Fraud Graphs on AWS
Build a fraud graph in Amazon Neptune to efficiently use relationships to automate fraud detection in real-time
What is a fraud graph?
Globally each year, organizations lose tens of billions of dollars to fraud. Fraud can be carried out by a single bad actor, or a network of participants using multiple identities colluding with each other for transactions with business institutions. Multiple people can collude to commit fraudulent transactions, creating fraud rings, which may have hundreds of members, making it challenging to find the bad actors and detect fraud. Transactional data, for example credit card transactions, has basic attribute information, but does not include the relationships such as those between people, shared addresses, and others. This makes it hard to identify fraud that is committed by groups of coordinated actors or by a single actor over time.
A fraud graph stores the relationships between the transactions, actors, and other relevant information to enable customers to find common patterns in the data and build applications that can detect fraudulent activities. Using a fraud graph, organizations can identify a network of connected users and items such as e-mail accounts, addresses, and phone numbers that they have in common. This results in a highly connected and complex network of information, which can be queried, visualized, and analyzed to detect fraud. Fraud graphs are complementary to other techniques used to detect fraud, for example using Machine Learning models to identify potentially fraudulent transactions, and querying a fraud graph about the actors related to the transactions.
You can build your fraud graph solution using Amazon Neptune, a fast, reliable, fully managed graph database service.
Why use a graph database to build a fraud graph?
Relational databases, built for storing and analyzing tabular data, are not efficient at storing and querying the relationships between billions of interconnected entities where you need to explore and visualize connections and groups within the data. Using a relational database to query large relationships can be complex, where using SQL to query the database can result in multiple complex joins leading to poor performance.
Graph databases, which are purpose-built to store and navigate relationships, and their query languages, are designed to work with data that is highly connected, making querying the data for patterns and connections simple, fast, and reliable. Graph databases treat relationships as “first-class citizens,” have flexible schema, and provide higher performance for graph query traversals. This makes graph databases capable of sophisticated fraud detection and prevention. With graph database, you can model relationships between people, places, and financial transactions in real time and discover additional relationships that may not be obvious.
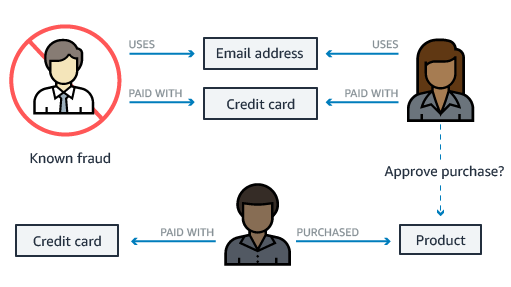
Sample fraud detection use case involving bad actors
Examples of using graphs to detect fraud
Credit card fraud
Credit card fraud can occur in many ways. Fraudsters can obtain card details of people and use them for unauthorized transactions, or create synthetic identities to get multiple cards and max them out (bust-out fraud) after seemingly normal behavior. Graph applications can be used to prevent counterfeit credit card transactions by identifying common links between card holders, point of sale locations, transactions and terminals. Identifying these links in a vast network of data points can expose compromised cards which can then be blocked to prevent fraud.
Insurance fraud
Insurance companies want to identify fake claims which could slip under the radar when looking at claims in isolation. A graph application can be used to find links between claims and the people associated with each claim. This can expose fraud rings where a network of fraudsters file multiple claims, play different roles, or be involved in multiple small claims. Graphs can also be used to detect under or misrepresented data in an insurance policy based on previously known customer profile and relationships with other people and claims.
Loan fraud
Bad actors can attempt to secure a loan for fraudulent purposes. Graph databases can explore the network of people and things connected with a person to a significant enough depth looking for any connection with other known bad actors. If such a connection is found, the loan approval applications can be flag the loan application so that banks can assess the risk and decide whether or not to approve the loan.
Online betting fraud
Fraudsters may create multiple accounts in online betting platforms, known as ‘Gnoming’. They can use these accounts to pocket the signup bonus and never play, or bet against themselves to ensure they win. A fraud graph can identify the relationships among people, e-mail accounts, IP addresses, phone numbers or postal addresses. By finding common contact information, online betting platforms can prevent gnoming.
Anti-Money Laundering (AML)
The term “money laundering” can be defined many ways but it describes the process where illegally obtained funds are passed through various entities such that the origin of the funds is hard to trace and thus the money becomes “laundered” and appears to be legitimate income.Graph databases can help in tracking financial transactions through complex networks to provide a clear picture of the path the money took from its source to its destination.
