Amazon Web Services ブログ
Python ツールボックスを使用して Amazon Lookout for Equipment モデルを構築、トレーニング、デプロイする
このブログは2022年2月23日に Vikesh Pandey、Ioan CATANA と Michaël Hoarau によって執筆された内容を日本語化したものです。
予知保全は、産業機器の状態を連続監視して、機器の故障の予兆を検知し、故障する前に警告を出すことで、産業機器の故障や費用のかかるダウンタイムを防止する効果的な方法です。予知保全ソリューションを実現するためには、センサーとインフラストラクチャを用意して、データ収集、保存、分析、警告の機能を実装する必要があります。しかし、追加のインフラストラクチャを設置しても、多くの企業は基本的なデータ分析とシンプルな AI モデルしか採用できず、ダウンタイムを回避できるほど、早期に故障の予兆を検知できないことがよくあります。産業機器向けに、機械学習 (ML) ソリューションを実装することは困難であり、時間のかかる作業です。
Amazon Lookout for Equipment を使用することで、機械学習の経験がなくても、産業機器のセンサーデータを自動的に分析し、機器の異常動作を検出できます。機器の異常を迅速かつ正確に検出し、問題を診断することにより、費用のかかるダウンタイムを削減できます。
Lookout for Equipment は、圧力、流量、回転速度、温度、電力など、センサーやシステムからのデータを分析し、データに基づいて、産業機器の AI モデルを自動的にトレーニングします。独自の機械学習モデルを使用して、センサーデータをリアルタイムで分析し、機器の故障につながる可能性のある兆候を特定し、早期にアラートを出せます。Lookout for Equipment は、検出されたアラートごとに、問題のセンサーと影響度を特定できます。
機械学習をすべての開発者の手に届くという使命のもとに、Lookout for Equipment にもう 1 つのアドオンを提供します。これは、開発者やデータサイエンティストが 、Amazon SageMaker と類似する方法で、 Lookout for Equipment を構築、トレーニング、デプロイできる オープンソースの Python ツールボックス です。このライブラリは Lookout for Equipment boto3 python API のラッパーであり、初めてこのサービスを利用する方に高度な機能を提供します。改善の提案やバグがある場合、ツールボックスの GitHub リポジトリ に対して問題を報告してください。
この記事では、SageMaker ノートブック内から Lookout for Equipment オープンソース Python ツールボックスを使用するためのステップバイステップのガイドを提供します。
環境設定
SageMaker ノートブックからオープンソースの Lookout for Equipment ツールボックスを使用するには、SageMaker ノートブックに Lookout for Equipment API を呼び出すために必要な権限を付与する必要があります。この記事では、SageMaker ノートブックインスタンスがすでに作成されていることを前提とします。詳細の手順については、Amazon SageMaker ノートブックインスタンスの使用を開始する を参照してください。ノートブックインスタンスは自動的に実行ロールと関連付けられます。
