Amazon Web Services ブログ
SGK が RDBMS から Amazon DynamoDB に移行することにより、高度に動的なワークロードのデータ構造を簡素化する方法
今日、多くのデータベースソリューションが利用可能となっており、ユーザーの使用事例に適したソリューションを選択することは難しいことがあります。最近では、NoSQL データベースがリアルタイム Web アプリケーションに幅広く採用されています。Amazon DynamoDB は、従来のリレーショナルデータベースマネージメントシステム (RDBMS) に比べて大幅な柔軟性とパフォーマンスの利点をもたらすように最適化された NoSQL データベースの一例です。従来の RDBMS は、固定されたスキーマベースのテーブル設計によって制限される可能性があります。
このブログ記事では、SGK のダイナミックなクライアント設定とルールについて、どのようにして SGK が最適なデザインパターンを作り出したかを SGK Solutions 社のアーキテクトである Murugan Poornachandran 氏が説明します。この設計では DynamoDB を使用して、SGK の進化するマイクロサービスアーキテクチャと多様なステークホルダーに適応します。この新しいデザインは、SGK のレガシー RDBMS ソリューションよりも大幅に改善されました。Murugan 氏はまた、データ管理システムの頻繁な変更を管理または自動化するために、正規化されたリレーショナルデータモデルを使用して、SGK が DynamoDB のスキーマレステーブル機能をどのように使用されているのかについても説明します。このアプローチは、データ処理に要する時間を大幅に短縮します。
背景情報
SGK の Global Content Creation Studio ネットワークは、写真、ビデオ、およびコピーライティングを通じてブランドと製品を消費者に結びつけるコンテンツとソリューションをつくり出します。マルチテナントアプリケーションとしての大規模エンタープライズからマイクロサービスアーキテクチャへ移行する場合、我々が直面した SGK の1つの重要な課題は、クライアントやそれの可変構成とルールを管理することでした。
たとえば、我々はすべてのマイクロサービスでクライアントと構成データを共有する必要がありました。クライアントデータには、カテゴリ、部門、および場所が含まれており、また構成パラメータには、アクセス権限や役割などのセキュリティ関連の詳細が含まれます。さらに、クライアントの構成とルールは、さまざまなユーザー向けにカスタマイズされ、複数のマイクロサービスで共有される必要がありました。
定期的に新しいマイクロサービスをリリースしました。そのため我々にとって、変化するクライアントおよび構成データを関連データベースに保持することがさらに困難になりました。重要な課題は、新しいマイクロサービスごとにデータベースの変更が必要で、またアプリケーション層でのオブジェクトリレーショナルマッピングの更新に時間を要することでした。新しいマイクロサービスの登場のたびにデータ管理システムの複雑さが増したため、新しい REST ベースの管理サービスである DRDS (Dynamic Reference Data Service) を作成することにしました。DRDS は、ダイナミッククライアントの構成とルールを管理するために、プライマリデータストアとして DynamoDB を使用します。DRDS は完全なサーバーレスで、Amazon API Gateway と AWS Lambda を使用して API を提供し、またそのユーザーインターフェイスは Amazon S3 でホストされます。
DynamoDB で実装された NoSQL ソリューションを使用することで、リレーショナルデータモデルの複雑さを軽減できることがわかりました。さらに、このソリューションを使用して、非常に動的な作業負荷の操作を簡素化できることも見出しました。
ソリューションの概要
SGM による DynamoDB の体験は、2014年に遡ります。リレーショナルと NoSQL 設計のトレードオフを理解することは、データ層の再設計において重要なステップでした。NoSQL ソリューションにより、運用上のオーバーヘッドを削減しながらパフォーマンスを最適化できることを我々は認識しました。しかしながら、最終的にはより良く設計されたデータモデルが、アプリケーションの実行方法に大きな違いをもたらします。
