AWS 기반 분석
가격 대비 성능 및 규모에 맞게 최적화된, 모든 분석 워크로드를 위한 포괄적인 기능 세트
개요
AWS는 모든 분석 워크로드를 위한 포괄적인 기능 세트를 제공합니다. 데이터 처리 및 SQL 분석부터 스트리밍, 검색, 비즈니스 인텔리전스까지, AWS는 거버넌스가 기본 제공되는 독보적인 가격 대비 성능과 확장성을 제공합니다. Amazon SageMaker를 사용하여 특정 워크로드에 최적화된 목적별 서비스를 선택하거나 데이터 및 AI 워크플로를 간소화하고 관리할 수 있습니다. 데이터 여정을 시작하든, 통합 경험을 원하든, AWS는 데이터로 비즈니스를 혁신하는 데 도움이 되는 적절한 분석 기능을 제공합니다.
AWS 기반 분석을 통해 실질적인 비즈니스 성과 도출
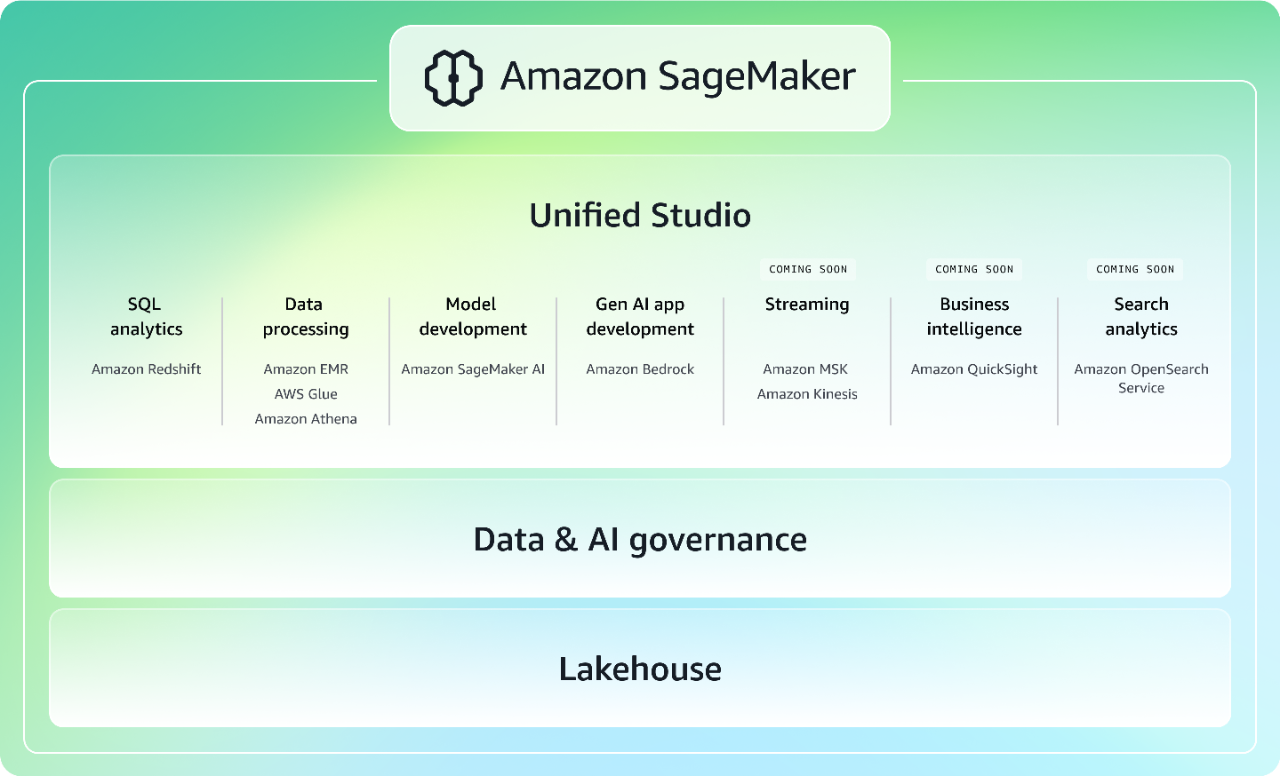
통합 경험으로 데이터, 분석, AI를 가속화
차세대 Amazon SageMaker는 널리 도입된 AWS 기계 학습(ML) 및 분석 기능을 결합하여 모든 데이터에 대한 통합 액세스를 통해 분석 및 AI를 위한 통합 경험을 제공합니다. Unified Studio에서 소프트웨어 개발을 위한 가장 유능한 생성형 AI 어시스턴트인 Amazon Q Developer의 지원을 받으면서 모델 개발, 생성형 AI 애플리케이션 개발, 데이터 처리, SQL 분석을 위한 친숙한 AWS 도구를 사용하여 더 빠르게 협업하고 구축하세요. 데이터 저장 위치가 데이터 레이크, 데이터 웨어하우스, 서드 파티 또는 연합 데이터 소스 어디든 관계없이 엔터프라이즈 보안 요구 사항을 해결하도록 내장된 거버넌스를 통해 모든 데이터에 액세스할 수 있습니다. SageMaker에 대해 자세히 알아보세요.
AWS로 멀티클라우드 전략 지원
AWS는 멀티클라우드 및 하이브리드 환경에서 원활한 데이터 액세스와 처리를 지원하는 강력한 분석 서비스를 포괄적으로 제공합니다. 통합 쿼리, 데이터 통합, 안전한 데이터 이동, 개방형 표준과의 호환성을 통해 이러한 유연성을 확보할 수 있으므로, 데이터가 어디에 있든 모든 데이터에서 인사이트를 도출할 수 있습니다.
Amazon Athena를 사용하면 데이터를 복사하거나 변환할 필요 없이 Azure Data Lake Storage, Google Cloud Storage, Microsoft SQL Server 등을 비롯한 다양한 외부 데이터 소스에 저장된 데이터를 쿼리하고 이를 통해 인사이트를 얻을 수 있습니다.
AWS Glue는 클라우드 스토리지, 데이터베이스 및 분석 서비스를 망라하는 100여 가지의 다양한 데이터 소스용 커넥터를 사용하여 규모에 관계없이 모든 데이터의 검색, 준비, 통합을 간소화합니다. Glue의 제로 ETL 통합을 사용하면 Salesforce, SAP, Facebook Ads, Instagram Ads와 같은 서드 파티 애플리케이션의 데이터를 손쉽게 수집하고 AWS 레이크하우스, 데이터 레이크 및 데이터 웨어하우스에 직접 복제할 수 있습니다. 또한 AWS Glue는 Apache Hive, Apache Parquet, Apache Iceberg와 같은 개방형 표준에 대한 지원을 통해 데이터 상호 운용성을 제공합니다.
차세대 Amazon SageMaker는 개방형 데이터 레이크하우스 아키텍처를 기반으로 구축되어, Google BigQuery, Snowflake와 같은 페더레이션된 데이터 소스뿐만 아니라 AWS의 데이터 레이크 및 데이터 웨어하우스에 대해서도 통합 액세스를 제공합니다. 이 레이크하우스 아키텍처는 Apache Iceberg와 완벽하게 호환되므로 Iceberg와 호환되는 도구와 엔진을 사용하여 어디서나 데이터에 액세스하고 쿼리할 수 있는 유연성을 제공합니다.
사람과 AI를 위한 분석 활용
데이터 저장, 쿼리, 스트리밍, 처리, 관리를 위한 전용 서비스로 대규모 분석을 강화합니다. 오픈 테이블 형식(OTF)에서 에이전트 인프라에 이르기까지, AWS는 빠르게 변화하는 분석 환경에 맞게 분석 엔진과 애플리케이션을 발전시키고 있습니다. 이 세션에서는 AWS가 어떻게 인간 사용자와 에이전트 워크플로에 맞게 구축된 최적화된 솔루션을 제공하는지 살펴봅니다.

서비스
|
분석 카테고리
|
설명
|
AWS 서비스 및 기능
|
|---|---|---|
|
스트리밍
|
인프라 관리 부담 없이 실시간 데이터 파이프라인과 애플리케이션을 구축, 확장, 운영하세요. |
|
|
데이터 레이크하우스, 데이터 웨어하우스, 데이터 레이크
|
데이터 레이크하우스, 데이터 웨어하우스, 데이터 레이크에 있는 모든 데이터에 액세스하고 분석하세요. |
|
|
데이터 처리
|
오픈 소스 프레임워크를 사용하여 분석과 AI를 위한 데이터를 분석, 준비, 통합하세요. |
|
|
비즈니스 인텔리전스
|
최신 대화형 대시보드, 픽셀 퍼펙트 보고서, 자연어 쿼리, 임베디드 분석을 통해 의미 있는 인사이트를 구축, 검색, 공유할 수 있습니다. |
|
|
검색 분석
|
비즈니스 및 운영 데이터의 실시간 검색, 모니터링, 분석을 안전하게 활용합니다. |
|
|
데이터 및 AI 거버넌스
|
AWS, 온프레미스, 서드 파티 소스에 저장된 데이터를 카탈로그화, 검색, 공유, 관리할 수 있습니다. |
The Total Economic Impact of AWS Modern Data Strategy
Forrester의 보고서가 밝힌 Amazon Web Services의 현대적 데이터 전략으로 가능한 비용 절감과 비즈니스 이점.
통계
오늘 원하는 내용을 찾으셨나요?
페이지의 콘텐츠 품질을 개선할 수 있도록 피드백을 보내주세요.