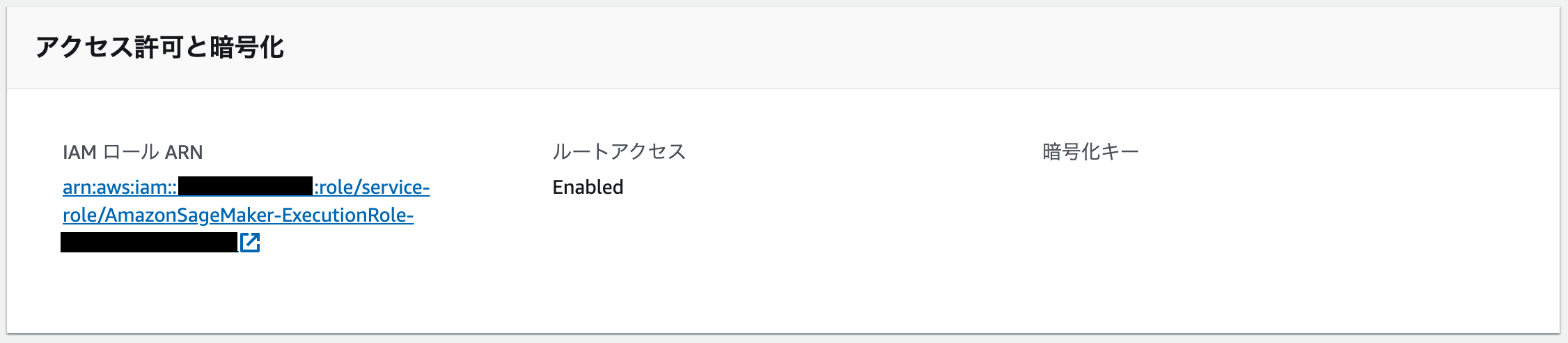
- SageMaker コンソールからインスタンスを選択し、インスタンスにアタッチされているロールを確認します。

- 次の画面で、アクセス権限と暗号化 のセクションで、インスタンスにアタッチされている AWS Identity and Access Management (IAM) のロールを確認します。
- ロールを選択して IAM コンソールを開きます。
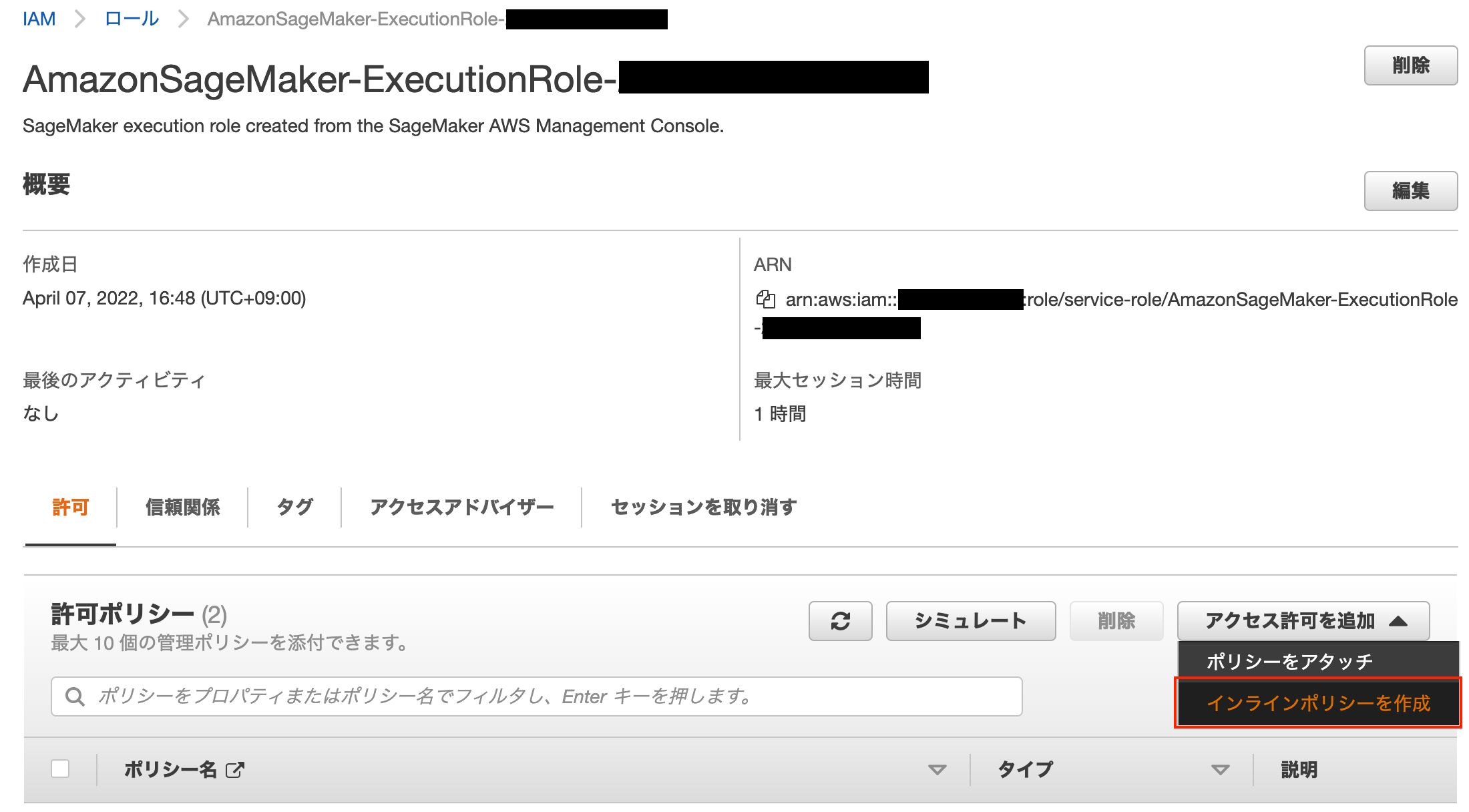
次は、SageMaker IAM ロールにインラインポリシーをアタッチします。
- 開いたロールの 許可 タブの アクセス許可を追加 で、インラインポリシーを作成 を選択します。
- JSON タブで、次のコードを入力します。デモの目的で、サービスにワイルドカードアクション (
lookoutequipment: *) を使用しています。実際使う場合、対象 SDK API を実行するために必要な権限のみを付与してください。 - ポリシーの確認 を選択します。
- ポリシーの名前を指定して、ポリシーを作成します。
前述のインラインポリシーに加えて、Lookout for Equipment がこのロールを引き受けることができるように信頼関係を設定する必要があります。SageMaker が作成したロールには、Amazon Simple Storage Service (Amazon S3) への適切なデータアクセス権がすでにあります。Lookout for Equipment がこのロールを引き受けることを許可すると、ノートブックと同じデータへのアクセス権が付与されます。ご使用の環境で、Lookout for Equipment がデータにアクセスできるロールを既に使用している場合、ロールの信頼関係を調整する必要はありません。
- SageMaker が作成した IAM ロールの 信頼関係 タブで、信頼ポリシーを編集 を選択します。
- ポリシー全体を次のコードに置き換えます:
- ポリシーを更新 を選択します。
これで、SageMaker ノートブック環境で Lookout for Equipment ツールボックスを使用する準備が整いました。Lookout for Equipment ツールボックスはオープンソースの Python パッケージで、データサイエンティストやソフトウェア開発者は、Lookout for Equipment を使用して時系列異常検出モデルを簡単に構築してデプロイできます。ツールボックスを利用して、どのようにより簡単に構築できるかを見てみましょう!
依存関係
このブログを執筆した時点では、下記のミドルウェアがインストールされている必要があります。
※1. Python 3.6 は EOL のため、3.6 以後のバージョンを推奨します。
これらの依存関係を満たしたら、 Jupyter ターミナルから次のコマンドを実行して Lookout for Equipment ツールボックスをインストールして起動できます。
これで、ツールボックスが使用可能になりました。このブログは、異常検出のモデルをトレーニングからデプロイするまで、ツールボックスの使用方法を示します。一般的な ML 開発のライフサイクルは、データセットの作成、モデルのトレーニング、モデルのデプロイ、モデルに対する推論の実行で構成されます。このツールボックは様々な機能を提供していますが、このブログでは以下の機能にフォーカスして紹介します。
