Amazon Web Services ブログ
Category: Analytics

Kiro CLI と Amazon MSK MCP Server を使用した自然言語による Amazon MSK の簡易管理
この記事では、Kiro CLI と Amazon MSK MCP Server を使用して、自然言語コマンドで Apache Kafka クラスターを管理する方法を紹介します。トピック管理、クラスターの健全性監視、設定の最適化など、複雑な Kafka 操作を対話形式で簡単に実行できるようになります。

AWS re:Invent 2025:ヘルスケア・ライフサイエンスにおける変革の瞬間
このブログは、 “AWS re:Invent 2025: A transformative moment fo […]

Rivian と Volkswagen Technology Group が Amazon Kinesis Video Streams で構築したリアルタイム車両セキュリティ
Rivian と Volkswagen Technology Group が、Amazon Kinesis Video Streams を活用して車両セキュリティの向上を実現した事例を紹介します。Rivian のギアガードフィーチャーの強化により、車内カメラからのリアルタイムビデオストリーミングがモバイルアプリから可能になりました。低遅延、高スケーラビリティ、堅牢なセキュリティなど Kinesis Video Streams の特徴が、車両オーナーに即時のビジュアルアクセスを提供することに貢献しています。WebRTC の活用、地域最適化されたシグナリングサーバー、コスト管理の工夫など、Rivian の設計の詳細も紹介しています。ドライバーの安全とプライバシーを第一に考えた、先進的な車載セキュリティソリューションの事例です。

NATO のマルチドメインオペレーションへの進展: ハイパースケールクラウドによる同盟の変革
本ブログは 2025 年 2月 21 日に公開された AWS Public Sector ブログ「NATO’s […]
Amazon S3 Tables のレプリケーションサポートと Intelligent-Tiering の発表
2025 年 12 月 2 日、 Amazon S3 Tables の 2 つの新機能を発表しました。1 つは […]

AWS Glue 5.0 の Apache Spark におけるオープンテーブルフォーマット機能の活用
この記事では、AWS Glue 5.0 における Apache Iceberg、Delta Lake、Apache Hudi のオープンテーブルフォーマットライブラリの主要なアップデートについて解説します。ブランチとタグによるライフサイクル管理、変更ログビュー、ストレージパーティション結合などの新機能を紹介します。
AWS Glue Data Catalog のテーブル統計自動収集機能の紹介 – Amazon Redshift と Amazon Athena のクエリパフォーマンス向上
AWS Glue Data Catalog で、新しいテーブルの統計情報を自動的に生成できるようになりました。この機能により、Amazon Redshift Spectrum と Amazon Athena のコストベースオプティマイザー (CBO) がクエリを最適化し、パフォーマンス向上とコスト削減を実現します。
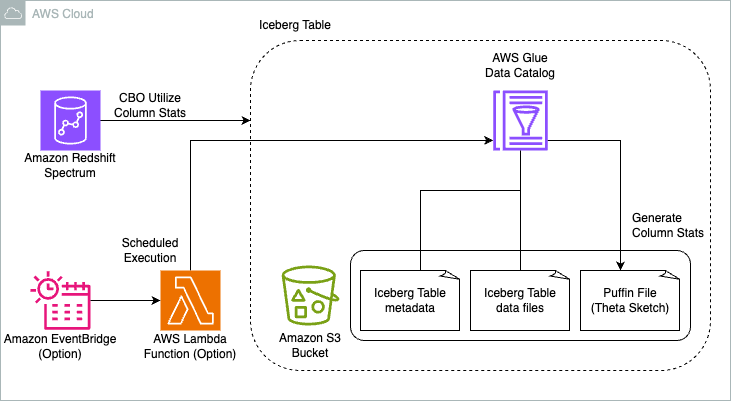
AWS Glue Data Catalog で Apache Iceberg 統計情報を収集してクエリパフォーマンスを高速化する
AWS Glue Data Catalog で Apache Iceberg テーブルのカラムレベル統計情報を生成し、Redshift Spectrum と Amazon Athena のクエリパフォーマンスを最大 83% 向上させる方法を紹介します。

AWS Glue Data Catalog での Apache Iceberg マテリアライズドビューのご紹介
AWS は AWS Glue Data Catalog の Apache Iceberg テーブル向けの新しいマテリアライズドビュー機能を発表しました。この機能により、データパイプラインを簡素化し、事前計算結果を保存してクエリパフォーマンスを向上させることができます。Amazon Athena、Amazon EMR、AWS Glue の Spark エンジンがこの新機能をサポートしています。

サーバーレス MLflow で Amazon SageMaker AI を使用して AI 開発を加速
2024 年 6 月に MLflow を搭載した Amazon SageMaker AI を発表して以来、弊社 […]