Amazon Web Services ブログ
Amazon SageMaker を使い 自動的に 3D 地震波データを分析する
正確な3D 地震波データの分析は、原油や天然ガスが埋蔵あるいは滞留している可能性のある地質的な特質を割り出すことに役立てられます。Amazon SageMaker と Apache MXNet on AWS により、深層学習を使った地中探査が自動化できます。
このブログ記事では、これらのサービスを使い、3D 地震波データが示す地質的特質の解釈を行う、カスタム深層学習モデルの構築とトレーニングを行ってみます。この記事の目的は、カスタム化されたセマンティックセグメンテーションモデルの素早く簡単な作成方法を、原油と天然ガス事業に携わるデータサイエンティストの方に示すことにあります。
Amazon SageMaker は、データサイエンティストが、機械学習モデルをあらゆる規模で構築、トレーニング、チューニング、そしてデプロイできるようになる、完全マネージド型のサービスです。このサービスでは、パワフルかつスケーラブルであり、同時に使用法も簡単なコンピューティング環境を提供しています。
| このブログ記事について | |
| 読む時間 | 15 分 |
| 完了するまでの時間 | ~1 時間 |
| 完了するためのコスト | 60 USD 未満 |
| 学習レベル | 中級 (200) |
| AWS のサービス | Amazon SageMaker、EC2、Amazon S3 |
概要
どの地点をどの程度深く掘り下げるか決定し、原油や天然ガス生産の最適化とその他のことを行う際、地下の地質について詳しく知ることが重要になります。3D 地震波イメージングという技術により、地震波データの画像変換が行えます。その後、必要な地層 (たとえば岩塩層) と構造 (断層や褶曲) の特定が行われます。この「picking horizons」と呼ばれる、手動での特定プロセスは、ときに数週間を要することがあります。
セマンティックセグメンテーションなどの深層学習テクニックを使うと、手動による地中探査が自動化できます。このテクニックでは、深層畳み込みニューラルネットワークを使い特性の抽出と緻密層の検知をし、その分割と分類を行います。しかしながら、地震波を扱うアプリケーションで深層学習モデルをトレーニングするためには、 GPU が必須です。原油や天然ガスに携わる多くのデータサイエンティストたちにとって、コンピューティングリソースの不足は、地震波向けアプリケーションへの深層学習の応用を困難にしているのです。
今回の記事では、セマンティックセグメンテーションには U-Net のストラクチャを使用し、また、Kaggle によるコンペティションからパブリックドメインに提供された画像データセットも合わせて使用します。これらのリソースを使い、地表下に存在する岩塩層を特定するためのアルゴリズムを構築していきます。このノートブックは簡単に複製および拡張ができるので、地震波データにセマンティックセグメンテーションを応用する他のアプリケーションにも利用いただけます。
ワークフロー
Amazon SageMaker によるセマンティックセグメンテーションを実施するには、次の手順に従います。
- Kaggle からのデータをアップロードしデータファイルを作成します。
- 画像を準備します。
- モデルのトレーニングを行います。
- モデルをデプロイします。
前提条件
Amazon SageMaker でのセマンティックセグメンテーションのためには、最初に次に示す手順を行う必要があります。
- AWS アカウントを作成します (チュートリアル) 。
- AWS アカウントにログインします。
- Amazon SageMaker ノートブックインスタンスを作成します。セットアップ中のノートブックインスタンスは保留状態です。数分経過すると利用可能になります。
Amazon SageMaker に コードと Kaggle からのデータをアップロードします。
次のノートブックとコードを、ご自身のコンピュータにダウンロードします。
Amazon SageMaker コンソールで、[Notebook]、[Notebook instances] の順にクリックします。[Actions] 列から [Open Jupyter] を選択します。[Upload] をクリックし、先にダウンロードした 3 つのファイルを、お手元のコンピュータから Amazon SageMaker インスタンスにアップロードします。
SageMaker インスタンスで、[New]、[Folder] の順にクリックし、「data」という名前のフォルダーを作成します。 新しく作成したこのフォルダー内に、先にダウンロードした GS Kaggle のデータから「train 」フォルダーをコピーします。
エポックやインスタンスの数など、その他のハイパーパラメータを変更する必要がなければ、このノートブック内の他の部分は、現状のままにしておいてかまいません。
画像の準備
ここまでで、Amazon SageMaker インスタンスが作成され、必要なコードと Kaggle からのデータがコピーされました。次に、基本的な画像品質の調整を行いましょう。TGS での岩塩層画像とそれに対応するマスクファイルの例を示します。
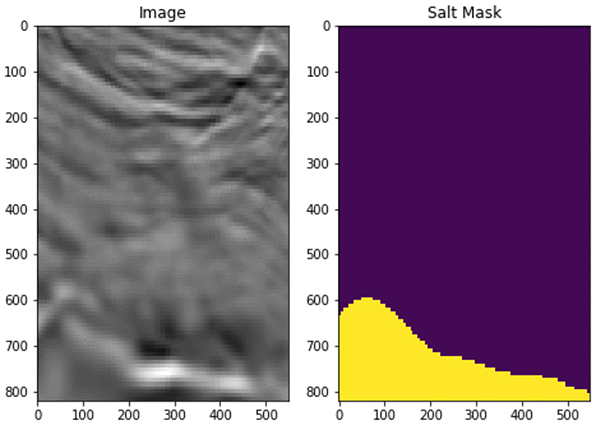
このファイルを単一の変数にスタックし、データ増強のためのランダムクロッピングを行います。
モデルのトレーニング
準備が完了したデータは、ノートブック内にある指示に従い Amazon S3 にアップロードしトレーニングを行います。使用するインスタンスタイプやインスタンスの数を、指定することができます。
今回の例で行う深層ニューラルネットワークでの画像分類処理は、GPU インスタンスで実行することをお勧めします。分散トレーニングを行う場合は、GPU インスタンスを複数使用することも選択できます。GPU インスタンスの数を入力するだけで、後の定義は Amazon SageMaker が自動で行ってくれます。
その後、次に示すコードに従ってハイパーパラメータを定義します。
次に示すコードにより、このハイパーパラメータを使ったモデルのトレーニングが実行されます。Amazon SageMaker Python SDK for MXNet の詳細については、GitHub レポジトリの sagemaker-python-sdk をご参照ください。
モデルのデプロイ
モデルのトレーニングを終えたら、クラウドにデプロイし、リアルタイムの予測を行います。トレーニングの時と同様に、ご自身のモデルをデプロイする際のインスタンス数とそのタイプが設定可能です。それには、次のコードのように指定します。
岩塩層の予測に、ここで構築したモデルを使用した際の一例を、次に示します。
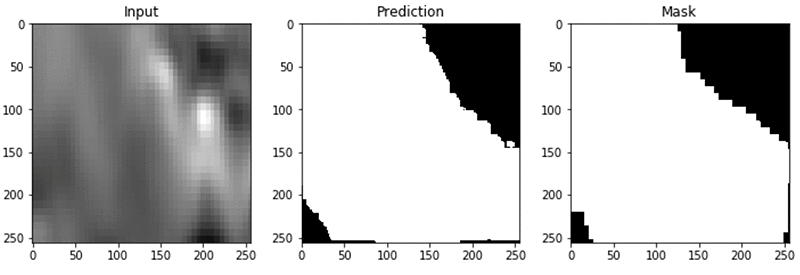
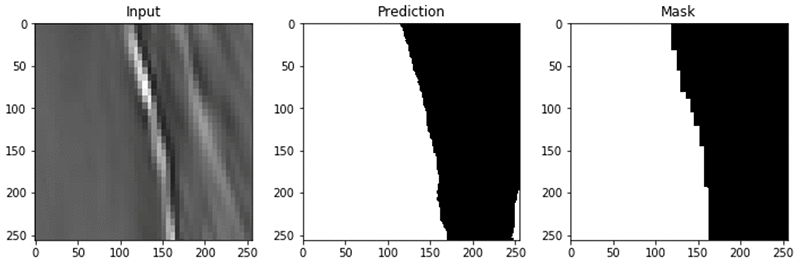
まとめ
この記事では、Amazon SageMaker を使用して、最小限のコーディング作業で地震波応用アプリケーション用のセマンティックセグメンテーションを行う方法を解説しました。ここで示した例は、フォルダーの名前を所望の画像に合わせて変更するだけで、他のアプリケーション向けに簡単にカスタマイズできます。Amazon SageMaker によるセマンティックセグメンテーションの、他のアプリケーションでの応用に関する詳細については、次のリンクをご参照ください。
- Apache MXNet を Amazon SageMaker および AWS Greengrass ML Inference と共に使用する脳組織のセグメント化 – パート 1
- Amazon SageMaker で、セマンティックセグメンテーションアルゴリズムが利用可能になりました
ご質問またはご提案などについては、下記へコメントをお寄せください。
謝辞
Amazon SageMaker でのセマンティックセグメンテーションのためのオリジナルコードをご提供くださった、AWS の Brad Kenstler 氏に感謝の意を表します。
著者について
 Mehdi E. Far 氏は Solutions Prototyping チームのリードデータサイエンティストです。彼はテキサス州ヒューズトン在住で、主に、グローバルアカウントを取り扱っています。彼は、地球物理学と石油工学の専門知識を持っています。
Mehdi E. Far 氏は Solutions Prototyping チームのリードデータサイエンティストです。彼はテキサス州ヒューズトン在住で、主に、グローバルアカウントを取り扱っています。彼は、地球物理学と石油工学の専門知識を持っています。