Amazon Web Services ブログ
Amazon SageMaker Canvas では、コードを一切書かずに機械学習を使用できます
最近では、特にテキストや画像形式のデータについて、機械学習 (ML) を使用して予測を行う際、ディープラーニングモデルの作成とチューニングに関する広範な機械学習の知識が必要でした。今日では、ML モデルを使用してビジネス価値を生み出したいと考えているすべてのユーザーが、ML にアクセスしやすくなっています。Amazon SageMaker Canvas を使用すると、コードを 1 行も記述せずに、表形式データや時系列データだけでなく、さまざまなデータタイプの予測を作成できます。これらの機能には、画像、テキスト、およびドキュメントデータタイプの事前トレーニング済みモデルが含まれます。
この記事では、事前トレーニング済みのモデルを使用して、表形式データ以外にもサポートされているデータタイプの予測を取得する方法について説明します。
テキストデータ
SageMaker Canvas は、ML モデルの構築、トレーニング、デプロイを行うためのノーコードのビジュアルインターフェースを提供します。自然言語処理 (NLP) タスクの場合、SageMaker Canvas は Amazon Comprehend とシームレスに統合されているため、言語検出、エンティティ認識、感情分析、トピックモデリングなどの主要な NLP 機能を実行できます。この統合により、Amazon Comprehend の堅牢な NLP モデルを使用するためのコーディングやデータエンジニアリングが不要になります。テキストデータを提供し、一般的に使用される4つの機能(感情分析、言語検出、エンティティ抽出、個人情報検出)から選択するだけです。シナリオごとに、UI を使用してテストし、バッチ予測を使用して Amazon Simple Storage Service (Amazon S3) に保存されているデータを選択できます。
感情分析
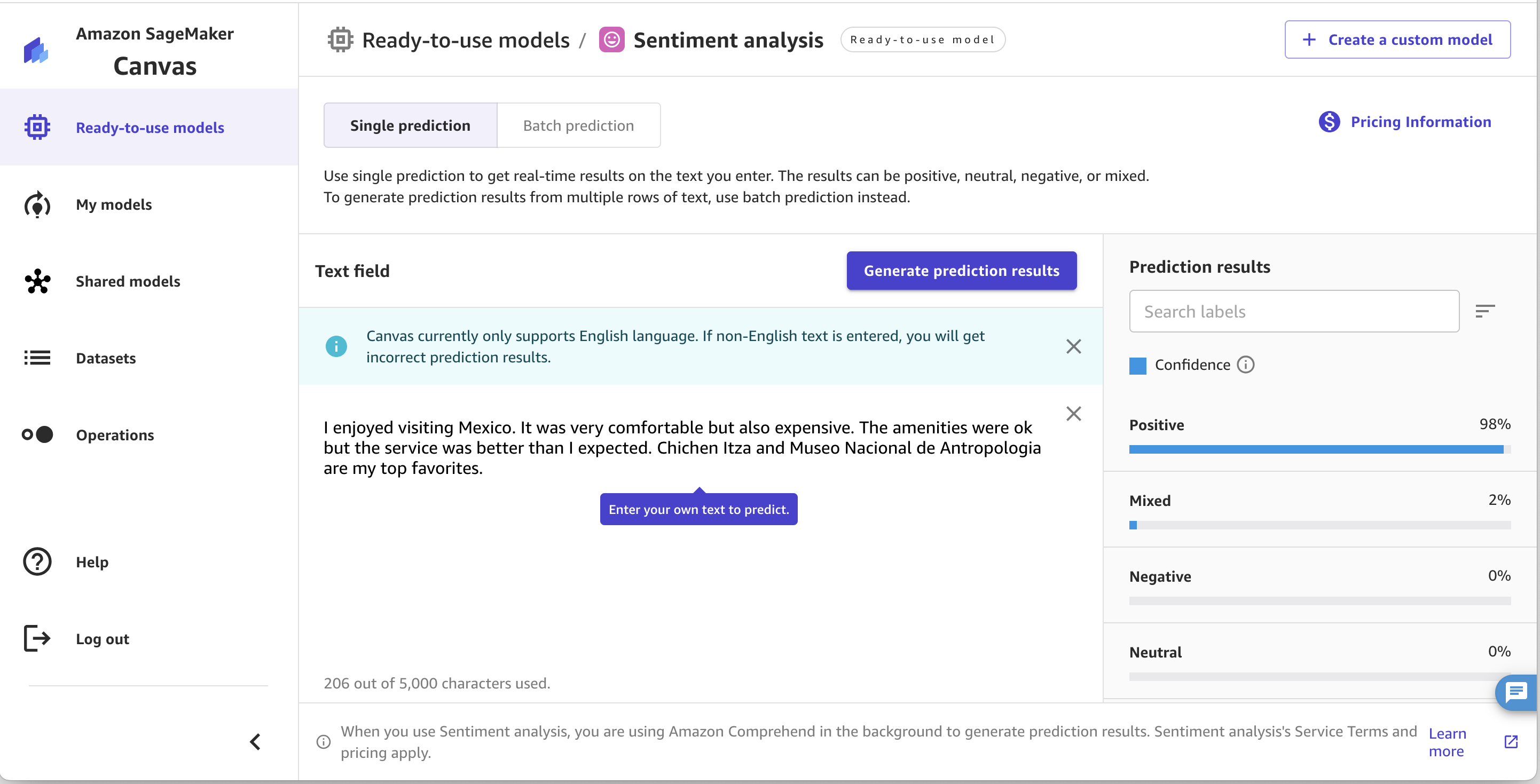
感情分析を使用すると、SageMaker Canvas では入力テキストの感情を分析できます。次のスクリーンショットに示すように、全体的な感情がポジティブ (Positive)、ネガティブ (Negative)、混合 (Mixed)、ニュートラル (Neutral) のいずれであるかを判断できます。これは、商品レビューの分析などの場合に便利です。たとえば、「この製品が大好きです、すごいです!」というテキストがあるとします。SageMaker Canvas ではポジティブな感情を持つものとして分類され、「この製品はひどい、買ったことを後悔している」はネガティブな感情として分類されます。
エンティティ抽出
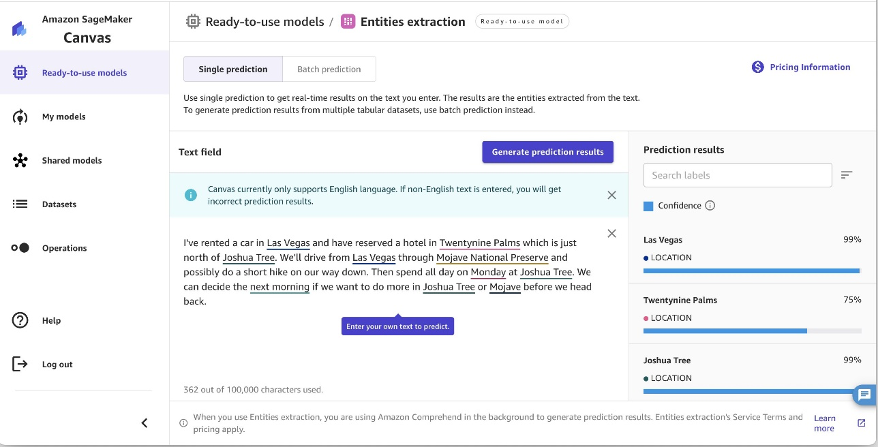
SageMaker Canvas はテキストを分析し、その中に記載されているエンティティを自動的に検出できます。文書が分析のためにSageMaker Canvas に送信されると、テキスト内の人、組織、場所、日付、数量、およびその他のエンティティが識別されます。このエンティティ抽出機能により、文書で議論されている主要な人物、場所、詳細についての洞察をすばやく得ることができます。サポートされているエンティティのリストについては、「エンティティ」を参照してください。
言語検出
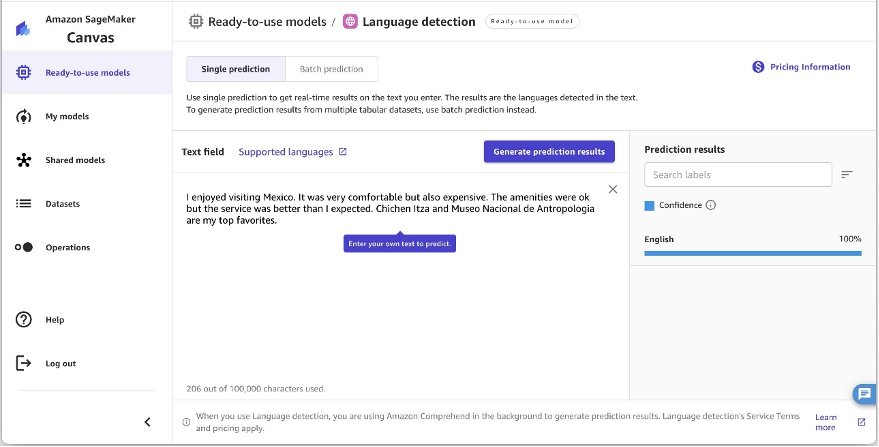
SageMaker Canvas では、Amazon Comprehend を使用してテキストの主要言語を判断することもできます。テキストを分析して主要言語を特定し、検出された主要言語の信頼度スコアを提供しますが、多言語文書の割合の内訳は示しません。複数言語の長い文書で最良の結果を得るには、テキストを小さな部分に分割し、結果を集計して言語の割合を推定します。20 文字以上のテキストで最適に動作します。
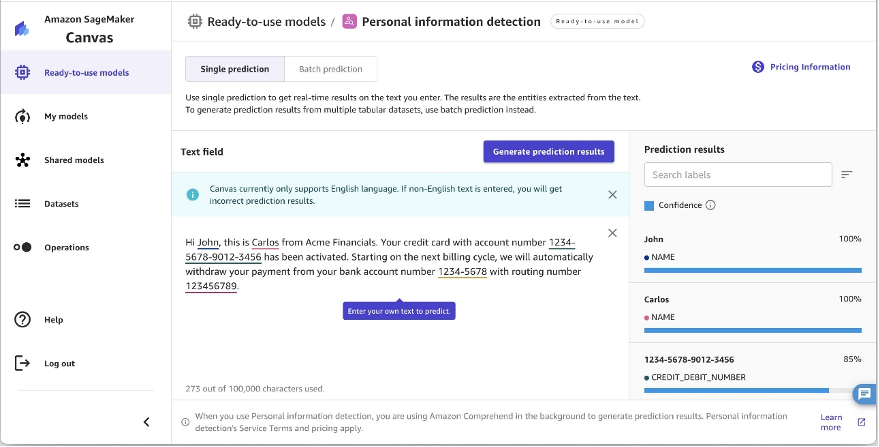
個人情報検出
SageMaker Canvas による個人情報検出を使用して機密データを保護することもできます。テキスト文書を分析して個人を特定できる情報 (PII) エンティティを自動的に検出できるため、名前、住所、生年月日、電話番号、電子メールアドレスなどの機密データを特定できます。最大 100 KBのドキュメントを分析し、検出された各エンティティの信頼度スコアを提供するため、最も機微な情報を確認して選択的に削除できます。検出されたエンティティのリストについては、「PII エンティティの検出」を参照してください。(訳者注: 対応言語は開発者ガイドを参照してください)
画像データ
SageMaker Canvas は、Amazon Rekognition と統合することで、コンピュータビジョン機能を簡単に使用できるノーコードの視覚的なインターフェイスを画像分析のために提供します。たとえば、画像のデータセットをアップロードしたり、Amazon Rekognition を使用してオブジェクトやシーンを検出したり、テキスト検出を実行してさまざまなユースケースに対応できます。視覚的なインターフェイスと Amazon Rekognition の統合により、開発者以外のユーザーでも高度なコンピュータービジョン技術を活用できます。
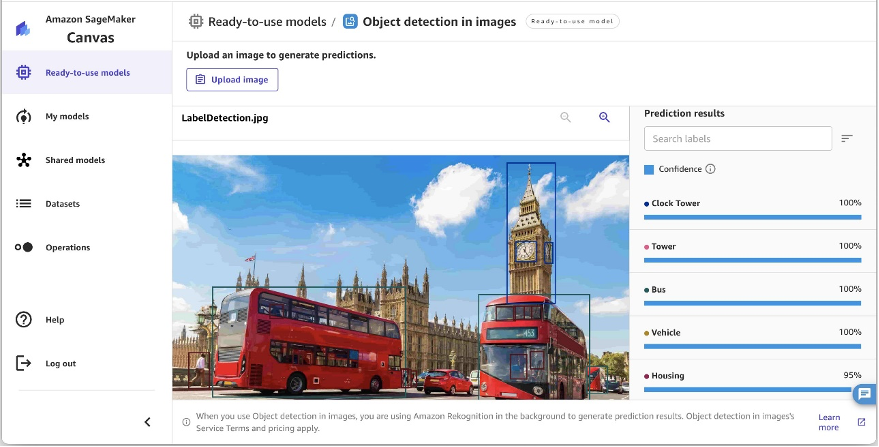
画像内のオブジェクト検出
SageMaker Canvas は Amazon Rekognition を使用して画像内のラベル (オブジェクト) を検出します。SageMaker Canvas UI から画像をアップロードするか、Batch prediction タブを使用して S3 バケットに保存されている画像を選択できます。次の例に示すように、時計塔、バス、建物などの画像内のオブジェクトを抽出できます。インターフェイスを使用して予測結果を検索し、並べ替えることができます。
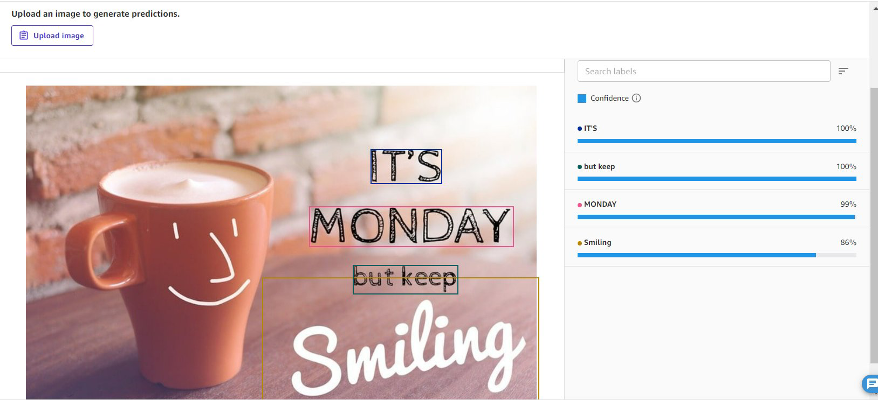
画像内のテキスト検出
画像からテキストを抽出することは非常に一般的なユースケースです。このタスクを SageMaker Canvas 上ノーコードで簡単に実行できるようになりました。次のスクリーンショットに示すように、テキストは行項目として抽出されます。画像内の短いフレーズはまとめて分類され、1 つのフレーズとして識別されます。(訳者注: 対応言語は開発者ガイドを参照してください)
一連の画像をアップロードしてバッチ予測を実行し、1 つのバッチジョブですべての画像を抽出し、結果を CSV ファイルとしてダウンロードできます。このソリューションは、画像内のテキストを抽出して検出する場合に便利です。
文書データ
SageMaker Canvas には、日々の文書理解のニーズを解決する、すぐに使えるさまざまなソリューションが用意されています。これらのソリューションは Amazon Textract によって提供されています。ドキュメントで使用できるすべてのオプションを表示するには、次のスクリーンショットに示すように、ナビゲーションペインで Ready-to-use models を選択し、Document でフィルタリングします。(訳者注: 対応言語は開発者ガイドを参照してください)
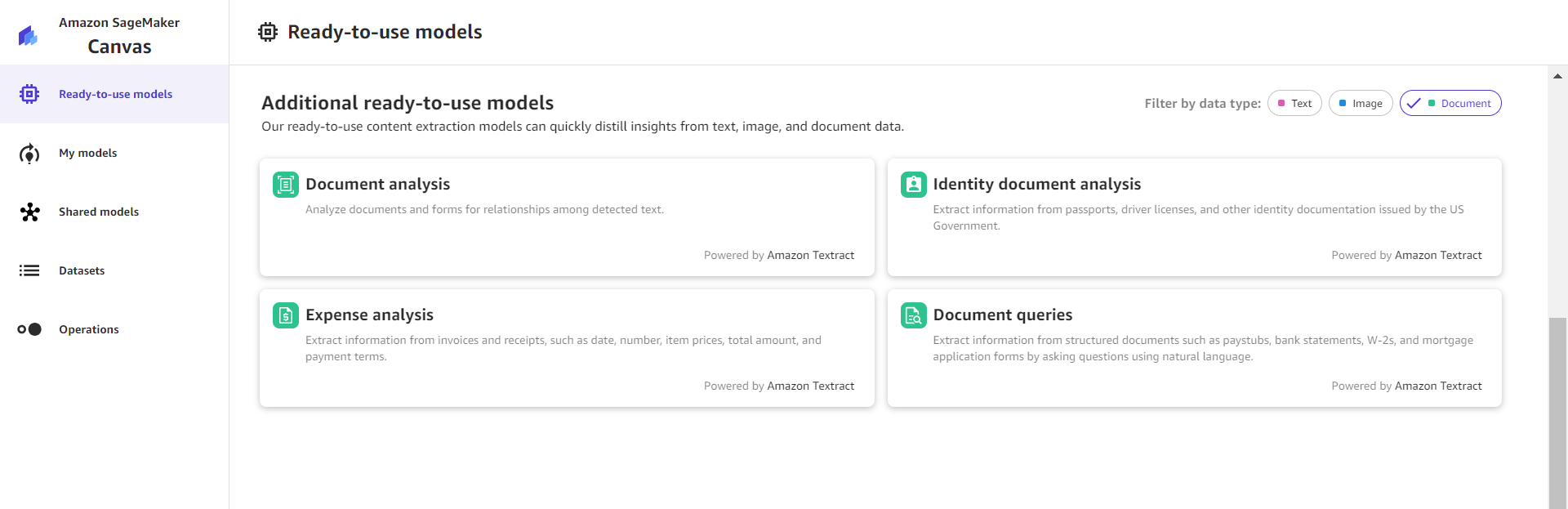
文書分析
文書分析では、検出されたテキスト間の関係について文書とフォームを分析します。このオペレーションでは、未加工テキスト (Raw text)、フォーム (Forms)、テーブル (Tables)、署名 (Signatures) の 4 つのカテゴリの文書抽出が返されます。このソリューションは文書構造を理解できるため、文書から抽出するデータの種類をさらに柔軟に設定できます。次のスクリーンショットは、テーブル検出がどのように見えるかの例です。
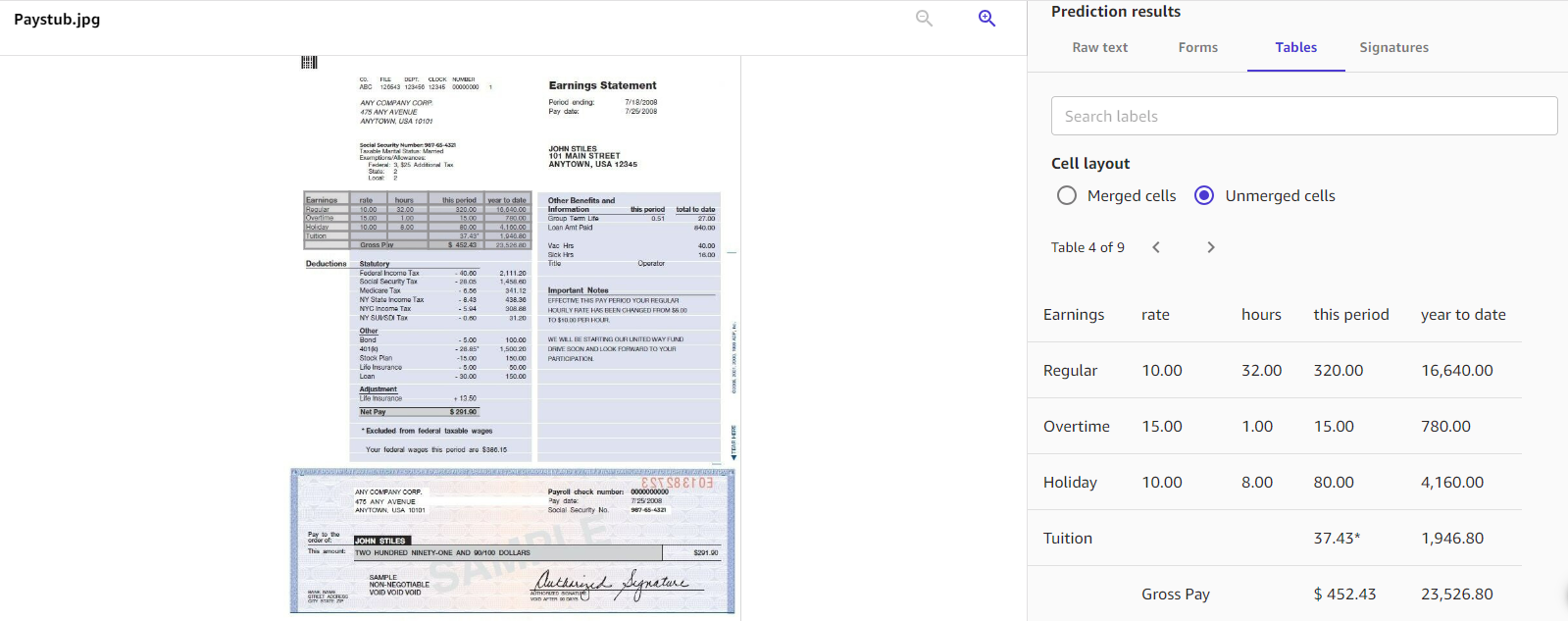
このソリューションは複雑な文書のレイアウトを理解できるため、文書内の特定の情報を抽出する必要がある場合に役立ちます。
身分証明書分析
このソリューションは、個人識別カード、運転免許証、またはその他の類似の身分証明書などの文書を分析するように設計されています。ミドルネーム、郡、出生地などの情報は、次のスクリーンショットに示すように、正確性に関する個人の信頼スコアとともに、IDドキュメントごとに返されます。
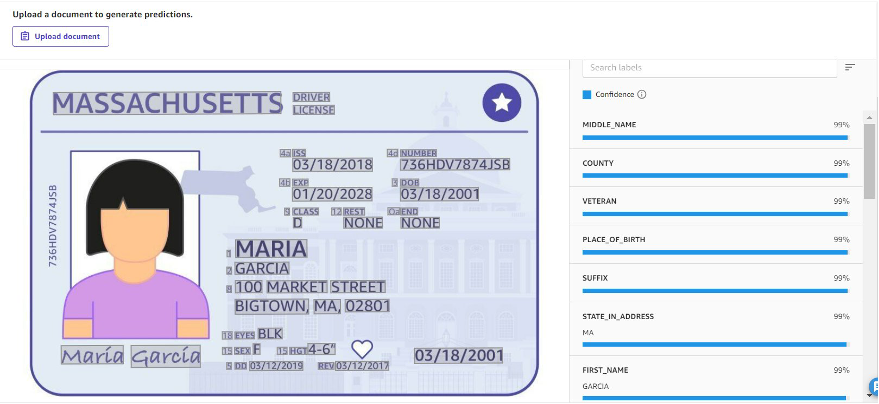
バッチ予測を行うオプションもあります。これにより、識別書類のセットを一括アップロードし、バッチジョブとして処理できます。これにより、身分証明書の詳細を、データ分析などの下流プロセスに使用できるキーと値のペアに迅速かつシームレスに変換できます。
経費分析
経費分析は、請求書や領収書などの経費文書を分析するように設計されています。次のスクリーンショットは、抽出された情報がどのように見えるかの例です。
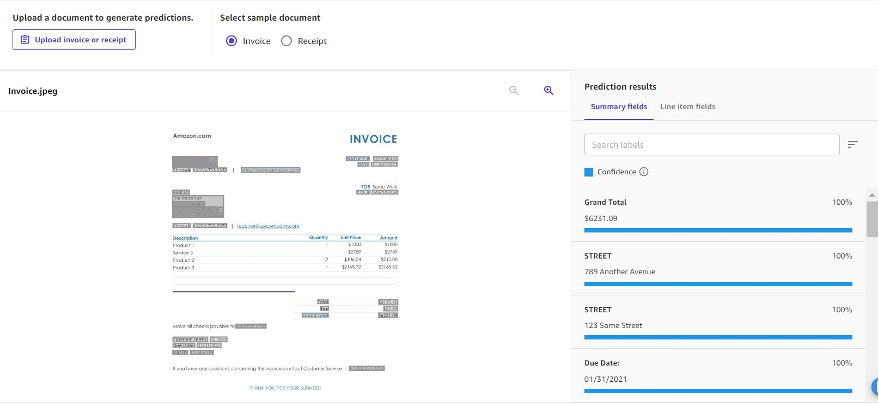
結果は集計フィールドと行項目フィールドとして返されます。Summary fields はドキュメントから抽出されたキーと値のペアで、Grand Total、Due Date、Tax などのキーが含まれます。Line item fields とは、ドキュメント内のテーブルとして構造化されたデータを指します。これは、レイアウトを維持したままドキュメントから情報を抽出する場合に便利です。
ドキュメントクエリ
ドキュメントクエリは、ドキュメントについて質問できるように設計されています。これは、複数ページのドキュメントがあり、ドキュメントから非常に具体的な回答を抽出したい場合に使用するのに最適なソリューションです。以下は、質問できる質問の種類と、抽出された回答の例です。
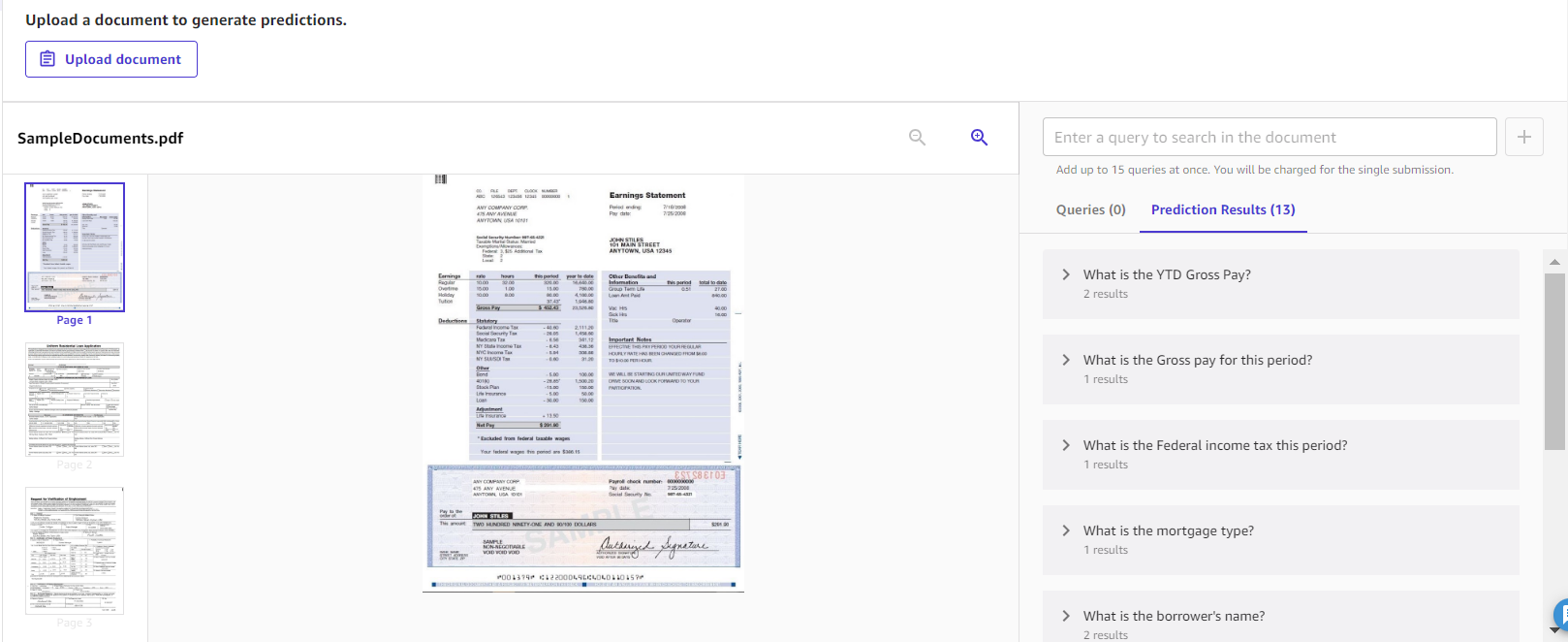
このソリューションは、ドキュメントを操作するためのわかりやすいインターフェイスを提供します。これは、大きな文書の中で特定の詳細情報を取得したい場合に役立ちます。
まとめ
SageMaker Canvas は、テキスト、画像、文書などのさまざまなデータタイプで ML を簡単に使用できるノーコードの環境を提供します。視覚的なインターフェイスと、Amazon Comprehend、Amazon Rekognition、Amazon Textract などの AWS サービスとの統合により、コーディングやデータエンジニアリングの必要がなくなります。テキストの場合、感情、エンティティ、言語、PIIに関して分析できます。画像の場合、オブジェクトとテキストの検出により、コンピュータービジョンのユースケースが可能になります。最後に、ドキュメント分析では、下流プロセスのためにドキュメントのレイアウトを維持しながらテキストを抽出できます。SageMaker Canvas のすぐに使用できるソリューションにより、高度な ML 技術を活用して、構造化データと非構造化データの両方から洞察を得ることができます。すぐに使える ML モデルでコード不要のツールを使用することに興味があるなら、今すぐ SageMaker Canvas を試してみてください。詳細については、「Amazon SageMaker Canvas の使用を開始する」を参照してください。
翻訳はソリューションアーキテクト菊地が担当しました。原文はこちらです。
著者について
 Julia Ang は、シンガポールを拠点とするソリューションアーキテクトです。彼女は、医療や公共部門からデジタルネイティブビジネスまで、さまざまな分野の顧客と協力して、ビジネスニーズに応じたソリューションを採用してきました。また、東南アジアをはじめとする地域のお客様のビジネスにおける AI と ML の活用を支援してきました。仕事以外では、旅行やクリエイティブな活動を通じて世界について学ぶことを楽しんでいます。
Julia Ang は、シンガポールを拠点とするソリューションアーキテクトです。彼女は、医療や公共部門からデジタルネイティブビジネスまで、さまざまな分野の顧客と協力して、ビジネスニーズに応じたソリューションを採用してきました。また、東南アジアをはじめとする地域のお客様のビジネスにおける AI と ML の活用を支援してきました。仕事以外では、旅行やクリエイティブな活動を通じて世界について学ぶことを楽しんでいます。
 Loke Jun Kai は、シンガポールを拠点とする AI/ML のスペシャリストソリューションアーキテクトです。彼は ASEAN 全域の顧客と協力して、AWS で大規模な機械学習ソリューションを構築しています。Jun Kai は、ローコード・ノーコード・機械学習ツールの提唱者です。余暇には、自然とのふれあいを楽しんでいます。
Loke Jun Kai は、シンガポールを拠点とする AI/ML のスペシャリストソリューションアーキテクトです。彼は ASEAN 全域の顧客と協力して、AWS で大規模な機械学習ソリューションを構築しています。Jun Kai は、ローコード・ノーコード・機械学習ツールの提唱者です。余暇には、自然とのふれあいを楽しんでいます。