Qual è la differenza tra data science e intelligenza artificiale?
Qual è la differenza tra data science e intelligenza artificiale?
Data science e intelligenza artificiale (IA) sono termini generici per metodi e tecniche relativi alla comprensione e all'utilizzo dei dati digitali. Le organizzazioni moderne raccolgono informazioni da una serie di sistemi online e fisici su ogni aspetto della vita umana. Disponiamo di dati di testo, audio, video e immagini in grandi quantità. La data science combina strumenti, metodi e tecnologie statistici per generare significato dai dati. L'intelligenza artificiale fa un ulteriore passo avanti e utilizza i dati per risolvere i problemi cognitivi comunemente associati all'intelligenza umana, come l'apprendimento, il riconoscimento di schemi e l'espressione simile a quella umana. È una raccolta di algoritmi complessi che "apprendono" man mano che procedono, migliorando nel tempo la risoluzione dei problemi.
Somiglianze tra data science e intelligenza artificiale
Sia l'intelligenza artificiale che la data science comprendono strumenti, tecniche e algoritmi per analizzare e utilizzare grandi volumi di dati. Di seguito sono riportate alcune somiglianze.
Applicazioni predittive
Sia l'intelligenza artificiale che le tecnologie di data science effettuano previsioni basate su nuovi dati, come risultato dell'applicazione di modelli e metodi appresi nell'analisi di dati precedenti. La previsione delle vendite mensili future di ombrelli, basata sui dati degli anni precedenti, è un esempio di analisi delle serie temporali nell'ambito di data science.
Analogamente, un'auto a guida autonoma è un esempio di sistema di intelligenza artificiale predittiva. Quando un'auto a guida autonoma è su strada, calcola la distanza di quella che la precede e la velocità di entrambe. In base alla previsione della frenata improvvisa dell'auto che la precede, mantiene una velocità tale da evitare un incidente.
Requisiti di qualità dei dati
Sia la tecnologia dell'IA che quella della data science danno risultati meno accurati se i dati di addestramento sono inconsistenti, distorti o incompleti. Ad esempio, gli algoritmi di data science e l'intelligenza artificiale possono:
- filtrare i nuovi dati se sono del tutto nuovi e non fanno parte del loro set di dati originale,
- dare priorità a specifici attributi del set di dati rispetto agli altri se i dati di input mancavano di variazioni,
- creare informazioni inesistenti o fittizie perché i dati di input erano falsi.
Machine learning
Il machine learning (ML) è considerato un sottotipo sia di data science che dell'intelligenza artificiale. Ciò significa che tutti i modelli ML sono considerati modelli di data science e tutti gli algoritmi di ML sono considerati anche algoritmi di intelligenza artificiale. È diffusa l'idea errata che tutta l'IA utilizzi il ML, ma non è così. Il machine learning non è sempre necessario nelle soluzioni di intelligenza artificiale complesse. Analogamente, non tutte le soluzioni di data science prevedono l'utilizzo di ML.
Differenze principali tra data science e intelligenza artificiale
La data science comporta l'analisi dei dati per determinare i modelli sottostanti e i punti di interesse per fare previsioni. La data science applicata prende i modelli e i metodi utilizzati nell'analisi dei dati e li applica ai nuovi dati in situazioni reali per fornire output probabilistici. L'intelligenza artificiale, invece, utilizza tecniche di data science applicata e altri algoritmi per assemblare ed eseguire sistemi complessi basati su macchine che si avvicinano all'intelligenza umana.
La data science può essere utilizzata anche in applicazioni diverse dall'intelligenza artificiale e dall'informatica.
Obiettivi
L'obiettivo della data science è quello di applicare modelli e metodi statistici e computazionali esistenti per comprendere i punti di interesse o i modelli nei dati raccolti. I risultati sono predeterminati e facili da definire sin dall'inizio. Ad esempio, è possibile utilizzare i dati per prevedere le vendite future o identificare quando un macchinario è pronto per la riparazione.
L'obiettivo dell'intelligenza artificiale è di utilizzare i computer per ottenere un risultato da nuovi dati complessi che non sia distinguibile dal ragionamento umano intelligente. I risultati sono generici e difficili da definire, come ad esempio, generare un testo creativo o generare immagini da un testo. I particolari dell'insieme di problemi sono troppo ampi per essere definiti con precisione e il sistema di intelligenza artificiale interpreta il problema in modo autonomo.
Ambito
La data science ha un ambito più limitato in quanto il risultato è predeterminato. Il processo inizia identificando le domande a cui si può rispondere con i dati. L'ambito comprende:
- raccolta e pre-elaborazione dei dati,
- applicazione di modelli e algoritmi appropriati ai dati per rispondere a queste domande,
- interpretazione dei risultati.
L'intelligenza artificiale, invece, ha un campo di applicazione molto più ampio e i passaggi variano in base al problema da risolvere. Il processo inizia identificando un'attività manuale ad alta intensità di lavoro o un'attività di ragionamento complessa che gli esseri umani svolgono efficacemente e che si desidera che la macchina replichi. L'ambito può includere:
- analisi esplorativa dei dati,
- suddivisione dell'attività in componenti algoritmiche per creare un sistema,
- raccolta di dati di prova per esaminare e perfezionare la coerenza del flusso logico e la complessità del sistema,
- test del sistema.

Metodi
La data science dispone di una vasta gamma di tecniche per la modellazione dei dati. La scelta della tecnica corretta dipende dai dati e dalla domanda posta. Questi includono la regressione lineare, la regressione logistica, il rilevamento di anomalie, la classificazione binaria, il clustering k-means, l'analisi delle componenti principali e molti altri. L'analisi statistica applicata in modo errato darà risultati imprevisti.
Le applicazioni di intelligenza artificiale si basano in genere su componenti complessi, precostruiti e prodotti. Questi possono includere il riconoscimento facciale, l'elaborazione del linguaggio naturale, l'apprendimento per rinforzo, i grafi della conoscenza, l'intelligenza artificiale generativa (IA generativa) e molti altri.
Applicazioni: data science e intelligenza artificiale
La data science può essere applicata ovunque vi siano dati di qualità sufficiente e un modello per assistere nella risposta a una domanda specifica. Le applicazioni includono:
- Previsioni della domanda di vendita.
- Rilevamento frodi.
- Quote sportive.
- Valutazione dei rischi.
- Previsione dei consumi energetici.
- Ottimizzazione dei ricavi.
- Processi di screening dei candidati.
Le applicazioni dell'IA sono praticamente infinite. Le applicazioni più diffuse comprendono:
- Linee di produzione robotizzate.
- Chatbot.
- Sistemi di riconoscimento biometrico.
- Analisi di diagnostica per immagini.
- Manutenzione predittiva.
- Pianificazione urbana.
- Personalizzazione del marketing.
Carriere: data science e intelligenza artificiale
L'obiettivo principale di un data scientist è generalmente tecnico, lavorando a fondo sui dati. I data scientist possono lavorare sulla raccolta e l'elaborazione dei dati, sulla scelta dei modelli giusti per i dati e sull'interpretazione dei risultati per formulare suggerimenti. Il lavoro può svolgersi all'interno di software o sistemi specifici o persino nella costruzione dei sistemi stessi.
Tipi di ruoli
I ruoli nell'ambito della data science includono data scientist, data analyst, data engineer, ingegnere per il machine learning, research scientist, data visualization specialist, ruoli di analisti specifici del settore e altro ancora. L'intelligenza artificiale comprende anche tutti questi ruoli. Tuttavia, visto che si tratta di un ambito così ampio, ci sono molti altri ruoli e aree di interesse associati, come sviluppatore di software, product manager, marketing specialist, AI tester, AI engineer e altro ancora.
Competenze
I data scientist hanno competenze nell'applicazione pratica di metodi statistici e algoritmici per qualificare e analizzare i dati per trovare informazioni dettagliate rilevanti. I data scientist necessitano di una formazione in matematica statistica e informatica e una conoscenza approfondita negli strumenti applicabili.
A seconda del ruolo ricoperto nell'ambito dell'intelligenza artificiale, le competenze richieste possono essere più tecniche o trasversali. In alcuni ruoli potrebbe non essere richiesta alcuna esperienza tecnica. Ad esempio, uno sviluppatore di software di intelligenza artificiale avrebbe bisogno di conoscenze pratiche dei linguaggi di programmazione, delle librerie e degli strumenti pertinenti. Tuttavia, un AI tester per uno strumento di IA generativa avrebbe bisogno di competenze linguistiche, pensiero creativo e dovrebbe comprendere le possibili interazioni degli utenti con il sistema.
Avanzamento di carriera
Con il progressivo aumento dell'automazione e della produzione di strumenti e flussi di lavoro per la data science, il numero di ruoli nel campo diminuisce. I professionisti della data science che cercano ruoli prettamente legati a tale ambito tendono ad orientarsi verso applicazioni accademiche e all'avanguardia. I ruoli di analista, che prevedono che il data scientist si occupi del funzionamento degli strumenti, restano rilevanti. Partendo da un ruolo junior, i data scientist raggiungono posizioni senior, passando alla gestione delle persone o dei progetti, fino ad arrivare al ruolo di chief data officer.