データモデリングでは、エンティティ関係モデリングから始めて、アプリケーション内のエンティティ、属性、および関係を定義すると便利です。エンティティはアプリケーションの主なオブジェクトであり、属性はオブジェクトのプロパティであり、また関係はエンティティ間の接続です。これらの関係には、1 対 1 、1 対多、多対多の 3 種類があります。これらは、それぞれ 1:1 、1:N 、M:N と表されることが多く、この記事ではこれらの表記法を使用して関係を表しています。
通常、リレーショナル設計では、エンティティとその関係を記述することに重点を置いています。クエリとインデックスは後で設計されます。ただし、 NoSQL 設計では、クエリファーストアプローチを使用します。このアプローチでは、最初にクエリを識別し、続いてプライマリキーとオプションのインデックスを設計し、データへの高速かつ効率的なアクセスを提供します。
我々のソリューションでは、多対多関係を管理するための M:N 関係とグローバルセカンダリインデックスのモデリングの複雑さを排除する、単一の DynamoDB テーブルを使用します。クエリパターンを前もって定義し、適切な主キーを指定しました。この NoSQL のアプローチは有益でかつ、RDBMS から移行したときに DynamoDB データモデルを単純化するうえで役立ちました。
これらの概念を理解するために、 SGK の DynamoDB データモデルを詳細に検討してみましょう。
SGK の DynamoDB データモデル
以下は、 SGK の DynamoDB テーブルの定義です。M:N の関係を管理するために、テーブルのソートキー (id) にグローバルセカンダリインデックスを作成しました。次のセクションでは M:N の関係を例に挙げ、デザインにグローバルセカンダリインデックスを組み込むことについて説明します。
| フィールド | タイプ |
| type (プライマリパーティションキー) | 文字列 |
| id (一次ソートキー) | 文字列 |
| name | 文字列 |
| 任意のデータ属性 (必要に応じて) | 文字列|日付|数値|ブーリアン| |
前述した DynamoDB テーブル設計は、SGK の柔軟なソリューションのキーです。JSON の文書関係をサポートするために、次のようなデータ設計の意思決定と規約を作成しました。
- フィールド
type– パーティションキーは、エンティティの種類を定義します。リレーショナルデータベースでは、type名はテーブル名と見なすことができます。例えば、リレーショナルデータベースでCountryテーブルを表す Country で始まるtypeのすべての行を表示できます。 - フィールド
id– ソートキーは、関連レコードを検索するメカニズムとしてソートキーが使用されるように、typeレコードの主キーとして設計されています。例えば、10カ国があり各国の状態を保存したい場合、typeはCountryで始まり、id 値は国コードと州 ID を連結したStateです (例えば、State-US-CA、State-US-NY、およびState-CA-ON)。部分文字列のUSまたはCAはCountryレコードの ID 値であり、国と州の間に黙示的な 1:N のM:N の関係を構築します。このアプローチにより、ソートキーでbeginsWithUS フィルターを使用して、すべての米国の州を簡単に取得することができます。同様に、カリフォルニア州のすべての都市を照会するには、Cityのtypeの ID フィールドにbeginsWith US-CAフィルターを使用します。このデータモデルの例を次の図で示します。

前述の例では、パーティション (type) キーとソート (id) キーを使用して、国に関連するすべての詳細について格納および照会することができます。このアプローチでは、パーティションキーのtype = 'Country-US'を使用してクエリを単に実行するだけで、例えば、米国の国情報と関連する州および都市の詳細を簡単に照会することができます。必要に応じてソートキーの条件 IDbeginsWith 'State'を追加することで、状態だけを簡単にフィルタリングすることもできます。同様に、状態関連の詳細を管理するために、必要に応じて'State-IL'パーティションを作成することができます。 typeフィールドがコンフィギュレーションで、一意のテーブルの数を取得したとき、メタデータが定義されます。これらのコンフィギュレーションレコードは、各テーブルのフィールドと関係を定義します。コンフィギュレーションデータについては、次のセクションで詳しく説明します。
このデータ設計により、関係を持つ動的で柔軟なデータモデルの作成が可能です。
コンフィギュレーションデータ
SGK のソリューションでは、コンフィグレーションデータがマスタデータエンティティに格納されているエンティティとフィールド (つまり、クライアントデータ) を記述します。このコンフィギュレーションメタデータは、DynamoDB 内のいかなる関係を定義または管理したりしませんが、存在するエンティティの数とそれらの関係を理解するうえで重要です。次のスクリーンショットは、‘xyzonlinestore‘ アプリケーションの Country の設定方法を示しています。

前述のスクリーンショットで示した JSON を詳しく見ていきましょう。
- ソートキーは、28 行目の id フィールドとして
master-xyzonlinestore-countryに指定されています。- ソートキーのプレフィックス
masterは、特定の種類のクライアントデータを参照します。xyzonlinestoreは構成中のマイクロサービス (またはアプリケーション) です。countryは構成されたエンティティです。
- ソートキーのプレフィックス
- 29 行目のフィールドの
nameは、Countryをクライアントデータとして構成していることを示しています。 - パーティションキーは 31 行目の
typeフィールドで、コンフィギュレーションに設定されています。
このアプローチでは、クライアントリソースを JSON オブジェクト内の任意の数の属性で関連付けることができます。この例では、 2 行目のフィールドレコードに id 、name、およびflagという 3 つの属性を定義しています。
後で属性を追加する必要がある場合、DynamoDB で Country エンティティ構造の変更が容易に行えます。新しいフィールドで JSON オブジェクトを単純に更新できます。対照的に、RDBMS では、アプリケーション層でデータアクセスオブジェクト (DAO) を含む複数のテーブル、関係、およびインデックスを更新する必要があります。
この戦略により、クライアントリソース定義を迅速かつ動的に追加または削除する柔軟性が得られます。
では、1:N の関係例を見てみましょう。
1:N の関係例
RDBMS では、あるテーブルの親レコードが別のテーブルの複数の子レコードを参照する可能性がある場合、1:N の関係が発生します。1:N の関係では、子レコードは複数の親レコードを持つことはできません。このロジックは、エンティティに関連する関連する子レコードを追跡するうえで便利です。この記事の例を続行するために、State リソースの都市リストを構成するシナリオを考えてみましょう。例えば、イリノイ州の State リソースには複数の都市が含まれています。イリノイ州のすべての都市を一覧表示するクエリを発行するには、type=State-IL と id beginsWith City のフィルターを使用します。
では、M:N の関係例を見てみましょう。
M:N の関係例
RDBMS では、表の複数のレコードが別の表の複数のレコードに関連付けられている場合、M:N の関係が発生します。RDBMS では、通常 2 つのテーブル間で直接 M:N の関係を実装することはできません。通常は、M:N の関係を 3 つの表を使用して 2 つの 1:N の関係に分割します。DynamoDB を使用することで、1 つのテーブルとグローバルセカンダリインデックスに M:N の関係を実装することが可能となりました。
例えば、複数の国に関連する製品のリストがあるとしましょう。グローバルセカンダリインデックスを使用する隣接リストデザインパターンを実装することにより、データの重複を最小限に抑えて DynamoDB でこの M:N の関係を簡単に表現できます。
次の図は、この M:N の関係がどのように機能するかについての例を示しています。マスターデータ表は、製品と国との 1:N の関係を示しています。マスターデータのグローバルセカンダリインデックスは、国と製品の 1:M の関係を示しています。これと一緒に、これらの関係はこれら 2 つのエンティティの M:N の関係を形成します。
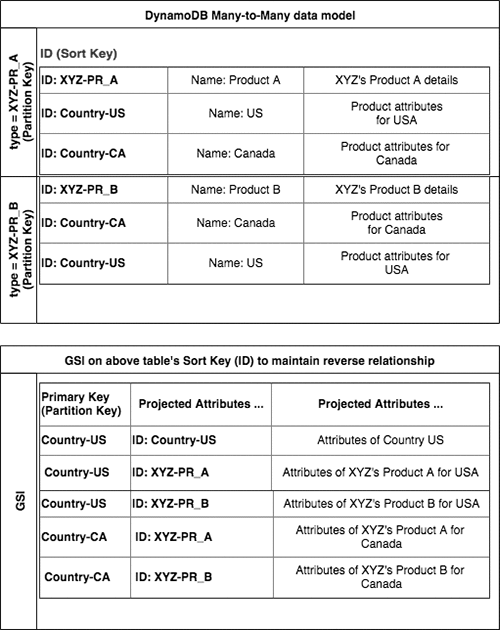
この例では、XYZ の製品データがそれ自身のパーティションに格納されています。このパーティションには、製品情報と関連またはサポートされている国のリストが含まれています。上述のテーブルでの最初のサンプルは、製品 A の米国とカナダの詳細を示しています。Product A でサポートされているすべての国を一覧表示するには、type='XYZ-PR_A' と ID beginsWith 'Country-' で始まる DynamoDB テーブルに対してクエリを発行することが可能です。
グローバルセカンダリインデックスは、この関係を国の視点から見るうえで役立ちます。例えば、カナダのすべての製品を一覧表示するには、IndexName = 'Country-CA' のグローバルセカンダリインデックスに対してクエリを発行します。このアプローチは、マスターデータ </code テーブルから直接データを照会するよりも効率的です。
これまでこのブログ記事では、DynamoDB を使用し 1:N と M:N の関係を含むデータの単一テーブルを管理することがどのように効率的であるか確認しました。これらの実効的なパーティションとソートキーデータモデル、そして DynamoDB の柔軟設計を使用して変更されることが多いクライアントエンティティとその関係を上手く管理できます。
では、この設計をレガシー RDBMS ソリューションと比較してみましょう。
SGK の前の RDBMS 参照データモデル
これまで説明してきた DynamoDB ソリューションとは対照的に、RDBMS ソリューションは全く異なった働きをしていました。RDBMS ソリューションでは、各クライアントエンティティは、独自の属性、インデックス、および外部キーの関係を持つ別個のテーブルでした。我々はこれらの関係を個別に維持する必要がありました。次の図に RDBMS のデータモデルが表示されます。

上述の図が示すように、country テーブルは products テーブルと M:N の関係にあります。この関係は、products_country_association テーブルを使用して 1:N の関係としてモデル化されます。stateテーブルはcityテーブルと 1:N の関係にあり、countryテーブルはstateテーブルと 1:N の関係にあります。
RDBMS の設計は、スキーマを頻繁に更新する必要がない場合に有効でした。テーブル、フィールド、関係の追加など、進化するマイクロサービスアーキテクチャのために頻繁に変更を加えなければならなかった、ということが課題でした。リレーショナルデータモデルを使用することで、クライアントデータを管理する多くの開発サイクルを費やす必要がありました。
DynamoDB データモデルでは、テーブルとフィールドの両方の構成が可能となり、マイクロサービスアーキテクチャに追いつくために開発サイクルを追加する必要がもはやなくなりました。DynamoDB の複雑な関係を動的な設定で簡単に管理することができます。
要約
SGK のダイナミック DynamoDB データモデルにより、現在そして将来のニーズを満たすために、さまざまなクライアントデータを格納し提供するきめ細やかな管理サービスを構築することができました。このソリューションにより、運用保守が大幅に削減され、お客様のビジネスニーズに集中することができます。
著者について
 Murugan Poornachandran 氏は、経験豊かなエンタープライズとクラウドソリューションのアーキテクトです。JEE と AWS ソリューションの専門知識を持っています。同氏は現在、 AWS を使用した AI ソリューションを設計しており、SGK Inc. のマイクロサービスアーキテクチャと AWS サーバレスソリューションを使用して大企業アプリケーションを AWS Cloud に移行しています
Murugan Poornachandran 氏は、経験豊かなエンタープライズとクラウドソリューションのアーキテクトです。JEE と AWS ソリューションの専門知識を持っています。同氏は現在、 AWS を使用した AI ソリューションを設計しており、SGK Inc. のマイクロサービスアーキテクチャと AWS サーバレスソリューションを使用して大企業アプリケーションを AWS Cloud に移行しています
 Wangechi Doble 氏は、AWS の ビックデータ分析に焦点を当てたプリンシパルソリューションアーキテクトです。同氏は、顧客が AWS で高性能でスケーラブルで安全なクラウドベースのソリューションを設計および構築することを支援します。
Wangechi Doble 氏は、AWS の ビックデータ分析に焦点を当てたプリンシパルソリューションアーキテクトです。同氏は、顧客が AWS で高性能でスケーラブルで安全なクラウドベースのソリューションを設計および構築することを支援します。