_id = str(change_event['documentKey']['_id'])
readable = datetime.datetime.fromtimestamp(change_event['clusterTime'].time).isoformat()
doc_body.update({'operation':op_type,'timestamp':str(change_event['clusterTime'].time),'timestampReadable':str(readable)})
doc_body.update({'db':str(change_event['ns']['db']),'coll':str(change_event['ns']['coll'])})
payload = {'_id':doc_id}
payload.update(doc_body)
# Append event for S3
if "bucket_name" in os.environ:
write_S3(op_id, json.dumps(payload))
logging.debug('Processed event ID {}'.format(op_id))
events_processed += 1
except OperationFailure as of:
if of.code == err_code_136:
# Data for the last processed ID has been deleted in the change stream,
# Store the last known good state so our next invocation
# starts from the most recently available data
save_last_position(None)
raise
except Exception as err:
logging.error(‘Positionpoint lost: {}'.format(err))
raise
else:
if events_processed > 0:
save_last_position(change_stream.resume_token)
logging.debug('Synced token {} to state collection'.format(change_stream.resume_token))
return{
'statusCode': 200,
'description': 'Success',
'detail': json.dumps(str(events_processed)+ ' records processed successfully.')
}
else:
return{
'statusCode': 201,
'description': 'Success',
'detail': json.dumps('No records to process.')
}
finally:
# Close Kafka client
if "kfk_host" in os.environ:
kafka_client.close()
容灾region的stream-apply主机环境设置
Code部分:
##设置环境变量,请替换红色的文字部分为您实际的值
echo -e "DR_USERNAME="Your DR MongoDB User"\nexport DR_USERNAME\nDR_PASSWORD="Your DR MongoDB Password"\nexport DR_PASSWORD\nDR_mongo_host="Your DR MongoDB cluster URI"\nexport DR_mongo_host\nkfk_host="YOUR KFK URI\nexport kfk_host\nkfk_topic="changevents"\nexport kfk_topic \nDocuments_per_run=100000\nexport Documents_per_run" >> .bash_profile
##应用环境变量
source .bash_profile
容灾region的改变流应用程序
在stream-apply主机上部署下列python代码并运行
Python Code:
#!/bin/env python
import json
import logging
import os
import string
import sys
import time
import boto3
import datetime
from pymongo import MongoClient
from kafka import KafkaConsumer
db_client = None
kafka_client = None
"""ERROR level for deployment."""
logging.basicConfig(Level=logging.ERROR)
def get_db_client():
global db_client
if db_client is None:
logging.debug('Creating a new DB client.')
try:
username = os.environ[‘DR_USERNAME’]
password = os.environ[‘DR_PASSWORD’]
cluster_uri = os.environ[‘DR_mongo_host']
db_client = MongoClient(cluster_uri, ssl=True, retryWrites=False, ssl_ca_certs='/tmp/rds-combined-ca-bundle.pem')
# Make an attemp for connecting
db_client.admin.command('ismaster')
db_client["admin"].authenticate(name=username, password=password)
logging.debug('Successfully created a new DB client.')
except Exception as err:
logging.error('Failed to create a new DB client: {}'.format(err))
raise
return db_client
def conn_kfk_comsumer():
global kafka_client
if kafka_client is None:
logging.debug('Creating a new Kafka client.')
try:
kafka_client = KafkaConsumer(bootstrap_servers=os.environ['kfk_host'])
except Exception as err:
logging.error('Failed to create a new Kafka client: {}'.format(err))
raise
return kafka_client
def poll_msg(consumer, topic_name, key, value):
"""Poll documentdb changes from MSK."""
try:
topic_name = os.environ['kfk_topic']
consumer = KafkaConsumer(topic_name, bootstrap_servers= os.environ['kfk_host'], auto_offset_reset=‘latest’, group_id=‘docdb’, key_deserializer=lambda key: json.loads(key).decode('utf-8’), value_deserializer=lambda value: json.loads(value).decode('utf-8’))
consumer.subscribe(topic_name, key, value)
consumer.poll(max_records=1)
except Exception as err:
logging.error('Error in polling message: {}'.format(err))
raise
def apply2mongodb(message,db_client)
try:
# Kafka client set up
if "kfk_host" in os.environ:
kafka_client = conn_kfk_consumer()
logging.debug('Kafka client set up.')
db_client = get_db_client()
partition = KafkaConsumer.assignment()
next_offset = KafkaConsumer.position(partition)
if next_offset is None:
Time.sleep(0.5)
Continue
else:
poll_msg(kafka_client, kfk_topic, op_id, payload)
for message in consumer:
event_body = message.value()
op_type = json.loads(event_body[‘operation'])
if op_type == 'insert':
coll = json.loads(event_body['coll'])
coll_client = db_client(coll)
insert_body = json.loads(event_body[‘insert_body'])
payload = {'_id':ObjectId(json.loads(event_body['_id']))}
payload.update(insert_body)
coll_client.insert_one(payload)
if op_type == 'update':
coll = json.loads(event_body['coll'])
coll_client = db_client(coll)
update_body = json.loads(event_body[‘updateDescription']['updatedFields'])
update_set = {"$set":update_body}
payload = {'_id':(json.loads(event_body['_id']))}
coll_client.update_one(payload,update_set)
events_processed += 1
def main(event, context):
events_processed = 0
kafka_client = None
try:
# DocumentDB watched collection set up
db_client = get_db_client()
dr_db = os.environ['DR_mongo_host']
dr_db_client = db_client(dr_db)
while i < int(os.environ['Documents_per_run']):
apply2mongodb(message,dr_db_client)
i += 1
else:
if events_processed > 0:
logging.debug(' {} events been processed successfully'.format(events_processed))
return{
'statusCode': 200,
'description': 'Success',
'detail': json.dumps(str(events_processed)+ ' events processed successfully.')
}
else:
return{
'statusCode': 201,
'description': 'Success',
'detail': json.dumps('No records to process.')
}
finally:
# Close Kafka client
if "kfk_host" in os.environ:
kafka_client.close()
结果验证
1. 分别登陆主region与容灾region的DocumentDB
主region:
mongo --host $mongo_host:27017 --ssl --sslCAFile
/tmp/rds-combined-ca-bundle.pem --username $USERNAME --password $PASSWORD
容灾region:
mongo --host $DR_mongo_host:27017 --ssl --sslCAFile
/tmp/rds-combined-ca-bundle.pem --username $USERNAME --password $PASSWORD
2. 在主region插入数据
use bar;
db.foo.insertOne({
"x":1}) ;
3. 在灾备region观察
use bar;
db.foo.find();
##得到结果
{"_id":ObjectId(9416e4a253875177a816b3d6),"x":1}
3. 在主region更新数据
db.foo.updateOne({
"x":1},
{
$set:{"x":2}}
);
4. 在灾备region观察
db.foo.find();
##得到结果
{"_id":ObjectId(9416e4a253875177a816b3d6),"x":2}
5.在主region非监控表exa插入数据y=1
db.exa.insertOne({
"y":1});
6.在主region观察有哪些表,发现新增加了exa这张表
7. 在灾备region观察,并没有exa出现,因为exa并不在我们的watched collection里,不会捕捉相关的改变流
8. 在主region的foo表删除x记录
db.foo.deleteOne({
"x":2}) ;
##观察得到结果,主region DocumentDB foo表已被清空
db.foo.find();
##得到结果为空
9. 在灾备region验证foo表内容
db.foo.find();
##得到结果
{"_id":ObjectId(9416e4a253875177a816b3d6),"x":2}
##删除操作被拦截
10.下载S3中的文件,并打开,其中内容为
{"_id":"ObjectId(9416e4a253875177a816b3d6)", "operation":"delete", "timestamp":1658233222,"timestampReadable":"2022-07-19 20:20:22", "db":"bar","coll":"foo"}
##验证了本条delete命令被拦截并保存在S3中。
总结
我们在此文中,使用了MSK来异步保存DocumentDB的insert/update改变流,拦截delete类型的改变流存储在S3中备查。如果需要进一步对删除事件做出分析,可以引入Amazon Glue与Amazon Athena对存储于S3中的日志文件即席查询。MSK中的改变流事件,我们将其应用在灾备区域的DocumentDB,做到数据只增不减,避免主region的数据库因为意外误操作导致的数据损失或者高时间成本数据恢复操作。
参考资源
Amazon Linux 2 上使用 Boto 3 库创建 Python 3 虚拟环境
https://aws.amazon.com/cn/premiumsupport/knowledge-center/ec2-linux-python3-boto3/#:~:text=Install%20Python%203%20for%20Amazon%20Linux%202%201.,be%20required%20to%20create%20the%20Python%203%20environment
创建MSK的Topic
https://docs.aws.amazon.com/zh_cn/msk/latest/developerguide/create-topic.html
本篇作者