A seconda dell'obiettivo del ruolo stesso dell'IA, ci si può aspettare un simile avanzamento di carriera. Si può passare a chief technology officer, chief marketing officer, chief product officer e così via. Pensare in modo critico a quali lavori saranno automatizzati nei prossimi dieci anni può aiutare a preparare il futuro della propria carriera.
Sintesi delle differenze: data science a confronto con l'intelligenza artificiale
|
Data science |
Intelligenza artificiale |
|
|
Di che cosa si tratta? |
L'impiego di modelli statistici e algoritmici per ottenere informazioni dettagliate dai dati. |
Un termine generico per applicazioni basate su macchine che imitano l'intelligenza umana. |
|
Ideale per |
Rispondere a una domanda a partire da un set di dati. |
Completare un'attività umana complessa con una certa efficienza. |
|
Metodi |
Regressione lineare, regressione logistica, rilevamento delle anomalie, classificazione binaria, clustering k-means, analisi dei componenti principali e altro ancora. |
Riconoscimento facciale, elaborazione del linguaggio naturale, apprendimento per rinforzo, grafi della conoscenza, IA generativa e altro ancora. |
|
Ambito |
Domande predefinite a cui è possibile rispondere a partire dai dati. |
Ampio e difficile da definire - basato sulle attività. |
|
Implementazione |
Utilizza una gamma di strumenti diversi per acquisire, pulire, modellare, analizzare e produrre report sui dati. |
In base all'attività. In genere si basa su componenti complessi, precostituiti e prodotti. |
In che modo AWS può aiutarti con i requisiti di data science e intelligenza artificiale?
AWS offre una gamma completa di prodotti e servizi di data science e IA progettati per aiutarti a rafforzare e far crescere l'analisi e l'intelligence dei dati aziendali e individuali.
Ciò include modelli di data science e IA basati su API per dati strutturati e non strutturati e ambienti completamente gestiti che forniscono la creazione e l'implementazione end-to-end di soluzioni di data science e IA.
- Amazon SageMaker Studio è un ambiente di sviluppo integrato (IDE) che include uno stack di strumenti appositamente creato per lo sviluppo di soluzioni di data science e ML.
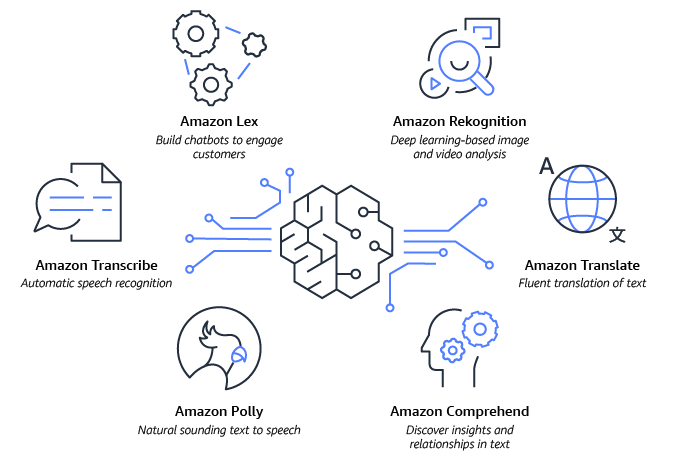
- Amazon Lex aiuta a creare chatbot con l'IA conversazionale.
- Amazon Rekognition offre funzionalità di visione artificiale (CV) preaddestrate e personalizzabili per estrarre informazioni e approfondimenti da immagini e video.
- Amazon Comprehend aiuta a ricavare e comprendere informazioni preziose dal testo contenuto nei documenti.
- Amazon Personalize sfrutta il ML per aiutare a personalizzare l'esperienza del cliente.
- Amazon Forecast aiuta a eseguire previsioni di serie temporali.
- Amazon Fraud Detector aiuta a creare, implementare e gestire modelli di rilevamento delle frodi.
Inoltre, AWS offre un elenco crescente di soluzioni di IA generativa all’avanguardia in grado di creare nuovi contenuti e idee, tra cui conversazioni, storie, immagini, video e musica. Le soluzioni di IA generativa includono:
- Amazon Bedrock che aiuta le organizzazioni a creare e dimensionare soluzioni di IA generativa.
- AWS Trainium che aiuta ad addestrare i modelli di IA generativa più velocemente.
- Amazon Q Developer che è un assistente basato sull'IA generativa per lo sviluppo di software.
Inizia subito a utilizzare data science e intelligenza artificiale su AWS creando un account.
Browse all cloud computing concepts
Browse all cloud computing concepts content here:
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages