O blog da AWS
Capture e ajuste métricas de utilização de recursos para o Amazon RDS for SQL Server
Neste blog, demonstraremos como capturar e ajustar métricas de utilização de recursos no Amazon RDS for SQL Server.
Monitoramento Avançado (Enhanced Monitoring) do Amazon RDS
O Enhanced Monitoring fornece métricas em tempo real para o sistema operacional no qual sua instância de banco de dados é executada. Essas métricas podem ser configuradas com granularidade de até 1 segundo e podem ser acessadas por meio da console ou da API do Amazon RDS. O monitoramento avançado coleta as métricas através de um agente na instância de banco de dados, enquanto o CloudWatch coleta as métricas na camada do hypervisor. Para obter mais informações, clique no link a seguir em Enhanced Monitoring.
Talvez você esteja se perguntando por quanto tempo deveria capturar as métricas de desempenho. O ideal é que você capture informações suficientes durante ciclos importantes, como horário de pico comercial, operações normais e eventos periódicos, como processamento mensal de jobs. As métricas de Monitoramento Avançado são armazenadas por padrão por 30 dias no CloudWatch Logs, mas você pode estender esse período.
Veja a seguir algumas métricas importantes:
- Utilização da CPU — O monitoramento da utilização da CPU ajuda a identificar se os problemas de desempenho são causados por CPU Pressure. Por exemplo, se você descobrir que a utilização da CPU era de 80% no momento do problema de desempenho e, na mesma época da semana passada, a utilização da CPU foi semelhante, sem nenhum problema relatado, é provável que a CPU não seja o gargalo.
- Disco — Você pode rastrear padrões de uso de I/O e de armazenamento usando métricas como IOPS de leitura e gravação para estabelecer a tendência. Isso também pode ajudar, durante o planejamento da capacidade de armazenamento, a escolher entre os tipos de volume disponíveis, como discos gp2/gp3 e io1/io2.
- Memória — Vários problemas de desempenho podem estar relacionados a gargalos de memória. Com o Monitoramento Avançado, você pode rastrear o uso e os padrões de memória do sistema (Memória Total e Memória Disponível) e do SQL Server (Memória Total do SQL Server) para identificar gargalos.
- Rede — As métricas de desempenho da rede (KB/s de leitura de rede e KB/s de gravação de rede) coletadas pelo Monitoramento Avançado são úteis para rastrear a quantidade de dados transferidos pela rede.
Com essas métricas, você pode ter uma boa indicação da utilização do recurso durante dias e horários importantes dos seus processos de negócios. Esses valores podem fornecer uma visão holística da utilização de recursos, o que pode ser útil quando uma comparação é necessária para identificar possíveis gargalos.
Você pode criar um dashboard no CloudWatch para ter uma visão centralizada dessas métricas de desempenho aqui discutidas. A captura de tela a seguir mostra um dashboard consolidado com dados do CloudWatch e do Monitoramento Avançado.
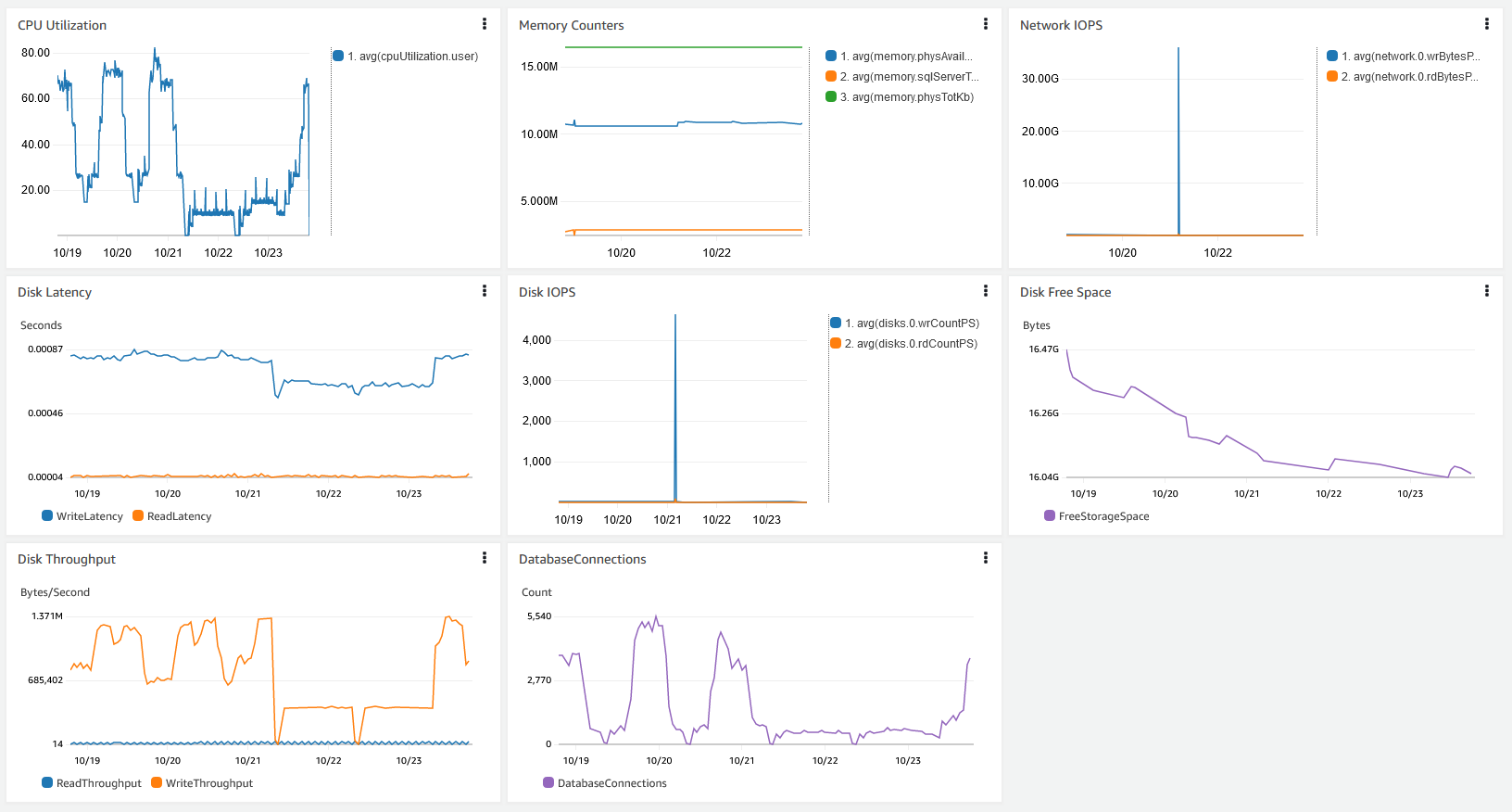
Performance Insights do Amazon RDS
O Performance Insights é uma ferramenta de monitoramento que fornece informações sobre o desempenho do banco de dados RDS. O nível gratuito do Performance Insights coleta dados a cada segundo dos bancos de dados do RDS, e podem ser retidos por 7 dias. Para tendências de desempenho de longo prazo, você pode aumentar o histórico de dados de desempenho contínuo para até dois anos. Para cada mecanismo de banco de dados do RDS, o Performance Insights exibe informações ligeiramente diferentes com base nas métricas de desempenho nativas do mecanismo. Com o Performance Insights, você pode reunir tendências de load (carregamento) do banco de dados, principais tipos de espera e principais consultas SQL durante um período de tempo. Você pode usar essas informações para comparar com os dados atuais afim de isolar as possíveis causas raízes.
A maioria dos DBAs do SQL Server está familiarizada com as DMVs (Dynamic Management Views – Exibições de Gerenciamento Dinâmico) para diagnosticar e depurar problemas do SQL Server. Com as DMVs, os dados são coletados como estão, e você precisa desenvolver mecanismos para entender as tendências de utilização. É aqui que o Performance Insights ajuda, automatizando a coleta e a retenção de dados.
Veja a seguir algumas métricas importantes:
- Métodos de acesso — Divisões de página — Isso pode causar gargalos de I/O (E/S) e números altos podem ser uma indicação de que uma atividade de manutenção é necessária, como a reconstrução de índices e a possibilidade de revisitar a configuração do fator de preenchimento.
- Bloqueios e Locks — A contenção de locks pode causar problemas de desempenho no SQL Server, e é importante rastrear essas informações não apenas para análise de tendências, mas também para descobrir SQLs que precisam ser ajustados para que o banco de dados tenha um melhor desempenho. Você pode rastrear os Processos Bloqueados e Número de Deadlocks.
- Gerenciador de memória — Concessões de Memória Pendentes podem ajudar a rastrear um gargalo de memória durante um período de tempo.
- Estatísticas de SQL — Há várias estatísticas de SQL disponíveis no Performance Insights que ajudam você a entender as tarefas que contribuem para o carregamento normal do banco de dados, como Solicitações em Lote, Compilações SQL e Recompilações SQL.
- Gerenciador de Buffer — A Expectativa de Duração de Páginas e a Proporção de Acertos de Cache de Buffer podem ajudá-lo a detectar pressão de memória. Leituras de Página versus Gravações de Página podem fornecer orientação sobre caminhos de otimização, por exemplo, se a indexação precisar ser revisada.
Essas métricas fornecem informações sobre o desempenho do SQL Server. Você pode se aprofundar nas métricas do sistema operacional e do banco de dados, incluindo métricas de desempenho, para entender a causa raiz do problema. A captura de tela a seguir mostra um exemplo dessas métricas.

DMVs e Repositório de Consultas
Depois de identificar uma anomalia, você pode usar as DMVs para se aprofundar e depurar os problemas de desempenho. Para obter mais informações, consulte Exibições de gerenciamento dinâmico do sistema.
A partir do SQL Server 2016, o Amazon RDS for SQL Server também oferece suporte ao Repositório de Consultas (Query Store), que você pode usar para rastrear e gerenciar planos de consulta para instruções SQL. Para obter mais informações, consulte Amazon RDS for SQL Server agora oferece suporte ao Microsoft SQL Server 2016.
Diagnosticando e depurando problemas: utilização da CPU
Vamos analisar um cenário comum em que a aplicação estava funcionando perfeitamente até ontem, e agora está tendo um desempenho degradado. Nesse caso de uso, você foi informado sobre isso por meio ou de um alerta do CloudWatch ou de reclamações de usuários.
Você começa a diagnosticar o problema investigando as métricas. Com o CloudWatch, você pode ver que a métrica de utilização da CPU é alta, talvez acima de 90%. Você quer saber se o processo do SQL Server está contribuindo para a alta porcentagem. Você pode fazer isso por meio do console do Amazon RDS, na guia Monitoramento, em Lista de Processos.
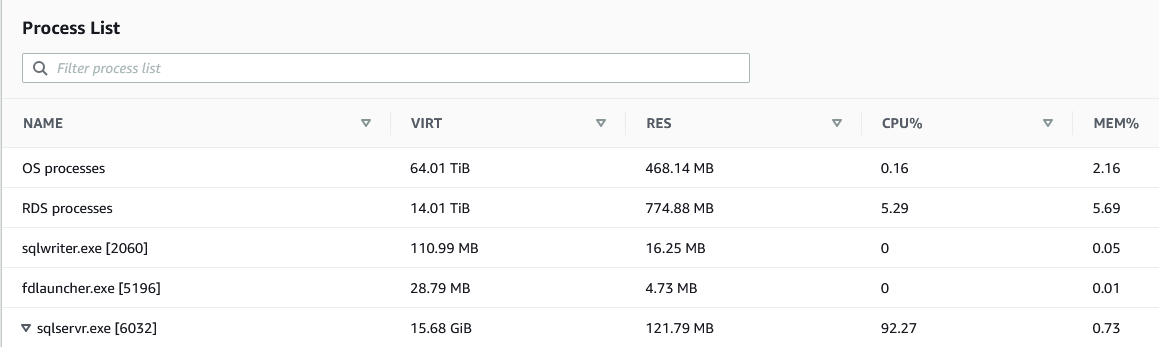
É aqui que o rastreamento da utilização de recursos da sua instância do RDS pode ajudar. Com os dados capturados, torna-se eficiente identificar tendências de uso da CPU ao longo do tempo. Com o Monitoramento Avancado, você pode traçar a tendência do uso da CPU da sua instância nos últimos 30 dias, o que pode indicar se isso é normal ou não.
A próxima etapa é usar os dados capturados no Performance Insights para identificar as consultas que estão contribuindo para a carga da CPU. A captura de tela a seguir mostra um gráfico com dados acumulados ao longo do tempo.
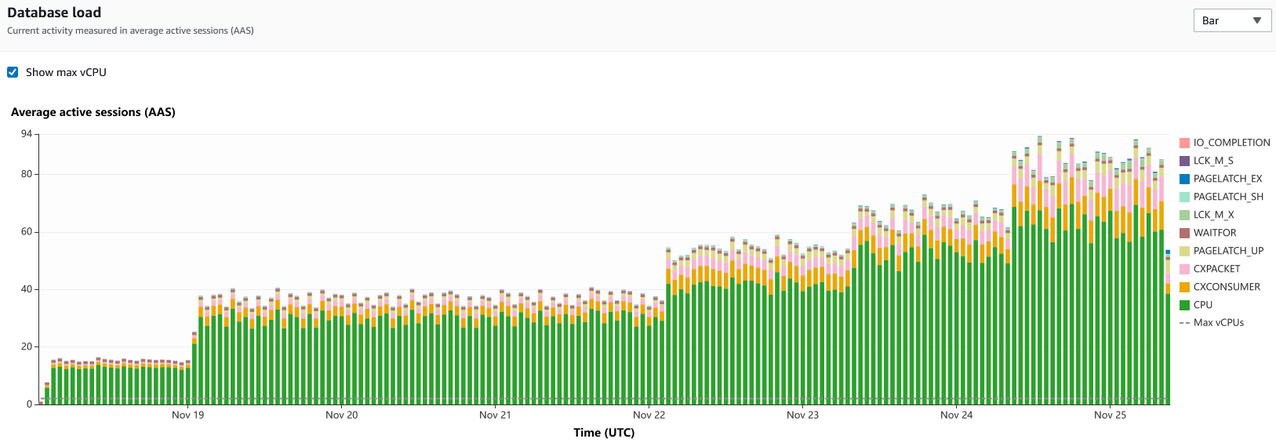
Com base neste gráfico, podemos ver que a CPU é o maior tipo de espera na instância e cresceu ao longo de um período de tempo. A tendência também fornece os dados necessários para o planejamento da capacidade.
Você pode ir mais a fundo em uma data ou horário específicos para ver uma lista das principais consultas T-SQL ordenadas por utilização da CPU. Você pode obter os planos de execução e mais detalhes sobre as consultas através das DMVs.
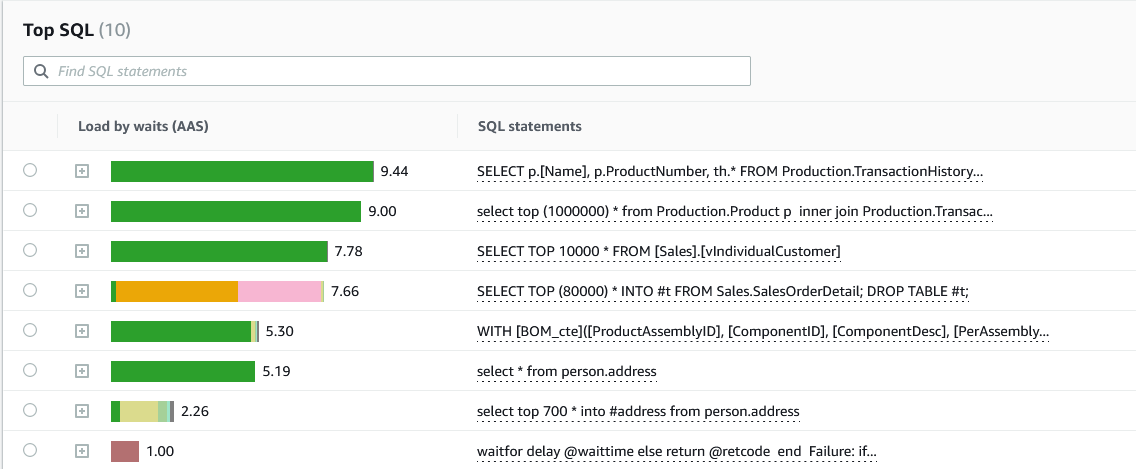
Neste exemplo, conseguimos identificar as três principais consultas que estão contribuindo para a alta carga da CPU. Além das consultas em si, você pode identificar os principais hosts e os principais usuários que estão executando estas consultas, o que torna o processo de troubleshooting ainda mais fácil.
Vamos usar a primeira consulta como exemplo. Para obter as estatísticas de execução e o plano de execução da consulta por meio do SQL Server Management Studio (SSMS), primeiro você precisa de algumas informações sobre a consulta, as quais podem ser obtidas pelo Performance Insights.

O SQL ID é o valor que você fornece às DMVs para obter as estatísticas e o plano de execução. Você precisa prefixar o SQL ID com 0x, conforme mostrado na captura de tela a seguir.
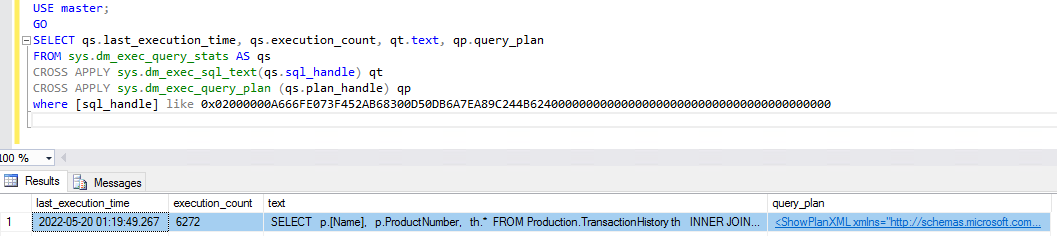
Depois de obter o plano de consulta, sua próxima etapa é otimizar a consulta usando métodos conhecidos de otimização de consultas.
Conclusão
Neste post, aprendemos sobre o Monitoramento Avançado (Enhanced Monitoring) e o Performance Insights do Amazon RDS for SQL Server, que fornece uma ótima maneira de capturar e analisar a integridade e os padrões de uso da instância. Ter essas informações ajuda você a otimizar e solucionar problemas de desempenho. Você pode usar o método deste post para ajudá-lo a melhorar o desempenho da sua instância.
Este artigo foi traduzido do Blog da AWS em Inglês.
Sobre os autores
 Barry Ooi é arquiteto sênior de soluções especializado em bancos de dados na AWS. Sua experiência é projetar, criar e implementar plataformas de dados usando serviços nativos em nuvem para clientes como parte de sua jornada na AWS. Suas áreas de interesse incluem análise e visualização de dados. Em seu tempo livre, ele adora música e atividades ao ar livre.
Barry Ooi é arquiteto sênior de soluções especializado em bancos de dados na AWS. Sua experiência é projetar, criar e implementar plataformas de dados usando serviços nativos em nuvem para clientes como parte de sua jornada na AWS. Suas áreas de interesse incluem análise e visualização de dados. Em seu tempo livre, ele adora música e atividades ao ar livre.
 Rita Ladda é arquiteta sênior de soluções Microsoft na Amazon Web Services, com mais de 20 anos de experiência em muitas tecnologias Microsoft. Ela é especializada em projetar soluções de banco de dados no SQL Server e em outros bancos de dados. Ela fornece orientação arquitetônica aos clientes na migração e modernização de suas cargas de trabalho da Microsoft para a AWS.
Rita Ladda é arquiteta sênior de soluções Microsoft na Amazon Web Services, com mais de 20 anos de experiência em muitas tecnologias Microsoft. Ela é especializada em projetar soluções de banco de dados no SQL Server e em outros bancos de dados. Ela fornece orientação arquitetônica aos clientes na migração e modernização de suas cargas de trabalho da Microsoft para a AWS.
Revisores
 Bruno Lopes é Senior Solutions Architect no time da AWS LATAM. Trabalha com soluções de TI há mais de 14 anos, tendo em seu portfólio inúmeras experiências em workloads Microsoft, ambientes híbridos e capacitação técnica de clientes como Technical Trainer e Evangelista. Agora atua como um Arquiteto de Soluções, unindo todas as capacidades para desburocratizar a adoção das melhores tecnologias afim de ajudar os clientes em seus desafios diários.
Bruno Lopes é Senior Solutions Architect no time da AWS LATAM. Trabalha com soluções de TI há mais de 14 anos, tendo em seu portfólio inúmeras experiências em workloads Microsoft, ambientes híbridos e capacitação técnica de clientes como Technical Trainer e Evangelista. Agora atua como um Arquiteto de Soluções, unindo todas as capacidades para desburocratizar a adoção das melhores tecnologias afim de ajudar os clientes em seus desafios diários.
 David Carvalho Queiroz é Senior Database Consultant no time de Professional Services da Amazon Web Services, com mais de 10 anos de experiência em bancos de dados. Atua desenhando soluções e estratégias de migração a fim de educar e habilitar empresas globais em suas jornadas para a AWS.
David Carvalho Queiroz é Senior Database Consultant no time de Professional Services da Amazon Web Services, com mais de 10 anos de experiência em bancos de dados. Atua desenhando soluções e estratégias de migração a fim de educar e habilitar empresas globais em suas jornadas para a AWS.