- データセットを準備する
- Lookout for Equipment を使用して異常検出のモデルをトレーニングする
- モデルを評価するための可視化を作成する
- 推論用のスケジューラを作成して起動する
- スケジューラの推論結果の可視化を作成する
これらの機能に対して、ツールボックスをどう使うかを見てみましょう。
データセットを準備する
Lookout for Equipment を使用するためには、データセットを作成して取り込む必要があります。次の手順でデータセットを準備します。
- データセットを作成する前に、サンプルデータセットをロードして Amazon Simple Storage Service (Amazon S3) のバケットにアップロードする必要があります。このブログでは、
expanderのデータセットを使用します。
取得した data オブジェクトには、以下のような辞書オブジェクトを含まれています。
-
- トレーニングデータの DataFrame
- ラベルの DataFrame
- トレーニングの開始日時と終了日時
- 評価の開始日時と終了日時
- タグの説明の DataFrame
実際のデータを使うとき、同じ構成の辞書オブジェクトを作成してください。
トレーニングデータとラベルデータは、ターゲットディレクトリから作業の Amazon S3 のバケット/プレフィックスの場所にアップロードします。
- S3 にデータセットをアップロードした後、データセットを管理するための
LookoutEquipmentDatasetクラスのオブジェクトを作成します。
access_role_arn は、データを保存する S3 バケットにアクセスするために必要な権限です。前の 環境設定 セクションから SageMaker ノートブックインスタンスのロールの ARN を取得し、IAM ポリシーを追加して S3 バケットへのアクセスを許可します。詳細については、IAM ポリシーの記述 : Amazon S3 バケットへのアクセスを許可する方法 を参照してください。
component_root_dir は、トレーニングデータが保存されている Amazon S3 バケットとプレフィックスです。
前述の API を起動すると、データセットが作成されます。
- データをデータセットに取り込みます。
対象 Amazon S3 上のデータが利用可能になりました。 3 行のコードだけで、データセットの作成、データの取り込みを実装できました。長い JSON スキーマを手動で作成する必要はありません。ツールボックスがファイル構造を検出し、自動的に作成します。データを取り込んだら、次のトレーニングに移りましょう!
異常検出のモデルをトレーニングする
データセットにデータが取り込まれたら、モデルをトレーニングするプロセスを開始できます。次のコードを参照してください。
トレーニングを開始する前に、データセット内でトレーニング期間と評価期間を指定する必要があります。また、ラベルデータの Amazon S3 を設定し、サンプリングレートを 5 分に設定します。トレーニング開始後、poll_model_training を実行すると、トレーニングが成功するまで、 5 分ごとにトレーニングジョブのステータスを出力します。
Lookout for Equipment ツールボックスのトレーニングモジュールを使用することで、10 行未満のコードでモデルをトレーニングできます。ユーザーに代わって、ローレベル API で必要となるリクエスト文字列がすべて自動的に生成するため、長くてエラーが発生しやすい JSON ドキュメントを作成する必要がなくなります。
モデルのトレーニングが完了したら、評価期間中の結果を確認できます。またはツールボックスを使用して推論スケジューラーを作成できます。
トレーニング済みモデルを評価する
モデルがトレーニングされると、Lookout for Equipment の DescribeModel API により、トレーニングに関連するメトリクスが生成されます。この API は、評価結果をプロットするための 2 つのフィールド、labeled_ranges と predicted_ranges を含む JSON オブジェクトを取得します。これらのフィールドには、評価範囲内の既知の異常値と予測された異常値が含まれています。さらに、JSON オブジェクトが、ツールボックスのユーティリティにより、 Pandas の DataFrame に変換されます。
DataFrame に変換される利点は、ツールボックスの TimeSeriesVisualization クラスを使用して、元の時系列信号の 1 つをラベル付きでプロットし、予測された異常イベントのオーバーレイを追加することで、わかりやすいグラフを作成できることです。
この数行のコードにより、次の特徴を持つプロットが生成されます:
- 選択された元の時系列の信号のラインプロット(モデルをトレーニングした時に使用された部分は青、評価の部分は灰色)
- ローリング平均は、時系列上に重ねられた細い赤い線として表示される
- 入力したラベルは「Known anomalies (既知の異常) 」というラベルの付いた緑のリボンで表示される (デフォルト)
- 予測されたイベントは、「 Detected events (検出されたイベント) 」というラベルの付いた赤いリボンで表示される

ツールボックスは、JSON ファイルの読み込み、解析といった手間のかかる作業をすべて実行し、すぐに使用できる視覚化ツールを提供することで、異常検出モデルからインサイトを得るまでの時間を短縮することができます。ツールボックスを使用して、結果の解釈とアクションの実行に集中し、エンドユーザーに直接的なビジネス価値を提供する作業にフォーカスできます。SDK では、これらの時系列の可視化に加えて、正常時と異常時の信号値のヒストグラムを比較するなど、他のプロットも提供されています。すぐに使用できるその他の可視化機能の詳細については、Lookout for Equipment ツールボックスのドキュメントを参照してください。
推論のスケジュールを作成する
ツールボックスを使用して、推論のスケジュールを作成する方法を見てみましょう。
このコードは、5 分ごとに 1 つのファイルを処理するスケジューラを作成します (ファイルがアップロードされる頻度と一致するようにスケジューラを設定する)。15分ほど経つと、いくつかの結果が得られるはずです。スケジューラから Pandas の DataFrame の結果を取得するには、次のコマンドを実行するだけです。
ツールボックスの可視化 API を使用して、予測における特徴量の重要度をプロットすることもできます。
サンプルデータの特徴量の重要度のグラフを生成します。

このツールボックスには、スケジューラを停止する API も用意されています。次のコードを参照してください。
クリーンアップ
ここまで作成されたリソースをすべて削除するには、データセットの名前を指定して delete_dataset API を呼び出します。
結論
産業および製造業のお客様と会話するとき、AI と ML の活用に関してよく聞く課題は、信頼性の高い実用的な結果を得るために、膨大な量のカスタマイズと、特定の開発およびデータサイエンスの作業が必要となることです。異常検出モデルをトレーニングし、さまざまな産業機器に対して、事前にアラートを出すことは、メンテナンスの手間、やり直しや無駄を減らし、製品の品質を向上させ、設備効率 (OEE) や製品ライン全体を改善するための前提条件となります。これまでは、異常検出モデルをトレーニングするために、膨大な開発作業が必要とし、長期にわたって拡張、維持する課題を抱えていました。
Lookout for Equipment などの AWS 事前トレーニング済み AI サービスにより、メーカーはデータサイエンティスト、データエンジニア、プロセスエンジニアのような様々なチームを用意しなくても、 AI モデルを構築できます。Lookout for Equipment ツールボックスを使用すると、開発者は時系列データからインサイトを探索できたり、アクションを実行するために必要な時間をさらに短縮できます。このツールボックスは、Lookout for Equipment を使用して異常検出モデルを迅速に構築するために、開発者に使いやすいインターフェースを提供します。ツールボックスはオープンソースであり、すべての SDK コードは amazon-lookout-for-equipment-python-sdk GitHub リポジトリにあります。PyPI パッケージ として入手することもできます。
この記事では、一部最も重要な API だけを取り上げています。ご興味ある読者は、ツールボックスのドキュメントを参照し、より高度な機能を確認することができます。ぜひ試してみて、コメントにご感想を教えてください!
著者について

Vikesh Pandey は、AWS の機械学習スペシャリストソリューションアーキテクトであり、イギリスおよびより広い EMEA 地域のお客様が ML ソリューションを設計および構築するのを支援しています。仕事以外は、Vikeshはさまざまな料理を試したり、アウトドアスポーツを楽しんだりしています。

Ioan Catana は、AWS の人工知能と機械学習のスペシャリストソリューションアーキテクトです。彼は、お客様が AWS クラウドで スケーラブルな ML ソリューションを開発するのを支援しています。Ioan は、主にソフトウェアアーキテクチャ設計とクラウドエンジニアリングの分野で 20 年以上の経験があります。

Michaël Hoarau は AWS の AI/ML スペシャリストソリューションアーキテクトです。状況に応じてデータサイエンティストと機械学習アーキテクトも担当します。彼は、AI/ML の力を産業界のお客様の製造現場にもたらすことに情熱を傾けており、異常検出から予測的な製品品質の改善や製造の最適化に至るまで、幅広い機械学習のユースケースに取り組んできました。仕事以外は、星を観察したり、旅行したり、ピアノを弾いたりすることを楽しんでいます。
翻訳はSolution ArchitectのMing Yangが担当しました。原文はこちらです。