献立を考えるのが大変なら AI に任せればいいじゃない
~ Amazon Personalize で献立をレコメンドしてみた ~
呉 和仁
Builderな皆様、こんにちは ! 機械学習ソリューションアーキテクトの呉 (@kazuneet) です。前々回の AI を使った読書感想文作成の記事 や 前回の算数ドリルを AI に解かせる記事 は実際にやっていただけたでしょうか ? Builder な皆様はやはり手を動かさないと面白くないですよね。
さて、今までは宿題を hack することばっかりやっていましたが、今回は趣を変えて家事を hack してみたいと思います。前回同様、書き始めたらものすごく長くなってしまったので、今回も 1 行でまとめましょう。
ニンニクをマシた過去からはニンニクマシなレコメンドを得られます。(Garlic in Garlic out)
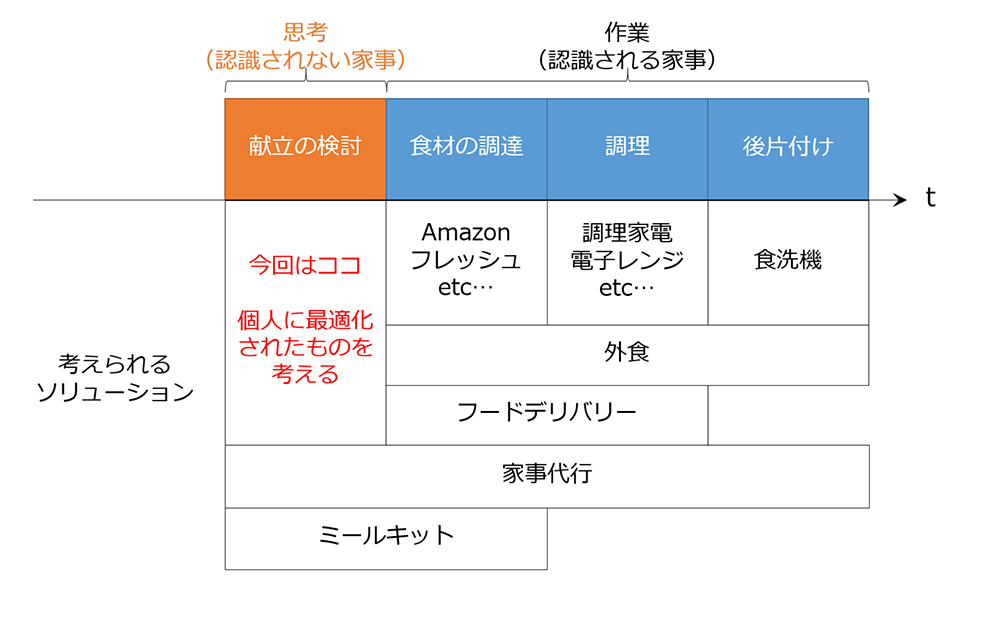
自炊、大変ですか ?
唐突ですが、皆様は自炊していらっしゃいますでしょうか ?
4 月から新生活になり、自炊を始めた人もいるのではないでしょうか。私は結構外食に逃げてしまっていましたが、子供が生まれてから外食も億劫になったので、自炊が増えています。最初は楽しかったのですが、途中から今日は何を作ろうか、を考えるのが面倒くさくなってきました。実際に作る段になればただの作業になるのですが (それももちろん面倒なのですが)、何がいいのかを考えるのはそれはそれはとても億劫ですし、また家事とはなかなか認識されないので苦労が家族に伝わりません。とはいえ、手を抜こうとして、良いとされている病院などの献立をトレースすると、自分が食べたくない献立や嫌いな食べ物が出てくるかもしれませんし、何よりオリジナリティが無くて家族の不評を買うかもしれません。
このような誰も幸せにならない人がやりたくない仕事はこの際 AI にまかせてしまえばいいじゃない ! 一、 エンジニアとして自動化したくなる箇所ですね。メニュー選択をミスして家族が失望しても「い、いや、 AI が選んだから俺は悪くないんだよ…」と AI のせいにできると心理的にもとても楽だと思い、「いっちょやってみっか !」と筆を取りました。
本記事でのスコープは、あくまで献立の検討を楽にする、といったところに焦点をあてておりますが、他にも工夫の余地は下記の通りあると思いますので、ぜひいろいろ試してみたいところです。
目次
1. Amazon Personalize で AI 献立を
1-1. データの準備
2. Amazon Personalize を動かすための構成
3. Amazon Personalize を使うための下準備
3-1. S3 バケットの作成とバケットポリシー作成
3-2. IAM ロールと IAM ポリシー作成
3-3. S3 バケットに csv を配置
4. Amazon Personalize にデータをインポート
4-1. スキーマの作成
4-2. データセットグループの作成
4-3. データセットの作成
4-4. データのインポート
5. Amazon Personalize のソリューションを作成
5-1. ソリューションの作成
5-2. ソリューションバージョンの作成
6. Amazon Personalize でリアルタイムレコメンドを行う
6-1. キャンペーンの作成
6-2. レコメンドの取得
6-3. リアルタイムなイベントを記録
6-4. ダイナミックフィルタを利用する
7. Amazon Personalize でバッチレコメンドを行う
8. おわりに
ご注意
本記事で紹介する AWS サービスを起動する際には、料金がかかります。builders.flash メールメンバー特典の、クラウドレシピ向けクレジットコードプレゼントの入手をお勧めします。
このクラウドレシピ (ハンズオン記事) を無料でお試しいただけます »
毎月提供されるクラウドレシピのアップデート情報とともに、クレジットコードを受け取ることができます。
1. Amazon Personalize で AI 献立を
献立を AI で自動化するにあたって、 Amazon Personalize というレコメンド機能を提供するサービスがマッチしそうです。
Amazon Personalize は EC サイトでよく利用されるのですが、EC サイトを訪問しているユーザーに対して、この商品はどうですか?だったり、この商品を見た人はこの商品も見ています、などといった具合にレコメンドする機能を提供するサービスです。amazon.co.jp などでそのような体験をしたことがある人は多いのではないでしょうか。
Amazon Personalize はユーザーが起こした過去のアクション (購買だったりクリックだったり) を学習し、次にコンバージョンしてくれそうなものをレコメンドするサービスを提供します。
Amazon Personalize の簡単なアップデートを紹介しますと、 推薦フィルタを状況に応じて変更できる dynamic filters が使えるようになりました。従来は、フィルタしなければならない文言は予め Amazon Personalize に登録しておく必要がありました。例えば ビデオオンデマンド (VoD) サービスでは、おそらくタブでいろんなジャンル、アクションやアニメ、コメディなどが別れていることがありますが、そこに一人ひとりに最適化された結果を表示するには、推奨フィルタを各ジャンル毎、アクション用のフィルタ、アニメ用のフィルタ、コメディ用のフィルタを用意しておく必要がありました。dynamic filters が使えることになったことで、ジャンルフィルタを一つ用意しておけば、あとはどのジャンルかを変数のように指定してクエリを投げられるようになっております。後ほどこの機能も使ってみたいと思います。
1-1. データの準備
機械学習にはまずデータが必要です。Amazon Personalize を実行するには最低 Interaction Data と呼ばれるデータが必要で、オプションで Item Data, User Data を使用することができます。これらを csv 形式で用意する必要があります。詳細は以下の通りです。
- Interaction Data
ユーザーの行動履歴データで、誰が、いつ、何のアイテムに対して、何をしたか、を表す履歴データです。EC サイトの場合はユーザーが何の商品をクリックしたのか、だったり、コンバージョンしたのか、またその評価のデータを入れることができます。最低限必要なのは、USER_ID, ITEM_ID, TIMESTAMP です。
- USER_ID : ユーザーを識別するデータです。同じ人だったら必ず同じ値が格納される必要がありますし、別人だったら別の値が格納される必要があります。データベースにユーザマスタテーブルがある場合はユーザーマスタテーブルにあるユーザ ID を引っ張って使うのが良いでしょう。
- ITEM_ID : アイテムを識別するデータです。同じアイテムだったら必ず同じ値が格納される必要がありますし、別のアイテムだったら別の値が格納される必要があります。データベースにアイテムマスタテーブルがある場合はアイテムマスタテーブルにあるアイテム ID を引っ張って使うのが良いでしょう。
- TIMESTAMP : ユーザーがアイテムに対して何らかの Interaction を起こした時間を UNIX 時間形式で記録したデータです。UNIX 時間は耳慣れない方もいらっしゃるかと思いますが、UTC で 1970/1/1 0:00:00 を起点に何秒経過したかを表す形式です。後ほど扱い方についてもご紹介いたします。
- Item Data
価格やジャンルなどのアイテムに関わるメタデータを格納します。必須項目は ITEM_ID です。必須項目は ITEM_ID とも最低 1 つのメタデータです。メタデータが一つもなければ Item Data を入れる意味がなくなってしまいますから Item Data は必ずメタデータをご準備ください。また、一つの項目にメタデータ項目を複数持つ場合があるかと思います。例えば映画であればジャンルという項目でアクションとコメディの 2 属性を持つ場合があります。その場合は csv の形式を維持しつつ、 csv のフィールドの中に複数属性をパイプ区切りで入れる必要があります。…,Action|Comedy…, のような形です。
- User Data
ユーザに関するメタデータを格納します。どんな人なのか、例えば性別や年齢など、Interaction に効きそうなメタデータを格納します。必須項目は USER_ID と最低 1 つのメタデータです。
これらのデータを献立に合わせると例えばこんな形になります。
- Interaction Data
「誰が食べたか」(USER_ID)「何を食べたか」(ITEM_ID)「いつ食べたか」(TIMESTAMP) を記録。また、ここに記録するデータは献立の正解 (= 満足な食事) だったとします。不満足な食事を入れてしまうと、不満足する献立も推薦してしまうため、気をつけてください。 - Item Data
各献立 (USER_ID) と、ジャンル (GENRE) を記録できます。また、ジャンルは料理のジャンルとして、和食、フレンチ、イタリアン、などのどこの料理か、の他に、米、肉、魚などの素材ベースのジャンル、油っぽい、さっぱり、などの形容詞も入れることができますね。 - User Data
上に挙げたようにユーザー毎の性別や年齢の他、身長や体重、また生まれた場所などを入れると、故郷の食事などが反映されやすそうです。
さて、実施に献立をレコメンドする AI を作成するには、まず今までどんな食事をしてきたかのデータが必要なことがわかりました。しかし、私は毎回の食事を記録するような記録マニアではないので、過去の食事を思い出しながら (× でっち上げて) 足りないところは補完しながらデータを作成してみました。ので、フィクションだと思っていただけると幸いです。
さて、このようなデータが準備できました。2020/1/1 から 2020/12/31 までの 366 日 (うるう年) * 3 食分です。
※注意)このような生活をすると健康を害す恐れがあるため、絶対におやめください
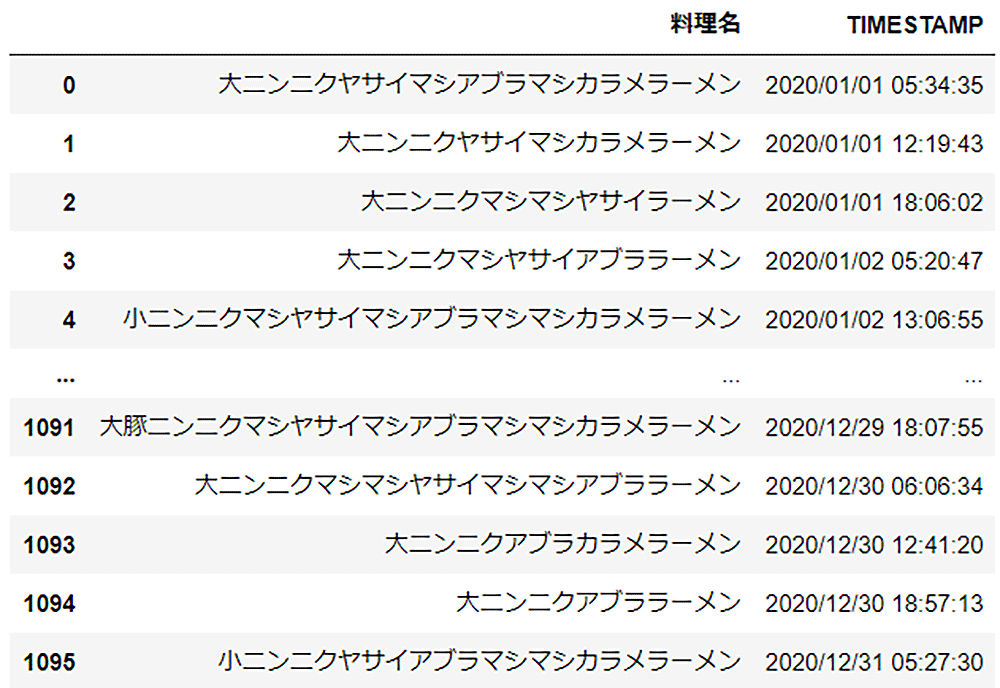
ゲシュタルト崩壊しそうな料理名が並んでいますが、いったんおいておきましょう。
また、どこからともなく献立のマスタデータが空から降って湧いてきました。
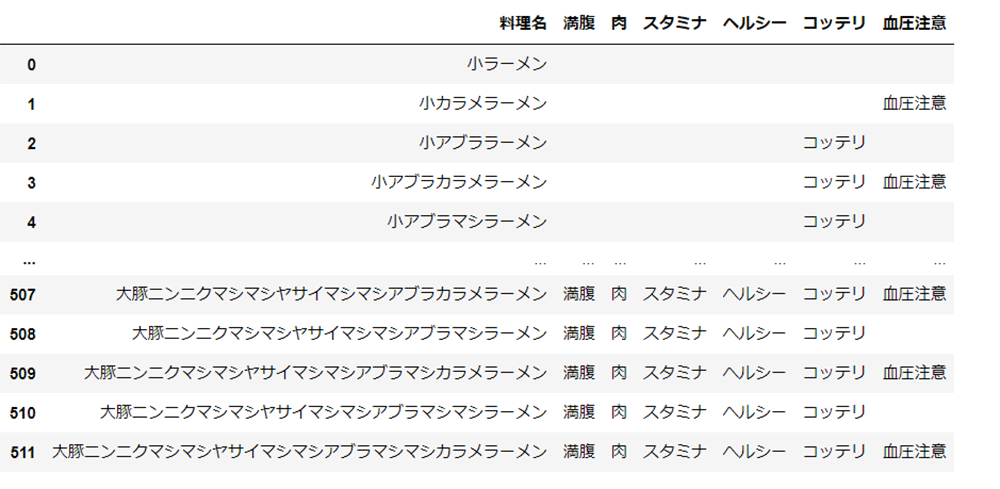
これらを Amazon Personalize が取り込めるようにデータを加工していきましょう。
Python を使って加工していこうと思います。
まずは Interaction Data を作成していきたいと思います。menu2020.csv をベースに作ると良さそうです。menu2020.csv で加工しなければいけないポイントは、下記 3 つです。
- TIMESTAMP は yyyy/MM/dd HH:mm:ss の文字列形式ではなく、UNIX 時刻形式にする必要がある
UNIX 時刻 は皆様ご存知でしょうか。UNIX 時間といったり、UNIX エポックなどと言う場合もございますが、1970 年 1 月 1 日 0 時 0 分 0 秒から経過した秒数で表す時刻の形式です。Python で yyyy/MM/dd HH:mm:ss の文字列を UNIX 時刻形式に変換するのは、一度日時形式を扱える datetime 形式に変換してから timestamp メソッドでUNIX時刻形式( int 型)にするのが良さそうです。 - USER_ID を付与する必要がある
今回は私一人の献立履歴でございますので一律 USER_ID = 1 で埋めてしまいたいのですが、Amazon Personalize は複数のユーザーに対してより良い推薦を行うために USER_ID が最低 25 人分、それぞれ 2 つ以上の Interaction Data が必要になります。ここでは 25 人の人が料理を食べたという想定のもと、適当にダミーデータ 24 人分を USER_ID 2~25 で埋めてしまいましょう。 - 料理名ではなく ID にする必要がある
今回はメニューマスタがあります。ここに全種類のメニューがあるため、この行番号 (に 1 を追加して 1 始まりの 512 終わりにしたもの) を ITEM_ID として使えばよさそうです。RDB で言うところの 結合 (join) をすればできます。今回は Python を使いますので、 pandas の merge メソッドを使って ITEM_ID を引っ張ってきましょう。
方針が立ったので早速実装していきましょう。まずは 1 と 2 の USER_ID 追加を片付けます。
方針が立ったので早速実装していきましょう。まずは 1 と 2 の USER_ID 追加を片付けます。
import pandas as pd
import datetime
# csv ファイルを DataFrame として読み込む
menu2020_df = pd.read_csv('./menu2020.csv')
# USER_ID カラムを追加して、すべて 1 を振る
menu2020_df['USER_ID'] = menu2020_df['料理名'].map(lambda x: str(1))
# yyyy/MM/dd HH:mm:ss 形式を unix 時刻形式の int 型データを作成する
menu2020_df['TIMESTAMP_UNIX'] = menu2020_df['TIMESTAMP'].map(lambda x: int(datetime.datetime.strptime(x, '%Y/%m/%d %H:%M:%S').timestamp()))
# 結果の先頭 5 行表示
menu2020_df.head()
USER_ID と UNIX 時刻を追加
クリックすると拡大します
UNIX 時刻 の整数型データを作成することができました。さて、ここからメニューマスタを利用して ITEM_ID を作成したいと思います。まずは menu_master.csv から ITEM_ID を生成したいと思います。
# csv ファイルを DataFrame として読み込む
item_df = pd.read_csv('./menu_master.csv')
# 行番号に 1 を加算して ITEM_ID を作成
item_df['ITEM_ID'] = item_df.index.values+1
item_df.head()
メニューマスタに ITEM_ID を追加
クリックすると拡大します
ITEM_ID をメニューマスタで作成できたので、Interaction Data 側に結合させましょう。また不要カラムを消すのと、カラムの順番やカラム名を整えてしまいます。併せて先述したとおり Amazon Personalize が 25 人分 × 2 インタラクションが必要なので、追加で 24 人分 * 2 インタラクションのダミーデータも作成してしまいます。
# 結合と必要なカラムを抽出しつつ、カラム名を修正する
interaction_out_df = pd.merge(menu2020_df,item_df,on='料理名')[['USER_ID','ITEM_ID','TIMESTAMP_UNIX']].rename(columns={'TIMESTAMP_UNIX': 'TIMESTAMP'})
# 24 人分の 2 インタラクションデータ。2020/1/1 00:00:00 と 2020/12/31 23:59:59 の日時のデータを ITEM_ID=1 と ITEM_ID=512 で埋める
for i in range(2,26):
interaction_out_df = interaction_out_df.append({'USER_ID': i, 'TIMESTAMP': 1577836800, 'ITEM_ID': i+32}, ignore_index=True)
interaction_out_df = interaction_out_df.append({'USER_ID': i, 'TIMESTAMP': 1609459199, 'ITEM_ID': i+160}, ignore_index=True)
# 結果確認
interaction_out_df.tail()
Interaction Data の完成
これでなにをいつ食べたのか、人間にはさっぱりわからなくなりましたが、Amazon Personalize で Interaction Data として取り込める形式にできました。
続いて Item Data を作成していきましょう。Item Data で加工しなければいけないポイントは下記 2 つです。
- メタデータをパイプつなぎで一つのカラムにまとめる
ひとまとめにしたいメタデータはパイプ( | )つなぎに 1 つのカラムに入れる必要があります。今回は Genre として、満腹・肉・スタミナ・ヘルシー・コッテリ・血圧注意をひとまとめのメタデータとして扱います。 - Interaction Data と同じ ITEM_ID を残す
こちらはさきほど作成した ITEM_ID を残すだけで OK です。
早速コードを書いて実行してみましょう。
# 結合と必要なカラムを抽出しつつ、カラム名を修正する
interaction_out_df = pd.merge(menu2020_df,item_df,on='料理名')[['USER_ID','ITEM_ID','TIMESTAMP_UNIX']].rename(columns={'TIMESTAMP_UNIX': 'TIMESTAMP'})
# 24 人分の 2 インタラクションデータ。2020/1/1 00:00:00 と 2020/12/31 23:59:59 の日時のデータを ITEM_ID=1 と ITEM_ID=512 で埋める
for i in range(2,26):
interaction_out_df = interaction_out_df.append({'USER_ID': i, 'TIMESTAMP': 1577836800, 'ITEM_ID': i+32}, ignore_index=True)
interaction_out_df = interaction_out_df.append({'USER_ID': i, 'TIMESTAMP': 1609459199, 'ITEM_ID': i+160}, ignore_index=True)
# 結果確認
interaction_out_df.tail()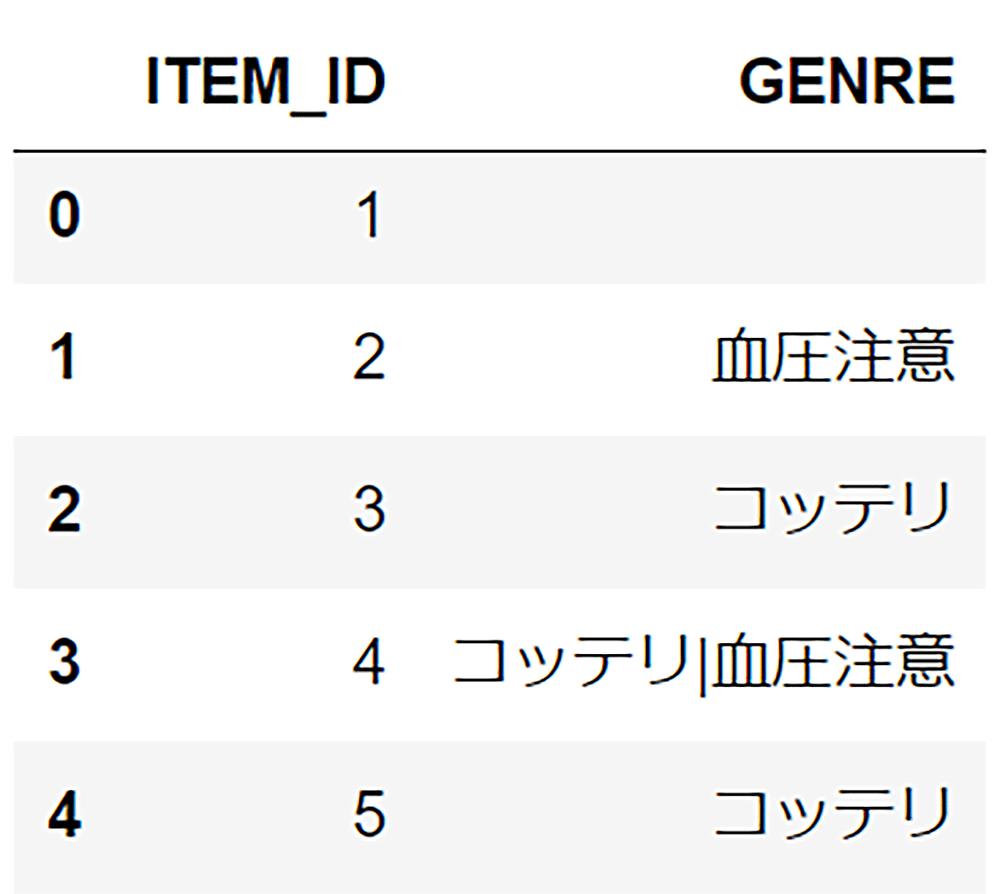
Item Data の完成
最後に User Data ですが、今回はレコメンド対象ユーザーが一人のため作る意味がないので割愛しますが、複数ユーザーのメタデータを登録しておくと、メタデータが近しいユーザーの Interaction Data を反映してくれるので、複数ユーザーで利用する場合はぜひ登録を検討してください。(食べられる量、好みなどを入れておくとよいかもしれません)
2. Amazon Personalize を動かすための構成
今回はこのような構成を取ります。
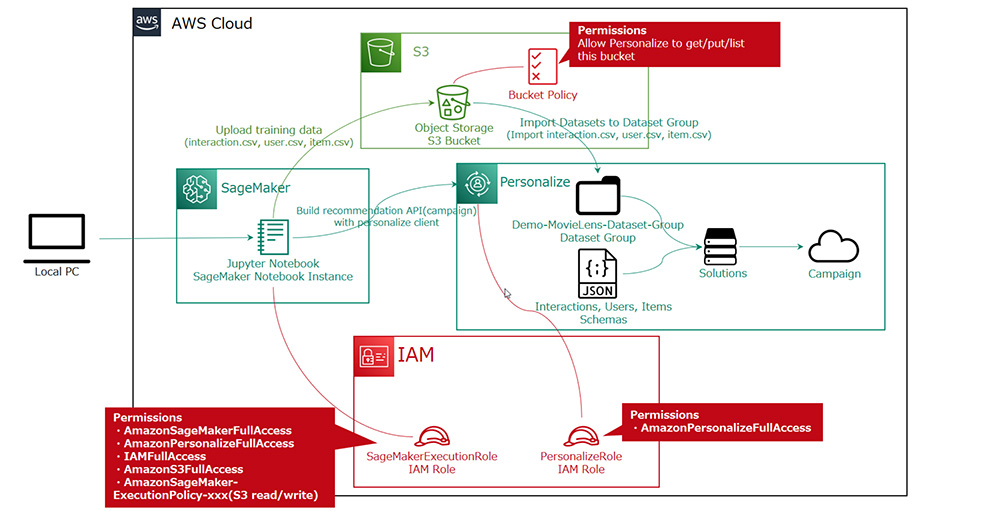
ざっくりした流れは下記の通りです。
- Python が使えて、かつ、適切なポリシーが振られた IAM の設定をしてあるコンピューティングリソースを用意します
今回私は、 SageMaker Notebook という Jupyter Notebook の環境を使いますが、このセットアップについては割愛いたします。AWS アカウントが別途必要ですが、持っている方は こちらの手順書の README.md の記載にある "「サービスを検索する」の下にあるテキストボックスに「Sage」と入力し、表示された「Amazon SageMaker」をクリックします。" の部分以降を参考にしていただければ環境を立ち上げることができます。特に、ロールにポリシーをアタッチする部分 などは忘れずにお願いします。 - Amazon Personalize を使うための下準備
- Amazon S3 バケットとバケットポリシー作成
- IAM ロールと IAM ポリシー作成
- S3 バケットに csv を配置
- Amazon Personalize にデータをインポート
- スキーマの作成
- データセットグループの作成
- データセットの作成
- インポートジョブの実行
- Amazon Personalize のソリューションを作成
- ソリューションの作成
- ソリューションバージョンの作成
- Amazon Personalize でリアルタイムレコメンドを行う
- キャンペーンの作成
- レコメンドの取得
- リアルタイムなイベントを記録
- ダイナミックフィルタを利用する
- Amazon Personalize でバッチレコメンドを行う
- バッチ実行
- 結果取得
3. Amazon Personalize を使うための下準備
3-1. S3 バケットの作成とバケットポリシー作成
さて、先行して Interaction Data と Item Data を作成しましたが、 Amazon Personalize を使うための S3 バケット作成や権限回りの準備をおろそかにしていたため、このタイミングでやってしまいましょう。Amazon Personalize ではデータを S3 においておく必要がございますので、まずは S3 バケット を作成したいと思います。
バケット名は世界で唯一の名前である必要がありますので、実施いただく皆様は世界で唯一の素晴らしいバケット名を設定してください。ただし、必ずバケット名に “personalize” という文言を含めてください。(最初でも途中でも最後でも構いません。理由は後述します。) バケット作成は AWS SDK for Python (Boto3) を利用してやっていきます。必要に応じて boto3 を前もってインストールしてください。また、下記コードに限らず実行時に権限のエラーが出た場合は、別途ポリシーのアタッチなどをお願いします。詳細についてはこちら をご参照ください。バケット作成には create_bucket メソッドを利用します。
import boto3
# S3 を操作する client を生成
s3 = boto3.client('s3')
# 未使用のバケット名を下記シングルクォートの中に入力してください
# ただし personalize という文言を必ずふくめてください
# ↓↓↓↓↓↓↓↓↓↓ 入力 ↓↓↓↓↓↓↓↓↓↓
bucket_name='<Enter the bucket name to be created>'
# ↑↑↑↑↑↑↑↑↑↑ 入力 ↑↑↑↑↑↑↑↑↑↑
# 東京リージョンにバケットを作成
s3.create_bucket(
Bucket=bucket_name,
CreateBucketConfiguration={'LocationConstraint': 'ap-northeast-1'}
)上記のコードがエラーなく実行できていれば OK です。これから Amazon Personalize というサービスから作成した S3 バケットにアクセスできるようにバケットポリシーを設定します。ポリシーは json 形式で記述する必要があるので、Python の Dict 形式で記載したあと変換をかけています。バケットポリシーの設定は put メソッドで実行できます。
import json
# 作成したバケットのバケットポリシーを操作
bucket_policy = boto3.resource('s3').BucketPolicy(bucket_name)
# ポリシーを dict で直書き
policy = {
'Version': '2012-10-17',
'Id': 'PersonalizeS3Bucket AccessPolicy',
'Statement': [
{
'Sid': 'PersonalizeS3BucketAccessPolicy',
'Effect': 'Allow',
'Principal': {
'Service': 'personalize.amazonaws.com'
},
'Action': [
's3:GetObject',
's3:PutObject',
's3:ListBucket'
],
'Resource': [
'arn:aws:s3:::' + bucket_name,
'arn:aws:s3:::' + bucket_name +'/*'
]
}
]
}
# ポリシーを json に変換
policy = json.dumps(policy)
# ポリシーを設定
response = bucket_policy.put(
Policy=policy
)こちらも上記のコードがエラーなく実行できていれば OK です。これで Amazon Personalize から作成した S3 バケットに対してデータの読み書きができるようになりました。
3-2. IAM ロールと IAM ポリシー作成
次に Amazon Personalize を実行するロールを作成します。ロールの作成は AWS IAM サービスで管理されているので、 boto3.client('iam') を実行して IAM のクライアントを生成することで AWS IAM の操作が可能になります。また、Personalize では学習時間が発生するため、念の為ロールのセッション継続時間を 12 時間に設定しています。Amazon Personalize の機能をすべて使えるよう、 AmazonPersonalizeFullAccess をアタッチしておきます。アタッチには attach_role_policy メソッドを使用します。
ここで注意が一つあります。バケット名に personalize という文言を含める必要がある、と前に記載しました。AmazonPersonalizeFullAccess ポリシーは personalize という文言が含まれている S3 のバケットのみに操作ができる権限が割り当てられているので、personalize という文言がバケット名に含まれている必要があります。
iam = boto3.client('iam')
# Personalize でロールを引き受けられるよう Assume Role Document を直書き
assume_role_policy_document = {
'Version': '2012-10-17',
'Statement': [{'Sid': '','Effect': 'Allow','Principal': {'Service': 'personalize.amazonaws.com'},'Action': 'sts:AssumeRole'}]
}
# ロールを作成
response = iam.create_role(
RoleName = 'MenuPersonalizeRole',
AssumeRolePolicyDocument = json.dumps(assume_role_policy_document),
MaxSessionDuration=3600*12 # 12時間
)
# 後で使えるよう、ロールの名前とロールの Arn を変数に格納
role_arn = response['Role']['Arn']
role_name = response['Role']['RoleName']
# AmazonPersonalizeFullAccessを作成したロールにアタッチ
response = iam.attach_role_policy(RoleName=role_name,PolicyArn='arn:aws:iam::aws:policy/service-role/AmazonPersonalizeFullAccess')3-3. S3 バケットに csv を配置
さて、作成した Interaction Data と Item Data からレコメンドを行うために、学習をしたいのですが、 Amazon Personalize では学習データを S3 に配置する必要があります。早速先程作成したバケットにデータを配置しましょう。csv 形式であるため、pandas のデータフレームを csv 形式に出力して、S3 にアップロードします。boto3 で S3 にアップロードする方法は多数あるのですが、ここでは生成済の s3 client にある upload_file というメソッドを使っていきたいと思います。
# interaction と item を csv 形式に出力
interaction_out_df.to_csv('interaction.csv',index=False)
item_out_df.to_csv('item.csv',index=False)
# S3 にアップロード
s3.upload_file('./interaction.csv', bucket_name, 'interaction.csv')
s3.upload_file('./item.csv', bucket_name, 'item.csv')ここまでエラーが発生せずにできればいよいよ Amazon Personalize を動かしていきます。
4. Amazon Personalize にデータをインポート
さて、前置きが長くなりました、ここから Amazon Personalize を操作していきます。まずは操作するための client インスタンスを作成します。
# Amazon Personalize の Client インスンタンスを生成。この client インスタンスが持つメソッドを利用して Amazon Personalize を操作する。
personalize = boto3.client('personalize')4-1. スキーマの作成
データをインポートするにあたって、 Amazon Personalize でスキーマ定義という準備が必要です。各カラムがどんな型 (文字列、数値など) でどんな意味を持つのかなどを指定する必要があります。今回は 3 つのカラムを Interaction Data では使用しており、それぞれ USER_ID, ITEM_ID が文字列型、 TIMESTAMP が数値型の設定を行います。スキーマは json 形式で定義する必要があるため、Python の dict を利用して作成してから json に変換したいと思います。スキーマの作成には create_schema というメソッドを利用します。
# スキーマ定義
interaction_schema = {
'type': 'record',
'name': 'Interactions',
'namespace': 'com.amazonaws.personalize.schema',
'fields': [
{
'name': 'USER_ID',
'type': 'string'
},
{
'name': 'ITEM_ID',
'type': 'string'
},
{
'name': 'TIMESTAMP',
'type': 'long'
}
],
'version': '1.0'
}
# スキーマ作成
create_interaction_schema_response = personalize.create_schema(
name = 'menu-interaction-schema',
schema = json.dumps(interaction_schema)
)
# スキーマの識別子(Arn)を変数に格納
interaction_schema_arn = create_interaction_schema_response['schemaArn']
# 結果確認
print(json.dumps(create_interaction_schema_response, indent=2))同様に、Item Data もスキーマを作成します。
# スキーマ定義
item_schema = {
'type': 'record',
'name': 'Items',
'namespace': 'com.amazonaws.personalize.schema',
'fields': [
{
'name': 'ITEM_ID',
'type': 'string'
},
{
'name': 'GENRE',
'type': ['string','null'],
'categorical': True
}
],
'version': '1.0'
}
# スキーマ作成
create_item_schema_response = personalize.create_schema(
name = 'menu-item-schema',
schema = json.dumps(item_schema)
)
# スキーマの識別子(Arn)を変数に格納
item_schema_arn = create_item_schema_response['schemaArn']
# 結果確認
print(json.dumps(create_item_schema_response, indent=2))また、前述したとおり、 Amazon Personalize ではユーザーのメタデータを入れることができる User Data というのも定義してインポートすることが可能ですが、今回は私が個人で利用しますので User Data の準備は割愛します。ただし他人のインタラクションを自身のレコメンドに反映させたほうがより良いレコメンドができるのでぜひトライしていただければと思います。
4-2. データセットグループの作成
スキーマを作成したので、次はデータグループの作成を行います。
スキーマはあくまでこのようなデータをインポートする、という定義ですので、そのデータを束ねる群としてデータグループを作成する必要があります。データグループの作成には create_dataset_group というメソッドを利用します。
import time
# データセットグループの作成
create_dataset_group_response = personalize.create_dataset_group(
name = 'menu-dataset-group'
)
# データセットグループの識別子(Arn)を変数に格納
dataset_group_arn = create_dataset_group_response['datasetGroupArn']
print(json.dumps(create_dataset_group_response, indent=2))
# データセットグループの状況を確認する
status = None
max_time = time.time() + 3*60*60 # 3 hours
while time.time() < max_time:
# 処理の状況を確認する
describe_dataset_group_response = personalize.describe_dataset_group(
datasetGroupArn = dataset_group_arn
)
status = describe_dataset_group_response['datasetGroup']['status']
# 処理が終わっていたら結果を表示してループを抜ける
if status == 'ACTIVE' or status == 'CREATE FAILED':
print('!')
print(f'CreateDatasetGroup: {status}')
break
# 処理が進行中の場合は、sleep を挟んでループする
else:
print('.',end='')
time.sleep(1)こちらは出力結果の最後に ACTIVE と表示されていれば OK です。create_schema との違いで言うと、 create_dataset_group は非同期メソッドであり、即座に結果を返してきます。しかし裏側では作成が継続しているため、終わったかどうかを判断するためには別途作成処理の状態を確認する必要があります。
create_dataset_group の進行状況は describe_dataset_group というメソッドの返り値から確認できます。上記の処理では、作成がおわっていなかったら 1 秒の sleep をはさんで再度チェックする、という処理にしております。この処理は通常 10 秒程度で完了します (実行環境などに依存します)。以降、 Amazon Personalize のメソッドでは非同期のメソッドがいくつか出てきますので、このような処理を使っていこうと思います。
ただし、create_xxx という処理 (今回は create_dataset_group) は、menu-dataset-group という dataset_group を作るため、もう一度実行しようとすると、already exist というエラーが発生します。再度実行したい場合は delete_dataset_group というメソッドを使用して、削除してから再度実行してください。これは全ての create_xxx というメソッドに当てはまります。
4-3. データセットの作成
csv をインポートするのにもう一つ最後の準備として、データセットの作成を行う必要があります。csv を受け付ける箱としてデータセットを作成する必要があり、最初に作成したスキーマとをここで利用します。というのも Amazon Personalize では日々データが増えていく可能性がある (というよりそのケースのほうが多い) ので、csv が日々増えていくことを考慮し、csv を受け入れる箱が必要なためです。データセット作成には create_dataset メソッドを利用します。先程作成したデータセットグループを指定します。
Interaction Data と Item Data のデータセットをまとめて作成します。
# Interaction Data のデータセット作成
interaction_dataset_type = 'Interactions'
create_interaction_dataset_response = personalize.create_dataset(
datasetType = interaction_dataset_type, # データセットのタイプ
datasetGroupArn = dataset_group_arn, # データセットグループの識別子(Arn)
name = 'menu-interactions', # データセットの一意な名前
schemaArn = interaction_schema_arn # 使用するスキーマの識別子(Arn)
)
# データセットの識別子(Arn)を変数に格納
interaction_dataset_arn = create_interaction_dataset_response['datasetArn']
# 結果確認
print(json.dumps(create_interaction_dataset_response, indent=2))
# Item Data のデータセット作成
item_dataset_type = 'Items'
create_item_dataset_response = personalize.create_dataset(
datasetType = item_dataset_type,
datasetGroupArn = dataset_group_arn,
name = 'menu-item',
schemaArn = item_schema_arn
)
# データセットの識別子(Arn)を変数に格納
item_dataset_arn = create_item_dataset_response['datasetArn']
# 結果確認
print(json.dumps(create_item_dataset_response, indent=2))こちらもエラーが発生しなければ OK です。
4-4. データのインポート
ようやく csv を取り込む準備ができましたので、データをインポートします。データのインポートは非同期メソッドの create_dataset_import_job を利用します。先程作成したデータセット、アップロードした csv の URI 、ロールを指定して実行します。
# Interaction Data インポートジョブ
create_interaction_dataset_import_job_response = personalize.create_dataset_import_job(
jobName = 'menu-interaction-dataset-import-job', # 一意なインポートジョブの名前
datasetArn = interaction_dataset_arn,
dataSource = {
'dataLocation': f's3://{bucket_name}/interaction.csv' # インポートする csv のURI
},
roleArn = role_arn # インポートジョブを実行するロールの識別子(Arn)
)
# Interaction Data インポートジョブの識別子(Arn)を変数に格納
interaction_dataset_import_job_arn = create_interaction_dataset_import_job_response['datasetImportJobArn']
# Interaction Data インポートジョブのメソッドの返り値を確認
print(json.dumps(create_interaction_dataset_import_job_response, indent=2))
# Item Data インポートジョブ
create_item_dataset_import_job_response = personalize.create_dataset_import_job(
jobName = 'menu-item-dataset-import-job',
datasetArn = item_dataset_arn,
dataSource = {
'dataLocation': f's3://{bucket_name}/item.csv'
},
roleArn = role_arn
)
# Item Data インポートジョブの識別子(Arn)を変数に格納
item_dataset_import_job_arn = create_item_dataset_import_job_response['datasetImportJobArn']
# Item Data インポートジョブのメソッドの返り値を確認
print(json.dumps(create_item_dataset_import_job_response, indent=2))create_dataset_import_job は非同期メソッドのため、実行が終わるまで待つ必要があるので、先程と同じような sleep を入れたコードで完了まで待ちます。今回使うメソッドは describe_dataset_import_job です。だいたい 15 ~ 20 分程度で完了するかと思います。
# Interaction Data インポートジョブの完了待機
status = None
max_time = time.time() + 3*60*60 # 3 hours
while time.time() < max_time:
describe_dataset_import_job_response = personalize.describe_dataset_import_job(
datasetImportJobArn = interaction_dataset_import_job_arn
)
dataset_import_job = describe_dataset_import_job_response['datasetImportJob']
status = dataset_import_job['status']
if status == 'ACTIVE' or status == 'CREATE FAILED':
print('!')
print(f'LatestDatasetImportJobRun: {status}')
break
else:
print('.',end='')
time.sleep(60)
# Item Data インポートジョブの完了待機
status = None
max_time = time.time() + 3*60*60 # 3 hours
while time.time() < max_time:
describe_dataset_import_job_response = personalize.describe_dataset_import_job(
datasetImportJobArn = item_dataset_import_job_arn
)
dataset_import_job = describe_dataset_import_job_response['datasetImportJob']
status = dataset_import_job['status']
if status == 'ACTIVE' or status == 'CREATE FAILED':
print('!')
print(f'LatestDatasetImportJobRun: {status}')
break
else:
print('.',end='')
time.sleep(5)こちらも最後に ACTIVE と表示されれば OK です。また、マネジメントコンソールからも状況を確認できます。Amazon Personalize の画面の左のペインから、Datasets をクリックすると、インポートの状況を確認することが可能です。(下図では Active となり完了状況を表しています)。以降のほとんどの操作はマネジメントコンソールで確認できますので、ぜひ実行しながら確認してみてください。

マネジメントコンソールでの Datasets の確認
クリックすると拡大します

マネジメントコンソールでのインポートジョブの確認
クリックすると拡大します
5. Amazon Personalize のソリューションを作成
5-1. ソリューションの作成
さて、データが揃ったので、ここからは機械学習で言うところの学習をしていきます。学習を行うためには、アルゴリズムを選択する必要があります。Amazon Personalize でアルゴリズムを指す言葉はレシピと言います。使用できるアルゴリズムの識別子(Arn) 一覧は list_recipes メソッドで取得できます。
list_recipes_response = personalize.list_recipes()
recipe_arns = {}
for recipe in list_recipes_response['recipes']:
recipe_arns[recipe['recipeArn'].split('/')[-1]] = recipe['recipeArn']
for key in recipe_arns.keys():
print(key + ' -> ' + recipe_arns[key])2021 年 3 月現在では下記のようなレシピを利用することができます。
aws-hrnn -> arn:aws:personalize:::recipe/aws-hrnn
aws-hrnn-coldstart -> arn:aws:personalize:::recipe/aws-hrnn-coldstart
aws-hrnn-metadata -> arn:aws:personalize:::recipe/aws-hrnn-metadata
aws-personalized-ranking -> arn:aws:personalize:::recipe/aws-personalized-ranking
aws-popularity-count -> arn:aws:personalize:::recipe/aws-popularity-count
aws-sims -> arn:aws:personalize:::recipe/aws-sims
aws-user-personalization -> arn:aws:personalize:::recipe/aws-user-personalizationざっくり説明しますと、
- *hrnn* のアルゴリズムは現在非推奨です (古いアルゴリズムです)
- aws-personalized-ranking のアルゴリズムは、ユーザーに複数薦めたい ITEM があった場合に、どの順番でコンバージョンする可能性が高いか (今回のケースでいうと、薦めたい献立が複数あったときにどの献立を選んでくれる可能性が高いかのランキング) を返すためのアルゴリズムです。
- aws-popularity-count のアルゴリズムは人気順を返してくれます。
- aws-sims は似た商品を返してくれます。EC サイトで「これを見た人はこの商品も見ています」というリンクを見たことがある方も多いかとおもいますが、そのような機能を提供してくれます。
今回のユースケースで言えば、このラーメンを食べた人はこのラーメンもオススメです、といったカロリーマシマシな感じになるか、あるいはデザートも一緒にデータに登録しておくことで、このラーメンに合うデザート、といったことができるかと思います。 - aws-user-personalization はユーザごとにオススメする ITEM を出力します。
詳細は レシピのリンク からご確認ください。
今回はユーザーごとに (といっても実質私一人ですが) 献立を出力してほしいので、 aws-user-personalization を使っていきたいと思います。
使用するレシピが決まったので、そのレシピを使って学習していきたいと思います。Amazon Personalize では学習して出来上がるモデルのことをソリューションと言います。さっそくソリューションを作成しましょう。ソリューションの作成には create_solution メソッドを利用します。引数に aws-user-personalization の識別子 (Arn)と、 データセットグループの識別子 (Arn) を指定します。ソリューション作成や後段の処理でハイパーパラメータを設定することもできますが、今回は何も設定せずに全てデフォルトにします。
# aws-user-personalization を用いたソリューションの作成
user_personalization_create_solution_response = personalize.create_solution(
name = 'menu-user-personalization', # ソリューションの一意な名前
datasetGroupArn = dataset_group_arn, # 使用するデータセットグループの識別子
recipeArn = recipe_arns['aws-user-personalization']) # aws-user-personalization レシピの識別子
# solution の識別子(Arn)を変数に格納
user_personalization_solution_arn = user_personalization_create_solution_response['solutionArn']
# 結果確認
print(json.dumps(user_personalization_create_solution_response, indent=2))5-2. ソリューションバージョンの作成
実は create_solution を実行したからといって学習が始まったわけではありません。機械学習は理想的には新着データがあるたびに再学習を行うのが理想です。Amazon Personalize においても、何度も再学習をすることを想定して、学習のたびに出来上がるモデル達をソリューションバージョンとして扱います。ソリューションは「このデータセットグループでこのアルゴリズムを使いなさい」と、宣言するもので、ソリューションバージョンが実際のモデルに相当するものです。ソリューションバージョンの作成を実行することがモデルの学習に相当する行為であり、そのアウトプットとしてモデルが出来上がるイメージです。
ソリューションバージョンの作成には create_solution_version という非同期メソッドを利用します。
ソリューションバージョンの作成は学習が走り、40 分程度がかかりますので、完了するまで待つ処理を入れておきます。ソリューションバージョンの作成状況確認は describe_solution_version を利用します。
# ソリューションバージョンの作成
user_personalization_create_solution_version_response = personalize.create_solution_version(
solutionArn=user_personalization_solution_arn
)
# ソリューションバージョンの識別子(Arn)を変数に格納
user_personalization_solution_version_arn = user_personalization_create_solution_version_response['solutionVersionArn']
# 結果確認
print(json.dumps(user_personalization_create_solution_version_response, indent=2))
# ソリューションバージョンの作成が完了するのを待つ
status = None
max_time = time.time() + 3*60*60 # 3 hours
while time.time() < max_time:
describe_solution_version_response = personalize.describe_solution_version(
solutionVersionArn = user_personalization_solution_version_arn
)
status = describe_solution_version_response['solutionVersion']['status']
if status == 'ACTIVE' or status == 'CREATE FAILED':
print('!')
print(f'user-personalize solution version : {status}')
break
else:
print('.',end='')
time.sleep(60)こちらも ACTIVE と出力されれば OK です。
6. Amazon Personalize でリアルタイムレコメンドを行う
ソリューションバージョンの作成が完了したら、実際にレコメンドしてみます。レコメンドはリアルタイムレコメンドとバッチレコメンドがあり、それぞれ特徴があります。
リアルタイムレコメンドはレコメンドを提供する API を常時立ち上げっぱなしにしておくことで、リアルタイムにレコメンドすることができます。一方バッチレコメンドは API を立ち上げておくのではなく、S3 に保存したデータに対してレコメンド処理を一括で行います。リアルタイムのほうは EC サイトなどでリアルタイムにレコメンドしたい場合、バッチ推論はユーザに一括メール配信などに使うことが多いです。
今回は両方のユースケースを試してみましょう。
6-1. キャンペーンの作成
リアルタイムレコメンドにあたってはキャンペーンと呼ばれるものを作成する必要があります。前述したとおり常時使えるレコメンド API のようなものです。キャンペーンの作成には create_campaign メソッドを利用します。引数に先程作成したソリューションバージョンの識別子 (Arn) の他、minProvisionedTPS を指定する必要があります。minProvisionedTPS とは 1 秒間に最低限さばけるトランザクションの量です。Amazon Personalize はオートスケーリングに対応しているため、レコメンドの負荷が高くなると、自動でスケールするようになっていますが、スケールのスピードは秒単位で変えられるわけではないため、最小限確保しておくコンピュートリソースです。とはいえ、今回は一人つ使うので 1 日 3 回使うことを想定しているため、もちろん最小値の 1 minProvisionedTPS で十分です。キャンペーンの作成に 10 分程度の時間がかかります。キャンペーンの作成状況の確認には、describe_campaign メソッドを利用します。
# キャンペーン の作成
create_user_personalization_campaign_response = personalize.create_campaign(
name = 'menu-campaign-user-personalization',
solutionVersionArn = user_personalization_solution_version_arn, # ソリューションバージョンの識別子(Arn)
minProvisionedTPS = 1, # 1 秒間にさばける transaction の数
)
# キャンペーンの識別子(Arn)を変数に格納
user_personalization_campaign_arn = create_user_personalization_campaign_response['campaignArn']
# 結果確認
print(json.dumps(create_user_personalization_campaign_response, indent=2))
# 処理結果待ち
status = None
max_time = time.time() + 3*60*60 # 3 hours
while time.time() < max_time:
describe_campaign_response = personalize.describe_campaign(
campaignArn = user_personalization_campaign_arn
)
status = describe_campaign_response['campaign']['status']
if status == 'ACTIVE' or status == 'CREATE FAILED':
print('!')
print(f'LatestDatasetImportJobRun: {status}')
break
else:
print('.',end='')
time.sleep(60)最後に ACTIVE と表示されれば OK です。
6-2. レコメンドの取得
キャンペーン作成が完了したので、レコメンドをしてみます。レコメンドは今まで使っていた personalize のクライアントではなく、動いている personalize のサービスを操作するための personalize-runtime クライアントを利用します。personalize-runtime にある get_recommendations というメソッドを使うことでレコメンドを取得できます。キャンペーンの識別子 (Arn) と、USER_ID を指定することで利用できます。今回はもちろん USER_ID は 1 です。
# 稼働済みの Amazon Personalize のサービスを利用するためのpersonalize-runtime クライアントインスタンスを生成
personalize_runtime = boto3.client('personalize-runtime')
# レコメンド取得
get_recommendations_response = personalize_runtime.get_recommendations(
campaignArn = user_personalization_campaign_arn,
userId = '1'
)
# 結果確認
print(json.dumps(get_recommendations_response,indent=2))すると下記のようなレスポンスを取得できます。
{
"ResponseMetadata": {
"RequestId": "1e0ce922-f9f8-4064-ad3a-d649a261aaf4",
"HTTPStatusCode": 200,
"HTTPHeaders": {
"content-type": "application/json",
"date": "Fri, 05 Mar 2021 03:00:21 GMT",
"x-amzn-requestid": "1e0ce922-f9f8-4064-ad3a-d649a261aaf4",
"content-length": "1415",
"connection": "keep-alive"
},
"RetryAttempts": 0
},
"itemList": [
{
"itemId": "197",
"score": 0.0415981
},
{
"itemId": "235",
"score": 0.0343118
},
…(以下略)ItemList というキーにレコメンドする ITEM_ID をレコメンドする度合 (score) の降順に取得できることがわかります。(デフォルトで 25 件、最大で 500 まで増やせます) 食事はこのままだと、メニューがわからないので、メニュー名に変換する処理を入れつつ上位 1 位のみを出力するようにしてみました。
import numpy as np
item_list = get_recommendations_response['itemList']
title_list = [item_df.loc[item_df['ITEM_ID'] == np.int(item['itemId'])].values[0][0] for item in item_list]
print(title_list[0],item_list[0])下記のような出力が出ました。
小豚ニンニクマシアブラマシラーメン {'itemId': '197', 'score': 0.0415981}言われてみれば豚とニンニクとアブラがたべたくなってきました。
(注:学習結果によって違う結果が出力される可能性がありますのでご留意ください)
6-3. リアルタイムなイベントを記録
今回のこの記事のストーリーを設定しそこねていたのですが、これからランチだったとします。ランチに、大豚ニンニクマシマシヤサイマシマシアブラマシマシカラメラーメンを食べたとします。夕飯にもまたレコメンドしたいのですが、何回 get_recommendations を呼び出してもまったく同じ結果が出るので、また大豚ニンニクマシマシヤサイマシマシアブラマシマシカラメラーメンを食べるハメになります。さすがに胃がつらそうです。お昼に大豚ニンニクマシマシヤサイマシマシアブラマシマシカラメラーメンを食べたことを Amazon Personalize に教えてあげて別のものをレコメンドしてほしくなりました。そんなときにはイベントの記録をすることで、レコメンドの結果を動的に変化させることが可能です (一般的には EC サイトにおいて、ある購買行動を起こしたらそれを記録することでまた違うものをレコメンドするイメージです)。
イベントの記録には イベントトラッカーを作成し、そこにイベントを put していくことで実現できます。
まずイベントトラッカーを作成します。イベントトラッカーの作成には create_event_tracker メソッドを利用します。10 秒程度かかります。イベントトラッカーの作成状況の確認には、describe_event_tracker メソッドを利用します。
# イベントトラッカーの作成
create_event_tracker_response = personalize.create_event_tracker(
datasetGroupArn = dataset_group_arn,
name = 'menu-event-tracker'
)
# イベントトラッカーの識別子(Arn)を変数に格納
event_tracker_arn = create_event_tracker_response['eventTrackerArn']
# 結果確認
print(json.dumps(create_event_tracker_response, indent=2))
# 出来上がるまで待つ
status = None
max_time = time.time() + 3*60*60 # 3 hours
while time.time() < max_time:
describe_event_tracker_response = personalize.describe_event_tracker(
eventTrackerArn = event_tracker_arn
)
status = describe_event_tracker_response["eventTracker"]["status"]
if status == "ACTIVE" or status == "CREATE FAILED":
print('!')
print(f'status:{status}')
break
print('.',end = '')
time.sleep(5)
# イベントトラッカーの ID を変数に格納
tracking_id = create_event_tracker_response['trackingId']
print(f'tracking_id: {tracking_id}')こちらも ACTIVE と出力されれば OK です。
さて、先程の小豚ニンニクマシアブラマシラーメンを食べたと仮定して、イベントトラッカーにデータを登録します。イベントの記録にはpersonalize-events クライアントの put_events というメソッドを使って登録します。ただし、メニューの名前ではなく、ITEM_ID を登録します。また、時刻など必要な値も合わせて入力します。
import uuid
personalize_events = boto3.client('personalize-events')
session_id = str(uuid.uuid4())
personalize_events.put_events(
trackingId = tracking_id, # イベントトラッカーの ID
userId = '1', # 私の USER_ID
sessionId = session_id, # Web システムなどでログイン前のデータと紐付けるときに使う。今回はなんでもいいのでユニークな値を入れる
eventList = [
{
"sentAt": datetime.datetime(2021, 4, 1, 12, 0, 0, 0), # 日時を入れる
"eventType": "RATING",
"properties": json.dumps(
{
'itemId': item_list[0]['itemId'] # 先程のレコメンド 1 位の ITEM_ID
}
)
}
]
)こちらもエラーが発生していなければ OK です。さて、もう一回レコメンドしてみましょう。
# レコメンド取得
get_recommendations_response = personalize_runtime.get_recommendations(
campaignArn = user_personalization_campaign_arn,
userId = '1'
)
# 結果確認
item_list = get_recommendations_response['itemList']
title_list = [item_df.loc[item_df['ITEM_ID'] == np.int(item['itemId'])].values[0][0] for item in item_list]
print(title_list[0],item_list[0])以下の出力を得られます。(学習によって結果が変わる点ご留意ください)
小豚ニンニクマシアブラマシラーメン {'itemId': '197', 'score': 0.0417259}put_events する前とレコメンド結果が変わっていませんが、スコアが 0.0415981 → 0.0417259 に増えています。中毒性の高いメニューのため、スコアがドンドンあがっていくのは実感と近いですね・・・(恐ろしや・・・)
6-4. ダイナミックフィルタを利用する
さて、また小豚ニンニクマシアブラマシラーメンを食べるのはしんどくなってきました。ここは一つフィルタをかませて除外しておきたいところです。Amazon Personalize では推論時にフィルタをかませることができます。
まずはフィルタを作成しましょう。create_filter メソッドで作成することができます。GENRE に対してフィルタをかませるため、そのようなクエリ (filterExpression) を用意した上で、create_filter を実行します。30 秒程度の時間がかかります。フィルタの作成状況の確認には、describe_filter メソッドを利用します。
# GENRE でフィルタするクエリを作成
filter_expression = 'INCLUDE ItemID WHERE Items.GENRE IN ($GENRE)'
# フィルタを作成
create_filter_response = personalize.create_filter(
datasetGroupArn = dataset_group_arn,
filterExpression = filter_expression,
name = 'genre_filter_action'
)
# フィルタの識別子(Arn)を変数に格納
filter_arn = create_filter_response['filterArn']
# 結果確認
print(json.dumps(create_filter_response, indent=2))
# フィルタが出来上がるのを待つ
status = None
max_time = time.time() + 3*60*60 # 3 hours
while time.time() < max_time:
describe_filter_response = personalize.describe_filter(
filterArn = filter_arn
)
status = describe_filter_response["filter"]["status"]
print('.',end='')
if status == "ACTIVE" or status == "CREATE FAILED":
print('!')
print(f"Filter: {status}")
break
time.sleep(5)エラーが発生しなければ OK です。フィルタを通してレコメンドしてみましょう。今日は血圧注意な料理を食べたくなったので、血圧注意なフィルタをかませてみます。フィルタするには get_recommendations メソッドの引数に フィルタの識別子とその値を dict 形式で渡します。
# フィルタつきのレコメンド取得
get_recommendations_response = personalize_runtime.get_recommendations(
campaignArn = user_personalization_campaign_arn,
userId = '1',
filterArn = filter_arn, # フィルタの識別子(Arn)
filterValues={ "GENRE": "\"血圧注意\""} # 血圧注意のみに絞る
)
item_list = get_recommendations_response['itemList']
title_list = [item_df.loc[item_df['ITEM_ID'] == np.int(item['itemId'])].values[0][0] for item in item_list]
print(title_list[0],item_list[0])下記のような結果が出ました。
小ニンニクマシアブラカラメラーメン {'itemId': '68', 'score': 0.0298023}たしかにもともとレコメンドしていたものに対して、カラメだけ追加してくる名采配・・・! よくわかってるな、などとうなるばかりです。
7. Amazon Personalize でバッチレコメンドを行う
さて、ここまでリアルタイムレコメンドを行ってきましたが、献立についてはリアルタイムにレコメンドしてもよいですが、決まった時間にメールとかで通知してくれてもよさそうです。
Amazon Personalize にはバッチレコメンドという方法があり、リアルタイムに結果はいらない場合にバッチ処理でレコメンドする方法があるので、一括でメールなどで色んな人にばらまくときには有用です。今回ユーザーは一人ですが、バッチ推論もためしておきましょう。
7-1. バッチ実行
バッチ推論するにはあらかじめレコメンドしたい人を json 形式で S3 に配置しておく必要があります。さくっと S3 に配置しましょう。
# jsonlines モジュールの読み込み。必要に応じて pip install してください
import jsonlines
# 今回は私(USER_ID=1)のみレコメンド
user_list = []
user_list.append({"userId": "1"})
# json ファイルを書き込み
batch_inference_input_file_name = 'batch_infrence_input.json'
with jsonlines.open(batch_inference_input_file_name, mode='w') as writer:
writer.write_all(user_list)
# S3 にアップロード
s3.upload_file(f'./{batch_inference_input_file_name}', bucket_name, batch_inference_input_file_name)さて、json ファイルを S3 に配置できたので、バッチレコメンドをしていきたいと思います。
バッチレコメンドには create_batch_inference_job というメソッドがあるので、それを利用します。入力ファイルと出力パスなどを指定します。30 分ほどかかります。またバッチレコメンドジョブの状況確認には、describe_batch_inference_job を利用します。
# バッチレコメンドジョブの作成
create_batch_inference_job_response = personalize.create_batch_inference_job (
solutionVersionArn = user_personalization_solution_version_arn,
jobName = "menu-batch-recommendation-job",
roleArn = role_arn,
jobInput =
{"s3DataSource": {"path": f's3://{bucket_name}/{batch_inference_input_file_name}'}},
jobOutput =
{"s3DataDestination": {"path": f's3://{bucket_name}/batch-inference-output/'}},
numResults = 100
)
# バッチレコメンドジョブの識別子(Arn)を変数に格納
batchInferenceJobArn = create_batch_inference_job_response['batchInferenceJobArn']
# 結果確認
print(json.dumps(create_batch_inference_job_response, indent=2))
# バッチレコメンドジョブの完了を待つ
status = None
max_time = time.time() + 3*60*60 # 3 hours
while time.time() < max_time:
describe_batch_inference_job_response = personalize.describe_batch_inference_job(
batchInferenceJobArn = batchInferenceJobArn
)
status = describe_batch_inference_job_response["batchInferenceJob"]["status"]
if status == "ACTIVE" or status == "CREATE FAILED":
print('!')
print(f"status: {status}")
break
else:
print('.',end='')
time.sleep(60)こちらも最後 ACTIVE と表示されれば OK です。
7-2. 結果取得
バッチレコメンド結果は S3 に格納されます。格納されるパスは describe_batch_inference_job メソッドの返り値に格納されているので download_file メソッドでダウンロードします。
# ファイル名
batch_inference_file_name = 'batch_infrence_input.json.out'
# S3 の URI を取得
output_path = describe_batch_inference_job_response['batchInferenceJob']['jobOutput']['s3DataDestination']['path'] + batch_inference_file_name
# ダウンロード
s3.download_file(bucket_name, '/'.join(output_path.split('/')[3:]), batch_inference_file_name)最後に中身を確認してみましょう。json の中に ITEM_ID と スコアが入っています。今回はスコアが 1 位の結果だけを見てみましょう。
with open(batch_inference_file_name,'rt') as f:
data = json.loads(f.read())
print(item_df.loc[item_df['ITEM_ID'] == int(data['output']['recommendedItems'][0])]['料理名'].values[0],data['output']['recommendedItems'][0],data['output']['scores'][0])小豚ニンニクマシアブラマシラーメン 197 0.0210048先程と同じ結果が出ました。このように食事の時間に合わせてバッチレコメンドするのも良いですね !
8. おわりに
さていかがでしょうか。ニンニク臭が強めのメニューばかり薦めてくるレコメンドエンジンが出来上がってしまいましたが、学習データからニンニクを抜けば、もう少し健康によさそうなメニューを薦めてくれるようになるかと思います。機械学習やビッグデータでは Garbage in Garbage out という有名な言葉があり、ゴミデータからはゴミな結果しか生まれないという意味があるのですが、ニンニクメニューからはニンニクメニューしかうまれない、Garlic in Garlic out なことがわかったのが今回の学びでした。
ここから発展させるとしたら、複数ユーザの (ダミーではなく正規の) データをかき集めて User Data を使ってみたいところです。また、写真に写っている食べ物を教えてくれるようなモデルを Amazon Rekognition Custom Labels で作成しておき、作って食べる料理を写真に撮り、 post したらリアルタイムイベントに put してくれるような機能を AWS Lambda + Amazon API Gateway で実装すると、次のレコメンドが楽になるかもしれません。データを変えたり、使ってない機能を試してみたり、他の AWS サービスと連携してみたり、と夢が広がりますね ! Amazon Personalize の 開発者ドキュメントはこちら にございますので、ぜひいろいろなレコメンドを試していただければと思います。
また、Amazon Personalize についての動画 による紹介や、Movielens という映画の視聴履歴を用いた ハンズオンコンテンツ (今回扱わなかったUser Data や、SIMSアルゴリズムなども扱います) もございますので、合わせてご利用いただければ幸いです。
最後に、まるで普段私が食事を作っているような文体になってしまっていますが、実際はあまりやっていないのでこの記事が妻に見つからないことを祈りつつ、この言葉を持って筆を擱 (お) きたいと思います。
ニンニク、いれますか ?

目黒の某ラーメン店のヤサイマシマシ (ニンニクは入っていない)
筆者プロフィール

呉 和仁 (Go Kazuhito / @kazuneet)
アマゾン ウェブ サービス ジャパン合同会社
機械学習ソリューションアーキテクト。
IoT の DWH 開発、データサイエンティスト兼業務コンサルタントを経て現職。
プログラマの三大美徳である怠惰だけを極めてしまい、モデル構築を怠けられる AWS の AI サービスをこよなく愛す。
AWS を無料でお試しいただけます