- AWS Builder Center›
- builders.flash
サーバーレスが気になる開発者に捧ぐ「べき等性」ことはじめ ~ 第一回 べき等性 (冪等性/idempotency) ってなんだ!?
Author : 杉 達也
はじめに
次の新規プロジェクトで、要件が定まりにくいデジタルトランスフォーメーション / DX プロジェクトで、サーバーレス を使ってみようという方が増えています。サーバーレスアプリケーションや マイクロサービス 型アプリケーションを検討すると、いずれぶつかる言葉にべき等性 (冪等性 / idempotency) というものがあります。マイクロサービスやサーバーレス型へのチャレンジは、技術的な変化と同時に、アプリケーション設計としてべき等性についての考慮が求められていきます。べき等性とは何なのか、なぜこれまではあまり言及されていないことがマイクロサービスやサーバーレスでは強調されるのか。これからのモダンなアプリケーション開発を進める上で覚えておくべき性質を今一度理解しましょう。
builders.flash メールメンバー登録
builders.flash メールメンバー登録で、毎月の最新アップデート情報とともに、AWS を無料でお試しいただけるクレジットコードを受け取ることができます。
べき等性とは ?
そもそも、べき等性とは、どういうことを言うのでしょうか ? これは「ある操作を 1 回行っても複数回行っても結果が同じである」ことをいう概念です。
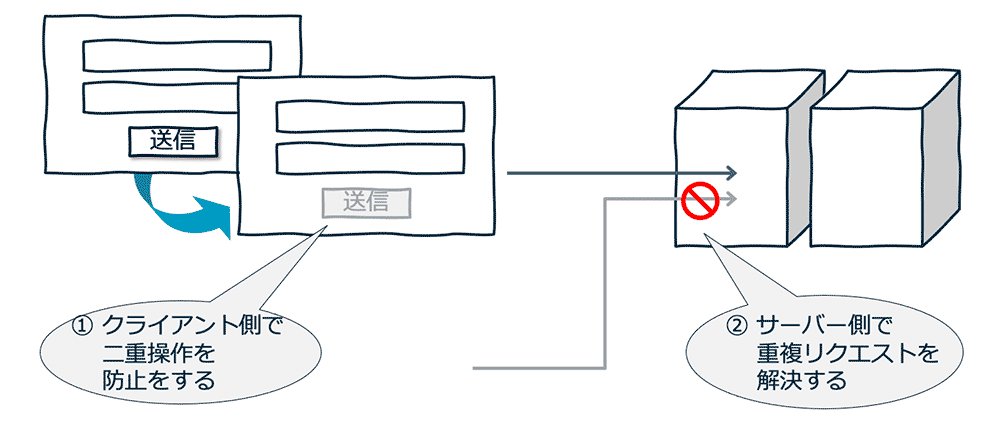
例えば、注文処理を考えます。画面インターフェースで、注文確定 / 送信ボタンを押すという操作で二度三度押してしまうユーザーがいます。これで同じ内容の注文が複数回登録されてしまったら問題です。こういったケースでは、画面側で連続して押せないような実装を追加したり (①)、サーバー側で同じ注文の処理であることを認識して適切に一つの処理と判断するようなこと (②) が必要です。
この例では、画面側の制御を入れたほうが簡単なように見えます。しかし、現実には画面とサーバーとの間のネットワークの問題や画面以外からの HTTP コールなどを考えると、このような重複リクエストが起こってしまうという可能性はゼロではありません。
このようなものへの対処として、サーバー側の注文処理で「べき等性」が保証されていると、より堅牢なシステムであると言えます。
別の例
別の例を考えてみましょう。
アプリケーションの中で、フロー処理のようなものがあるとします。
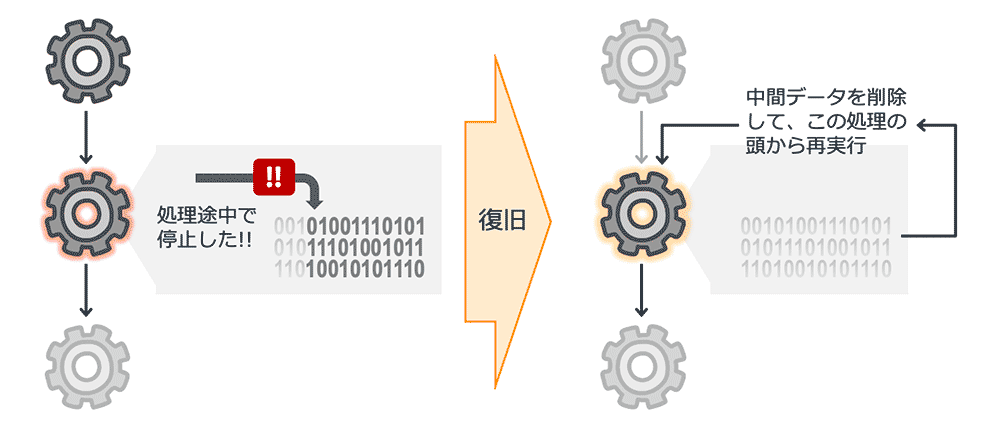
処理 1 → 処理 2 → 処理 3 ・・・という流れで、たとえばデータの加工や集計処理を順番に実施するパイプライン処理などです。このようなケースで、処理 2 の途中まで進んだ状態で何らかの障害が発生し、処理が停止してしまったとします。復旧処理としてどこから処理を再開するとよいでしょうか ?