Online gaming fraud
Collusion occurs when two or more players work together to affect the outcome of a game. In online gambling, self-collusion is also possible. Self-collusion is where a person signs up for multiple accounts and plays simultaneously colluding with themselves. Graphs can be used to determine if a person has already signed up for a game by detecting common data points such as phone numbers or IP addresses.
Using Amazon Neptune to build a fraud graph
Amazon Neptune is a fast, reliable, fully managed graph database service that makes it easy to build and run applications that work with highly connected datasets. Amazon Neptune is purpose-built for storing billions of relationships and querying the graph with milliseconds latency. Amazon Neptune is compatible with open graph APIs, and supports popular graph models Property Graph and W3C's RDF, and their respective query languages Apache TinkerPop Gremlin and SPARQL. While graph databases usually require extensive hardware management, provisioning, and manual scaling, Amazon Neptune is a fully managed services, so you no longer have to worry about database management tasks. You can be up and running with an Amazon Neptune graph cluster in a matter of minutes, with a few clicks in the AWS Management Console or API calls. With Amazon Neptune, you can query relationships in near real time to easily detect fraud patterns. Neptune provides a fully managed service to execute fast graph queries to detect fraud scenarios such as loan fraud, credit card fraud, AML,and online gaming fraud.
You can load data directly into Neptune using query APIs, or from relational databases using AWS Database Migration Service. Neptune also supports bulk loading data from Amazon S3. Neptune can then be used in conjunction with Amazon SageMaker to train machine learning models for predictions in fraud detection.

Benefits of Amazon Neptune for fraud graphs
Highly scalable and available
With Amazon Neptune, you can scale the compute and memory resources powering your production graph cluster up or down by creating new replica instances of the desired size, or by removing instances. Based on your database usage, your Amazon Neptune storage will automatically grow up to 64TB, in 10GB increments, with no impact to database performance. There is no need to provision storage in advance. Amazon Neptune is highly available, with read replicas, point-in-time recovery, continuous backup, and replication across Availability Zones (AZs).
Cost-effective
Amazon Neptune reduces the cost of managing your graph database by eliminating the need for hardware and software investments and reducing operational burden. A fraud graph built on Amazon Neptune will enable you to build a cost-effective, scalable, secure, and highly available solution.
Secure, privacy-compliant
Amazon Neptune is secure by default, with support for encryption-at-transit and encryption-at-rest using AWS Customer Managed Keys. Amazon Neptune is in scope for PCI, DSS, and ISO compliance programs, and is SOC 1, 2, and 3 compliant, so you build fraud detection solutions that comply with regulatory requirements. For more information, read the Neptune user guide.
Customers
PaySense is a digital lending startup specializing in using advanced data sciences to provide credit without the hassle of complex application processes, arduous physical proofs and long waits. PaySense unique model establishes billions of relationships between millions of people. PaySense has been an early customer since the launch of Amazon Neptune to store this model. The graph database is used to detect fraud rings that look for abnormal growth rates in certain parts of the graph.
Using Amazon Neptune, Rappi was able to use Neptune for their fraud detection solution, replace their 3rd party solution and bring down their overall cost significantly.
Getting started
AWS Graph Notebook: Introduction to Fraud Graphs
The easiest way to get started with fraud graphs on Amazon Neptune is to use the AWS Graph Notebook. Learn how to create a fraud detection solution and identify patterns such as fraud rings and identity theft with this sample application notebook. To follow along the sample application and run interactive queries, you will need to create an Amazon Neptune cluster and Neptune notebook. This sample application and other examples are pre-loaded into every Neptune notebook.
Get started with Amazon Neptune, a fully managed graph database
Amazon Neptune is a fast, reliable, fully managed graph database service that makes it easy to build and run applications that work with highly connected datasets. The core of Amazon Neptune is a purpose-built, high-performance graph database engine optimized for storing billions of relationships and querying the graph with milliseconds latency. Amazon Neptune supports popular graph models Property Graph and W3C's RDF, and their respective query languages Apache TinkerPop Gremlin and SPARQL, allowing you to easily build queries that efficiently navigate highly connected datasets. Neptune powers graph use cases such as recommendation engines, fraud detection, knowledge graphs, drug discovery, and network security.