What’s the Difference Between ETL and ELT?
What’s the Difference Between ETL and ELT?
Extract, transform, and load (ETL) and extract, load, and transform (ELT) are two data-processing approaches for analytics. Large organizations have several hundred (or even thousands) of data sources from all aspects of their operations—like applications, sensors, IT infrastructure, and third-party partners. They have to filter, sort, and clean this large data volume to make it useful for analytics and business intelligence. The ETL approach uses a set of business rules to process data from several sources before centralized integration. The ELT approach loads data as it is and transforms it at a later stage, depending on the use case and analytics requirements. The ETL process requires more definition at the beginning. Analytics must be involved from the start to define target data types, structures, and relationships. Data scientists mainly use ETL to load legacy databases in the data warehouse, while ELT has become the norm today.
What are the similarities between ETL and ELT?
Both extract, transform, and load (ETL) and extract, load, and transform (ELT) are sequences of processes that prepare data for further analysis. They capture, process, and load data for analysis across three steps.
Extraction
Extraction is the first step of both ETL and ELT. This step is about collecting raw data from different sources. These could be databases, files, software as a service (SaaS) applications, Internet of Things (IoT) sensors, or application events. You can collect semi-structured, structured, or unstructured data at this stage.
Transformation
In the ETL process, transformation is the second step, while in ELT it is the third. This step focuses on changing raw data from its original structure into a format that meets the requirements of the target system where you plan to store the data for analytics. Here are some examples of transformation:
- Changing data types or formats
- Removing inconsistent or inaccurate data.
- Removing data duplication.
You apply rules and functions to clean and prepare data for analysis in the target system.
Load
In this phase, you store data into the target database. ETL processes load data as a final step, so that reporting tools can use it directly to generate actionable reports and insights. However, in ELT, you still need to transform the extracted data after loading it.
How do the ELT and ETL processes differ from each other?
Next, we outline the processes of extract, transform, and load (ETL) and extract, load, and transform (ELT). You can also read some historical background.
ETL process
ETL has three steps:
- You extract raw data from various sources
- You use a secondary processing server to transform that data
- You load that data into a target database
The transformation stage ensures compliance with the target database’s structural requirements. You only move the data once it is transformed and ready.
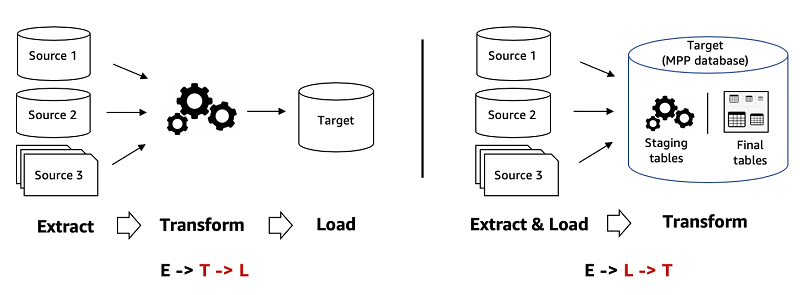
ELT process
These are the three steps of ELT:
- You extract raw data from various sources
- You load it in its natural state into a data warehouse or data lake
- You transform it as needed while in the target system
With ELT, all data cleansing, transformation, and enrichment occur within the data warehouse. You can interact with and transform the raw data as many times as needed.
History of ETL and ELT
ETL has been around since the 1970s, becoming especially popular with the rise of data warehouses. However, traditional data warehouses required custom ETL processes for each data source.
The evolution of cloud technologies changed what was possible. Companies could now store unlimited raw data at scale and analyze it later as required. ELT became the modern data integration method for efficient analytics.
Key differences: ETL vs. ELT
Extract, load, and transform (ELT) has improved extract, transform, and load (ETL) in several ways.
Transform and load location
Transformation and load occur in different locations and use distinct processes. The ETL process transforms data on a secondary processing server.
In contrast, the ELT process loads raw data directly into the target data warehouse. Once there, you can transform the data whenever you need it.
Data compatibility
ETL is best suited for structured data that you can represent in tables with rows and columns. It transforms one set of structured data into another structured format and then loads it.
In contrast, ELT handles all types of data, including unstructured data like images or documents that you can’t store in tabular format. With ELT, the process loads the various data formats into the target data warehouse. From there, you can transform it further into the format you require.
Speed
ELT is faster than ETL. ETL has an additional step before it loads data into the target that is difficult to scale and slows the system down as data size increases.
In contrast, ELT loads data directly into the destination system and transforms it in parallel. It uses the processing power and parallelization that cloud data warehouses offer to deliver real-time or near real-time data transformation for analytics.
Costs
The ETL process requires analytics involvement from the start. It needs analysts to plan ahead on the reports they want to generate and define data structures and formatting. The time required for setup increases, which adds to costs. Additional server infrastructure for transformations may also cost more.
ELT has fewer systems than ETL, as all transformations occur within the target data warehouse. With fewer systems, there is less to maintain, leading to a simpler data stack and lower setup costs.
Security
When you work with personal data, you must comply with data privacy regulations. Companies must protect personally identifiable information (PII) from unauthorized access.
In ETL, developers have to build custom solutions, like masking PII to monitor and protect data.
On the other hand, ELT solutions provide many security features—like granular access control and multifactor authentication—directly within the data warehouse. You can invest more time in analytics and less time meeting data regulation requirements.
When to use ETL vs. ELT
Extract, load, and transform (ELT) is the standard choice for modern analytics. However, you might consider extract, transform, and load (ETL) in the following scenarios.
Legacy databases
It is sometimes more beneficial to use ETL to integrate with legacy databases or third-party data sources with predetermined data formats. You only have to transform and load it once into your system. Once transformed, you can use it more efficiently for all future analytics.
Experimentation
In large organizations, data engineers conduct experiments—things like discovering hidden data sources for analytics and trying out new ideas to answer business queries. ETL is useful in data experiments to understand the database and its usefulness in a particular scenario.
Complex analytics
ETL and ELT may both be used together for complex analytics that use multiple data formats from varied sources. Data scientists may set up ETL pipelines from some of the sources and use ELT with the rest. This improves analytics efficiency and increases application performance in some cases.
IoT applications
Internet of Things (IoT) applications that use sensor data streams often benefit from ETL over ELT. For examples, here are some common use cases for ETL at the edge:
- You want to receive data from different protocols and convert it into standard data formats for use in cloud workloads
- You want to filter high-frequency data, perform averaging functions on large datasets, then load averaged or filtered values at a reduced rate
- You want to calculate values from disparate data sources on the local device, and send filtered values to the cloud backend
- You want to cleanse, deduplicate, or fill missing time series data elements
Summary of differences: ETL vs. ELT
| Category |
ETL |
ELT |
|
Stands for |
Extract, transform, and load |
Extract, load, and transform |
|
Process |
Takes raw data, transforms it into a predetermined format, then loads it into the target data warehouse. |
Takes raw data, loads it into the target data warehouse, then transforms it just before analytics. |
|
Transformation and load locations |
Transformation occurs in a secondary processing server. |
Transformation takes place in the target data warehouse. |
|
Data compatibility |
Best with structured data. |
Can handle structured, unstructured, and semi-structured data. |
|
Speed |
ETL is slower than ELT. |
ELT is faster than ETL as it can use the internal resources of the data warehouse. |
|
Costs |
Can be time-consuming and costly to set up depending on ETL tools used. |
More cost-efficient depending on the ELT infrastructure used. |
|
Security |
May require building custom applications to meet data protection requirements. |
You can use built-in features of the target database to manage data protection. |
How can AWS support your ETL and ELT requirements?
Analytics on AWS describes the broad selection of analytics services from Amazon Web Services (AWS) that fit all your data analytics needs. With AWS, organizations of all sizes and industries can reinvent their business with data.
Here are some of the AWS services you can use for your ETL and ELT requirements:
- Amazon Aurora supports zero-ETL integration with Amazon Redshift. This integration enables near real-time analytics and machine learning through Amazon Redshift on petabytes (PB) of transactional data from Aurora.
- AWS Glue is a serverless data integration service for event-driven ETL and no-code ETL jobs.
- AWS IoT Greengrass supports your ETL on edge use cases by bringing cloud processing and logic locally to edge devices.
- Amazon Redshift allows you to set up all ELT workflows and directly query datasets from different sources.
Get started with ELT and ETL on AWS by creating a free account today.
Browse all cloud computing concepts
Browse all cloud computing concepts content here:
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages