
Sold by: Spice AI
Deployed on AWS
Spice.ai Enterprise is a portable (<150MB) compute engine built in Rust for data-intensive and intelligent applications. Deployable as a container on AWS ECS, EKS, or hybrid cloud+edge, it includes Enterprise licensing, support, and SLA.
Overview
Image
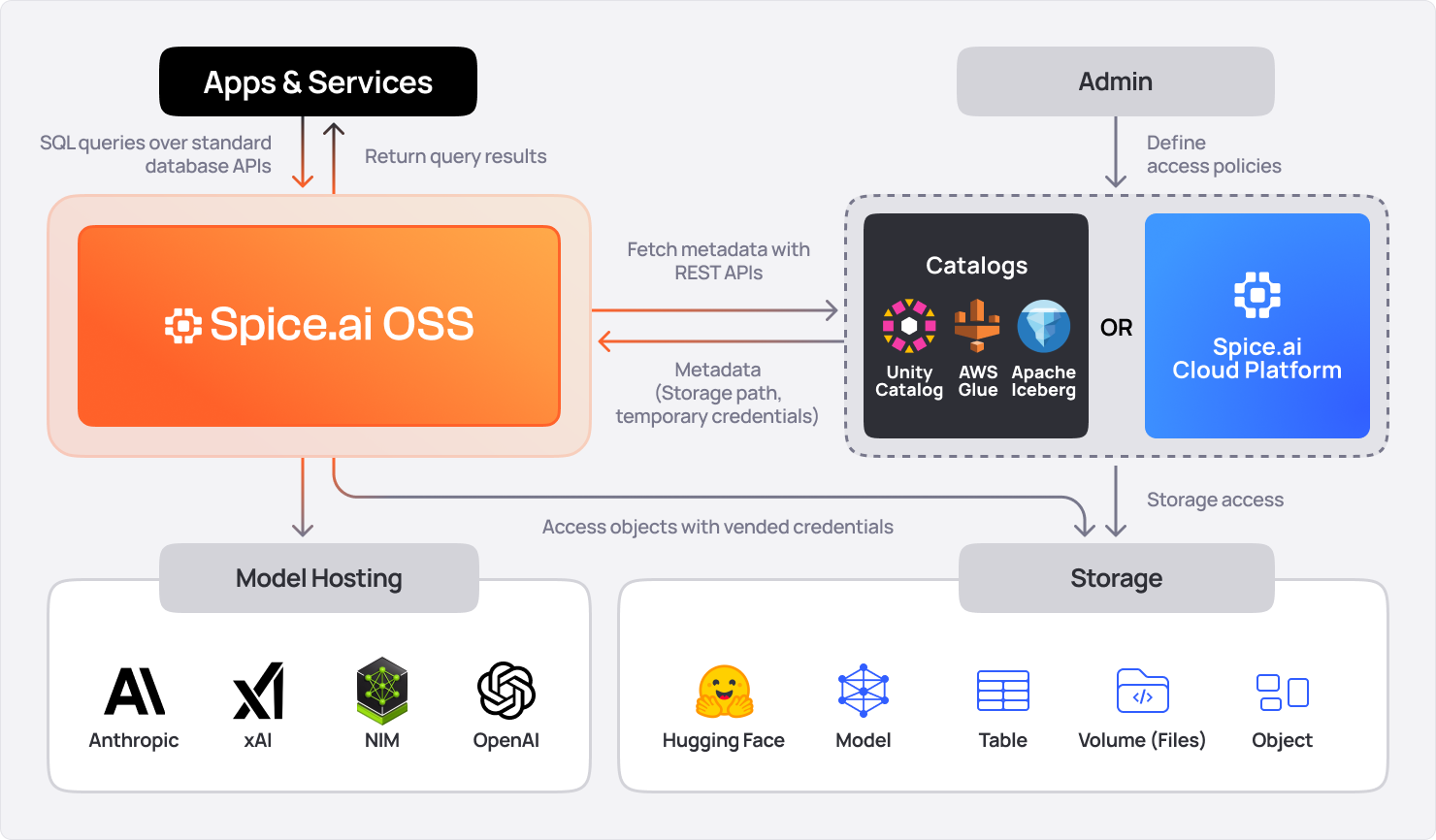
Architecture

Video
Product video
Spice.ai Enterprise is a portable (<150MB) compute engine built in Rust for data-intensive and intelligent applications. It accelerates SQL queries across databases, data warehouses, and data lakes using Apache Arrow, DataFusion, DuckDB, or SQLite. Integrated and co-deployed with data-intensive applications, Spice materializes and accelerates data from object storage, ensuring sub-second query performance and resilient AI applications. Deployable as a container on AWS ECS, EKS, or hybrid cloud & edge, it includes enterprise licensing, support, and SLAs.
Note: Spice.ai Enterprise requires an existing commercial license. For details, please contact sales@spice.ai .
Highlights
- Unified data query and AI engine accelerating SQL queries across databases, data warehouses, and data lakes. Delivers sub-second query performance while grounding mission-critical AI applications with real-time context to minimize errors and hallucinations.
- Advanced AI and retrieval tools, featuring vector and hybrid search, text-to-SQL, and LLM memory, enabling data-grounded AI applications with more than 25 data connectors enabling federated queries and real-time applications.
- Deployable as a container on AWS ECS, EKS, or on-premises, with dedicated support and SLAs for scalable, secure integration into any architecture.
Details
Sold by
Delivery method
Supported services
Delivery option
Container Deployment
Helm Deployment
Latest version
Operating system
Linux
Deployed on AWS
New
Introducing multi-product solutions
You can now purchase comprehensive solutions tailored to use cases and industries.

Features and programs
Financing for AWS Marketplace purchases
AWS Marketplace now accepts line of credit payments through the PNC Vendor Finance program. This program is available to select AWS customers in the US, excluding NV, NC, ND, TN, & VT.

Pricing
Pricing and entitlements for this product are managed through an external billing relationship between you and the vendor. You activate the product by supplying a license purchased outside of AWS Marketplace, while AWS provides the infrastructure required to launch the product. AWS Subscriptions have no end date and may be canceled any time. However, the cancellation won't affect the status of the external license.
Additional AWS infrastructure costs may apply. Use the AWS Pricing Calculator to estimate your infrastructure costs.
Vendor refund policy
Refunds for Spice.ai Enterprise container subscriptions are not available after activation, as usage begins immediately upon deployment. Ensure compatibility with AWS ECS, EKS, or on-premises setups before purchase. For billing inquiries, contact AWS Marketplace support or Spice AI directly at support@spice.ai .

Legal
Vendor terms and conditions
Upon subscribing to this product, you must acknowledge and agree to the terms and conditions outlined in the vendor's End User License Agreement (EULA) .
Content disclaimer
Vendors are responsible for their product descriptions and other product content. AWS does not warrant that vendors' product descriptions or other product content are accurate, complete, reliable, current, or error-free.
Delivery details
Container Deployment
Supported services: Learn more
- Amazon ECS
- Amazon EKS
- Amazon ECS Anywhere
- Amazon EKS Anywhere
Container image
Containers are lightweight, portable execution environments that wrap server application software in a filesystem that includes everything it needs to run. Container applications run on supported container runtimes and orchestration services, such as Amazon Elastic Container Service (Amazon ECS) or Amazon Elastic Kubernetes Service (Amazon EKS). Both eliminate the need for you to install and operate your own container orchestration software by managing and scheduling containers on a scalable cluster of virtual machines.
Version release notes
Spice v2.1.2-enterprise is the enterprise release of v2.1.2, a patch release focused on improving the DuckDB data accelerator. It upgrades the DuckDB engine to v1.5.5 and introduces the on_full_refresh parameter, giving file-mode DuckDB accelerations compact, predictable disk usage across repeated full refreshes.
What's New in v2.1.2-enterprise
Bounded DuckDB Acceleration File Growth with on_full_refresh
File-mode DuckDB accelerations using refresh_mode: full now reclaim disk space on every refresh, keeping the database file compact and disk usage predictable for long-running deployments. Each full refresh bulk-loads a fresh copy of the data, and the new on_full_refresh modes ensure the space held by prior copies is returned rather than accumulating in the file.
The new on_full_refresh acceleration parameter controls how disk space is reclaimed after each full refresh:
acceleration: engine: duckdb mode: file refresh_mode: full params: duckdb_file: /data/shared.duckdb on_full_refresh: replace_file # default: reuse_file- reuse_file (default): Existing behavior: refresh into the existing database file.
- replace_file: Each full refresh streams data into a fresh staging database file, carries over every other object sharing the file (other datasets' tables, views, indexes, and Spice metadata), checkpoints it, and atomically replaces the configured file. Queries are never interrupted - in-flight queries drain against the old file while new queries see the new file - and space is fully reclaimed on every refresh.
- checkpoint_file: After each refresh, run a CHECKPOINT in place, escalating to FORCE CHECKPOINT when concurrent transactions block the plain attempt (waiting for in-flight transactions; never aborting them).
DuckDB 1.5.5
The DuckDB engine is upgraded from v1.5.3 to v1.5.5 , bringing the latest upstream stability fixes.
Breaking Changes
No breaking changes.
Cookbook Updates
No new cookbook recipes.
The Spice Cookbook includes more than 100 recipes to help you get started with Spice quickly and easily.
Upgrading
To upgrade to v2.1.2-enterprise, use one of the following methods:
Docker:
Run using the 2.1.2 docker enterprise image
docker run --name spiceai-enterprise \ -p 50051:50051 -p 8090:8090 709825985650.dkr.ecr.us-east-1.amazonaws.com/spice-ai/spiceai-enterprise-byol:2.1.2-enterprise-models --http 0.0.0.0:8090 --flight 0.0.0.0:50051`For available tags, see DockerHub .
Helm:
helm pull oci://709825985650.dkr.ecr.us-east-1.amazonaws.com/spice-ai/spiceai-enterprise-byol --version 2.1.2-enterprise-helm`Additional details
Usage instructions
The docker image expects a spicepod.yaml in the /app directory. Mount a volume into the container with the configured spicepod.yaml.
By default the endpoints only listen on 127.0.0.1, to access the endpoints from outside of the docker container, specify the endpoints to listen on 0.0.0.0 as shown below.
i.e. to mount the current directory into /app: docker run --name spiceai-enterprise -v .:/app -p 50051:50051 -p 8090:8090 709825985650.dkr.ecr.us-east-1.amazonaws.com/spice-ai/spiceai-enterprise-byol:2.1.1-enterprise-models --http 0.0.0.0:8090 --flight 0.0.0.0:50051`
Resources
Vendor resources
Support
Vendor support
Spice.ai Enterprise includes 24/7 dedicated support with a dedicated Slack/Team channel, priority email and ticketing, ensuring critical issues are addressed per the Enterprise SLA.
Detailed enterprise support information is available in the Support Policy & SLA document provided at onboarding.
For general support, please email support@spice.ai .
AWS infrastructure support
AWS Support is a one-on-one, fast-response support channel that is staffed 24x7x365 with experienced and technical support engineers. The service helps customers of all sizes and technical abilities to successfully utilize the products and features provided by Amazon Web Services.
Similar products

Spice AI-provided Consulting Services to help deploy and manage Spice AI software. Consulting services are provided by in-house technical and product specialists qualified to assist customers in their Spice AI journey.

Royal Cyber deploys Amazon Quick Suite — agentic AI that connects your data, automates workflows, and delivers BI from question to action in weeks, not months.

Royal Cyber runs your AI operations 24x7x365 so your team builds what's next , not babysits what's live. AWS-native. ISO 27001 certified.

OneData Software empowers organizations to unlock real-time insights using Amazon QuickSight, delivering interactive dashboards, predictive analytics, and AI-powered visualizations. Their solution integrates seamlessly with AWS data sources, enabling scalable, secure, and cost-effective business intelligence tailored to each client’s goals
Customer reviews
No customer reviews yet
Be the first to review this product . We've partnered with PeerSpot to gather customer feedback. You can share your experience by writing or recording a review, or scheduling a call with a PeerSpot analyst.