例えば、処理 2 の内部で生じる中間データを全削除して、始めから再実行するなどが考えられます。
べき等性が求められるポイント
こうした障害復旧のケースでは、全体フロー内で、障害が起きた場所より前のステップにあたるどこかを復旧ポイントとして、そこから再実行するような手順が一番よく使われます。この再開する処理は、べき等性が求められるポイントになっています。今のシナリオでは、障害復旧時に中間データを削除して再実行、としました。これを踏まえて、そもそも処理2の最初の初期化タスクとして中間データの削除という実装が備わっていたら、処理2は、復旧作業に関わらずべき等性が保証された処理ということになります。
今あげた例でわかるように、べき等性という性質は、マイクロサービスやサーバーレスに特化したことではありません。
なぜマイクロサービスやサーバーレスの際に強調して言われるの ?
では、なぜ、べき等性がマイクロサービスやサーバーレスの文脈で強調して必要性を言われるのでしょう ? 理由は 2 つあります
- マイクロサービス / サーバーレスでは、一つの処理単位が小さく独立している
- サーバーレスでは、リトライが自動で実行されることがある
従来型のモノリスなアプリケーションは、一つの処理単位が大きく、多くの場合、それを一つの DB トランザクションとして捉えています。このようなケースの多くの場合、べき等性は DB トランザクションのレベルで確保されます。
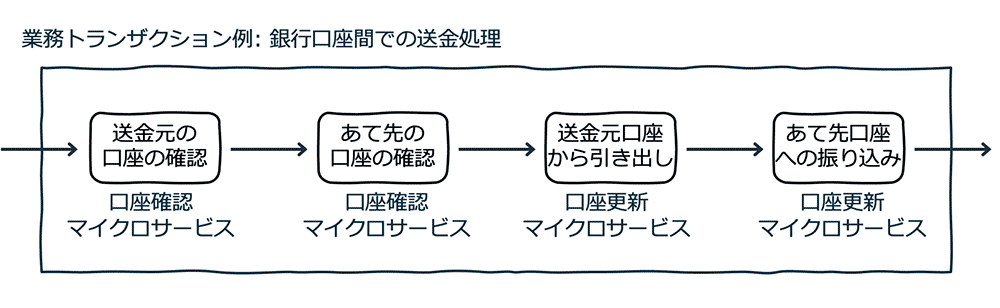
一方、マイクロサービス型の場合、もう少し小さな単位に処理を分割設計し、そのそれぞれの小さな処理で独立したデータストアを持つことが多いです。業務的なトランザクションよりもマイクロサービスの単位が小さい (複数のマイクロサービスで一つの業務トランザクションが成立する) という状況になります。
キャンセル処理
正常終了の場合はどちらでも変わりはないですが、なにか問題や障害が起きた場合やトランザクションのキャンセル時の対処は変わります。マイクロサービス型では、個々のマイクロサービスで一つの処理が完結しているため、一連のフローの途中からの再開がしやすい反面、業務トランザクションの単位でのキャンセル処理は少し複雑になります。
業務トランザクションのスコープでの All or Nothing の成否の判定のほうがシンプルだと思われる方もいらっしゃるでしょう。マイクロサービス型でトランザクション失敗のときはどうするの ? という疑問も生まれるかと思います。これについては後述します。
一つ言えるのは、マイクロサービス型にすることの利点と、トランザクションの考え方の変化による工数を天秤にかける必要はあるということです。一概にどちらが良いということではなく、この場面ではマイクロサービス型、この場面では従来型トランザクションを包含した少し大きめのコンポーネント型、というのを併用 / 組み合わせで考慮すべきであり、無理にマイクロサービス型に固執することはおすすめしません。
念のため、マイクロサービス型による代表的なメリットを記載しておきます。ご自分のシステムの部分部分で、以下のようなことがどれだけ重要なのか (または重要ではないのか) で判断すると良いでしょう。
機能の部分的な改修に対応しやすい (変更容易性)
障害復旧時に始めからの再実行ではなく、途中からの再実行でよい (復旧迅速性、サービス異常時間の最小化)
各処理 (マイクロサービス) ごとに処理の多重度を変更させやすい (処理能力の拡張性)
加えて、サーバーレスアプリケーションでは、マイクロサービスに該当する処理関数 (AWS Lambda) のリトライ処理が自動で行われる設定があります。例えば、Amazon S3 → AWS Lambda の連携処理などでの リトライの自動管理・実行 です。リトライは、Lambda 関数のコード実装の不備や実行時メモリ不足などにより関数実行が正常に終了しないケースで行われますが、前述の障害復旧の例を思い浮かべていただければ、この Lambda 関数でべき等性が考慮されている必要があることが理解できるでしょう。
マイクロサービスやサーバーレスアプリケーションでべき等性の考慮が強調されるのは、このような理由からです。
ステートレスとの関係
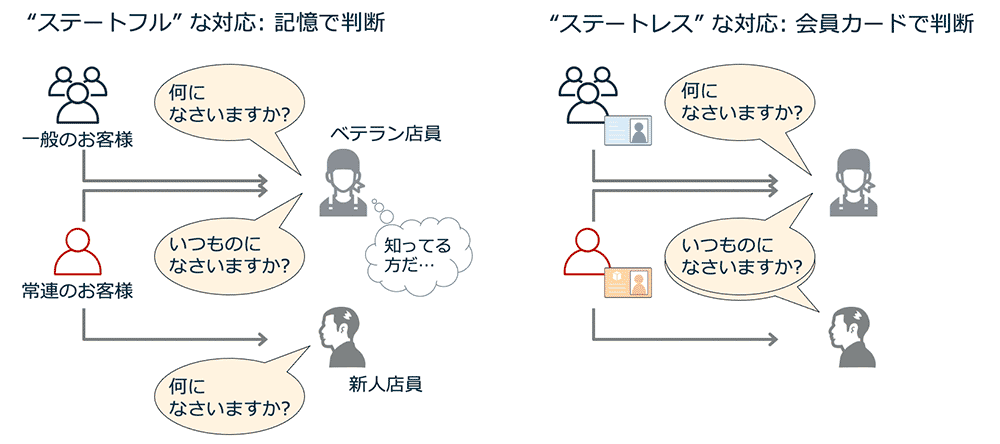
別の議論として、マイクロサービスやサーバーレスではステートレスな処理・関数の実装が求められます。処理や関数が内部でステート (状態) を持たないようにするということです。これはべき等性と強い関連があります。
ステートフルな実装では、特定の処理を連続して呼び出しする場合、1 つ前の呼び出し時の一部のデータをステートとして内部で保持しておくことで、その次の呼び出し時の処理を円滑にすすめることができるようにしています。
処理効率や速度の意味でステートフルは優れています。ただし、二度目以降の呼び出しは一度目の呼び出しで得たステートに影響を受けることになるので、同じパラメータ / 引数を使っていても、一度目と二度目以降の呼び出しで結果が異なる可能性があります。「1 回行っても複数回行っても結果が同じ」とならない可能性があるということは、ステートフルは、べき等性の原則を満たしていないことになります。
ステートフルを避ける方法
ステートフルは、二度目以降の呼び出しの対象となる処理リソース (インスタンス、プロセス) が一度目と同じであることを期待した作りになっています。これにより、処理効率の良さ、レスポンスの最適化などのメリットがある反面、障害に弱い、スケーラビリティにかけるなどの課題に繋がるため、トレードオフの議論だといえます。一般に、ユーザー数やデータ量が増加する可能性があるアプリケーションでは、個々の処理のベストなレスポンスを求めるよりも、処理の並列化 (スケーラビリティ) で解決するほうが得策です。
ステートフルを避ける典型的な方法は、ステートを内部保持するのではなく、外部のデータベースなどに保持して、データとして都度出し入れすることです。ステートを内部保持する方式と比べるとレスポンスに影響が出ることは想像できますし、データベースの利用が増える、処理コードが煩雑になるなどのデメリットも思い浮かびます。処理ロジック内の内部変数でステートを保持したほうが効率的に見えますが、「早すぎる最適化は諸悪の根源」という言葉があるように、ある一時点での局所的な最適化を求めることの良し悪しは冷静に見極めて判断してください。ステートレスであることは、べき等性の確保のための第一歩になりますが、それ以前に、スケーラビリティや可用性を高めるという意味で、サーバーレスやマイクロサービスとは関係なく価値があります。
べき等性に注意を払うべきところはどこ?
べき等性の考慮が必要になるのは、おもに処理内でなにかのデータストアに書き込みをするような部分が中心になります。読み取りのみの処理では、ステートレスであることを意識すれば十分です。
書き込みを行う処理は、ステートレスであることだけでは不十分で、複数回の実行が行われても結果に違いが出ないように実装に注意する必要があります。
冒頭の例であげた、お客様の特定の注文に対する確定処理をもう一度思い浮かべてください。それがたとえシステム上の都合で複数回実行されたとしても、業務データとしては一つの注文であるべきです。複数の商品が配送されては問題ですし、課金が二重三重になっては困ります。このような場合には、どこかで複数データを解決することが必要になります。
べき等性をどのスコープで保証するか、というのも考慮すべきポイントになります。
複数のマイクロサービスの組み合わせで一つの業務トランザクションが成り立つようなケースでは、個々のマイクロサービスの失敗やキャンセルよりも、業務トランザクションとしての成否のほうが業務的に重要です。業務トランザクションを意識した、より大きなスコープでのべき等性の確保という視点が必要になってきます。
次では、データの重複の解決や、より大きなスコープでべき等性を考えるということについて触れます。
べき等性を保証する実装の典型的な基本パターン
ある処理 X がデータストアに書き込みを行うケースを想定します。
データストアへの書き込み処理を複数回やっても結果として処理対象となるデータは論理的に一つ、という状況にすることがゴールです。このために、特定の処理リクエストが論理的に同じであることを判別するための一意な値を、処理X の呼び出し元で生成して引数として渡す形が望ましいです。その引数の値によって、処理リクエストが同一のリクエストなのか別のリクエストなのかを判別できます。
それぞれの業務において、何が一意な値になるのかは見極めが必要です。例えば、ネットショッピングで購入確定に伴って処理を呼ぶような場合、Web セッション ID を一意の値とするのでは不十分です。一つの Web セッションで複数の購入を行う可能性が考えられるからです。対応策として、購入アクションのタイミングでセッション ID とタイムスタンプで一意の値を生成するなどが考えられます。こうして用意した一意の値を、処理 X を呼ぶ際の引数に使います。
一意の値を伴って呼び出される処理 X がべき等性を保証するための実装として、典型的な形が 2 つあります。
- データストアへの入力 / 登録時にチェックする
- データストアからの出力 / 取得時にチェックする
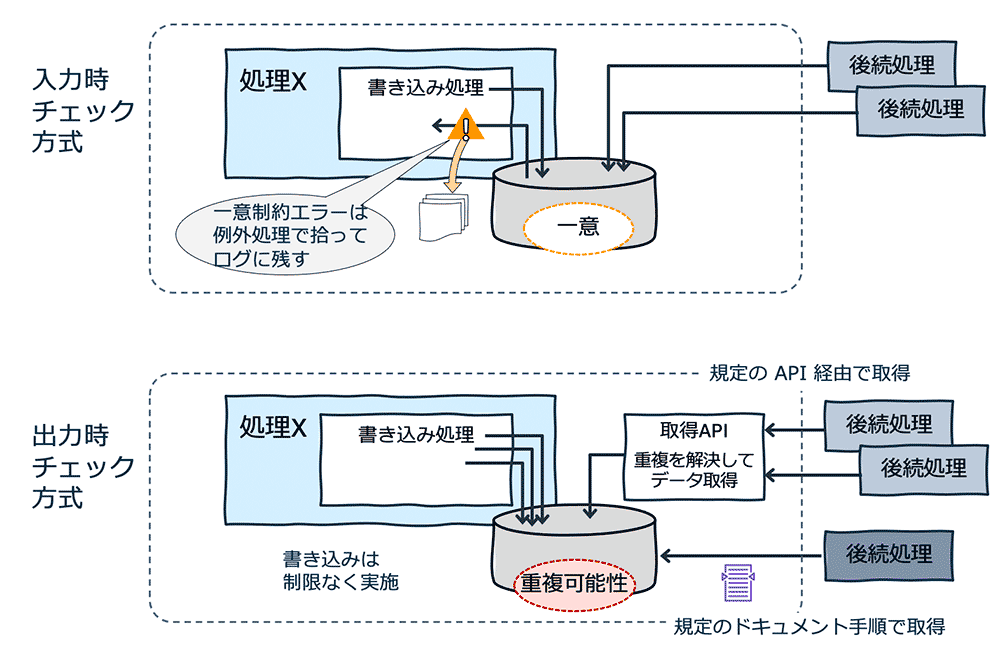
入力時チェック方式
データストアへの書き込み時に注意を払うやり方です。処理 X が複数回実行されてもデータが重複して格納されないように、データストアの一意属性を使って重複をチェックします。
- 一意の値を引数として受け取る。
- データストアへ格納する際に、データストアとなる DB がもつ一意性チェックの機能を利用する。
- 一意性チェックでエラーが出た場合、複数回実行されたことを認識して、例外処理でログに残し、正常終了とする。
- 定期的にログを確認し、重複実行の状況を監視する。特に運用開始当初は、業務的には弾くべきではなかったデータ投入処理を実装の不具合でエラーにしていないかを注意してチェックする。
- 処理 X 側では、データストアに対する一意性チェックのエラーが来たら複数回実行されたことを認識してログに残し、正常終了する
前提として、データストア側での一意性チェック機構が必要になります。データストアに格納された内容は整合性が確保された状態になりますので、別の開発チームがこのデータを利用して後続の処理を開発するような場合に、あまり深い考慮がなくても読み取り処理でデータ整合性の問題は起きません。
出力時チェック方式
データストアから読み取る際に注意を払うやり方です。データストアへの入力時にはデータ投入の重複を許容するため、入力時のチェック作業 / 負荷を軽減させることができます。
- 一意の値を引数として受け取る。
- データストアへの格納では重複チェックをせずにすべてのデータを格納するようにする。
- データソースからの読み取り時に、一意判定をする属性を使って、重複を排除して取得する (SQL クエリで Distinct 句を使う、など)
これは、データストアがシンプルなストレージのように一意性チェック機構がない場合でも使えます。データの書き込み時はなんの制限もしないので、一意性チェック機構が想定外に働いてしまい、データ格納を阻害してしまう、といったリスクがありません。ただし、読み取り時の注意が必要になります。データストアには論理的には一つの重複データがあるという可能性を、別の開発チームが理解せずにアクセスしてしまうと、複数のデータと認識して処理してしまいます。
こうしたことがないように、しっかりドキュメントしておくことが必要です。または、うまく重複排除して取得する読み取り用の API をセットで内部公開して、他のチームにはその API を使うことだけを許容する、というやり方もあります。
トランザクション型の処理への対応
実際の業務では、もう少し事情は複雑です。
ネットショッピングのケースを考えてみます。利用者が商品を選択した後、購入に至る過程では、在庫から商品の個数を引当てて、注文を確定します。この一連のトランザクションを完了するには、在庫データの更新、注文データの更新の 2 つが少なくとも必要ですし、連動して、顧客のポイントデータの更新、配送用のデータ連携や決済のための処理も発生します。
このうち、在庫データの更新と注文データの更新は、ほぼ同時に行う必要があります。必要な個数の在庫が引き当てられなければ、注文を成立させることができません。商品が複数存在する場合、すべての商品の在庫引当ができてはじめて注文確定に至ります。こうした複数のデータ更新が求められるケースでは分散トランザクションを使うことがあります。これはシステムとして All or Nothing でトランザクションの可否を判定する形になります。
-
在庫引当をそれぞれの商品で実施
→ すべてうまくいけば注文確定として、予約を確定化させる (コミット)
→ どれかがうまく行かなければ、予約をキャンセル (ロールバック)
マイクロサービス方式では、例えば、こうなります。
-
在庫引当 (予約) をそれぞれの商品で実施: 予約フラグを立てる
→ すべてうまくいけば注文確定として、予約を確定化させる
→ どれかがうまく行かなければ、予約できた分だけ発注するかどうかを判断
→ 部分注文の確定 or 予約キャンセル (予約フラグのリセット)
このようなケースでは、個々の処理機能の単位でべき等性を確保していたとしても、それとは別に業務スコープでの考慮が必要になります。一部の処理機能で期待通りの結果が得られなかった場合に、その処理機能だけではなく、業務スコープでの整合性の取れたキャンセル処理の検討が必要になります。これは、キャンセル処理を自己制御することになります。自己制御するということは手間ではありますが、より柔軟な制御ができるともいえます。前述の例では、部分注文の確定といった機能を実装可能になります。
時間を伴うケース
もう少し時間を伴うケースを見てみましょう。
購入・配送した後、お客様が実物を見てやっぱりキャンセル・返品するという場合、以下のようなことが起こります。
-
返品商品の受け取り
-
決済処理のキャンセル、返金処理
-
購入履歴の更新
-
顧客のポイントデータの更新
・・・
一度確定した購買に関連する各種データの再更新 (キャンセルに伴うデータの変更) と、払い戻しのための別プロセス起動が必要になります。このケースでは確定とキャンセルの間に時間が生じるため、分散トランザクションを利用することができません。したがって、従来型方式でもマイクロサービス型でも、同様に返品プロセス (キャンセル処理) を検討することになります。
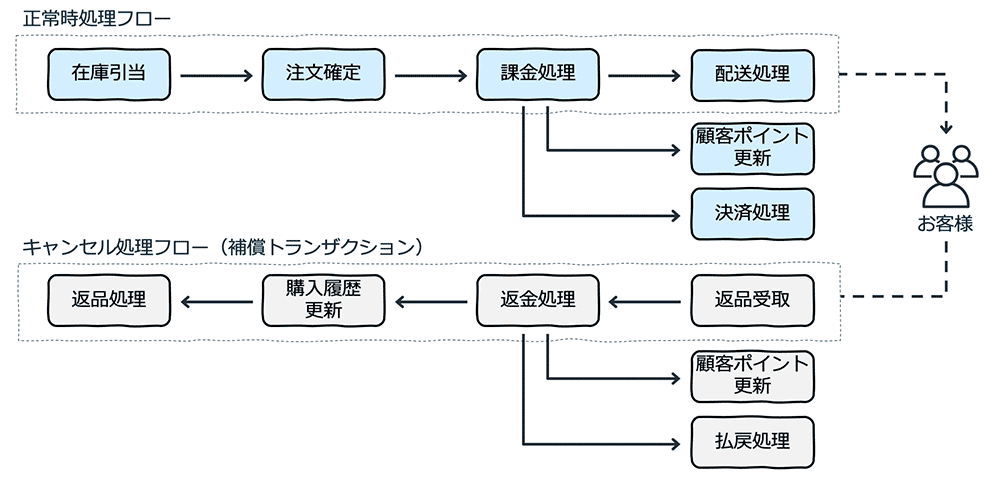
補償トランザクション
2 つの例で紹介したキャンセル型の処理を補償トランザクションといいます。
All or Nothing で良ければ、従来型の分散トランザクション機能に頼るほうがシンプルです。しかし、上記の例のように、すべてのケースで分散トランザクションが利用可能なわけではないので、補償トランザクションの考え方はどちらにしろ必要になるでしょう。
すべてをマイクロサービスで、補償トランザクションで、ということでもありません。要件によっては、部分的に従来型実装 (分散トランザクション) を使うというのも一つの判断だと言えます。補償トランザクションは設計を複雑にしてしまうデメリットはあるので、トレードオフを適切に判断してください。アプリケーション全体が一枚岩なモノリスでないなら、部分的に従来型実装を使った機能が含まれても、全体としてマイクロサービスのメリットは得られる、という思考ですすめるのが良いのではないかと思います。
まとめ
サーバーレスアプリケーションは、自然にマイクロサービス型の効果が得られます。その意味で、サーバーレス設計にはべき等性やステートレスの考慮が必要になってきます。こうした考え方に慣れるという意味では、サーバーレスやマイクロサービス型の設計を読み取り型の処理やシンプルな更新処理から始めると良いかもしれません。
今回は、AWS のサービスに依存するような内容に極力触れない形にしました。次回は、AWS のサービスを使ってこれらの典型的なべき等性のパターンを実装するとどのような形になるのか、どんな機能を使うと便利なのかをご紹介します。
プロフィール
杉 達也
アマゾン ウェブ サービス ジャパン合同会社
シニア サーバーレススペシャリスト 事業開発マネージャ
Serverless Specialist / BD として AWS Japan に勤務。
サーバーやインフラのことをあまり考えたくない、気にしたくないので、サーバーレスは魅力的です。サイジングやキャパシティプランニング作業からも開放されます。
早く、サーバーレスの世界を体験してもらいたい、そう思いつつ、日々その伝え方を考えています。

Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages