O blog da AWS
Construa e orquestre pipelines ETL usando Amazon Athena e AWS Step Functions
Por Behram Irani, Sr Analytics Solutions Architect,
Dipankar Kushari, Sr Analytics Solutions Architect e
Rahul Sonawane, Principal Analytics Solutions Architect
Extrair, transformar e carregar (do inglês Extract, transform and Load – ETL) é o processo de ler dados de origem, aplicar regras de transformação a esses dados e carregá-los nas estruturas de destino. O ETL é realizado por vários motivos. Às vezes, o ETL ajuda a alinhar os dados de origem às estruturas de dados de destino, enquanto outras vezes o ETL é feito para derivar valor ao conjunto de dados limpando, padronizando, combinando, agregando e enriquecendo. Você pode executar ETL de várias maneiras e as opções mais populares são:
- ETL de forma programática usando o Apache Spark. O Amazon EMR e o AWS Glue oferecem suporte a esse modelo.
- ETL com SQL usando Apache Hive ou PrestoDB/Trino. O Amazon EMR oferece suporte a essas duas ferramentas.
- ETL com ferramentas de terceiros.
Muitas empresas preferem a opção ETL com SQL porque já têm desenvolvedores que entendem e escrevem consultas SQL. No entanto, esses desenvolvedores querem se concentrar em escrever consultas e não se preocupar em configurar e gerenciar a infraestrutura a ser utilizada.
O Amazon Athena é um serviço de consulta interativo que facilita a análise de dados no Amazon Simple Storage Service (Amazon S3) usando SQL padrão. O Athena é serverless, portanto, não há infraestrutura para gerenciar, e você paga apenas pelas consultas executadas.
Este artigo explora como você pode usar o Athena para criar pipelines de ETL e como orquestrar esses pipelines usando o AWS Step Functions.
Visão geral da arquitetura
O diagrama a seguir ilustra nossa arquitetura.
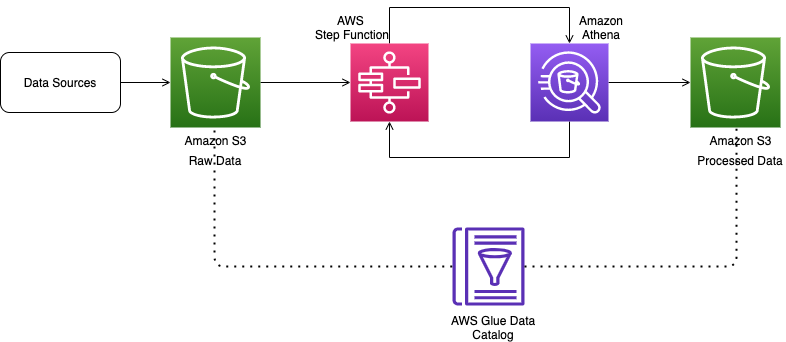
Os dados de origem são ingeridos primeiro em um bucket do S3, que preserva os dados como estão. Você pode ingerir esses dados no Amazon S3 de várias maneiras:
- AWS Database Migration Service (AWS DMS) para captura de dados em batch e a medida que os dados são capturados (em inglês change data capture ou CDC)
- Amazon Kinesis para streaming de dados
- AWS Transfer Family para ingerir arquivos no bucket de dados bruto
Depois que os dados de origem estiverem no Amazon S3 e supondo que eles tenham uma estrutura fixa, você poderá executar um crawler do AWS Glue para gerar automaticamente o schema ou fornecer o DDL como parte do pipeline de ETL. Um crawler do AWS Glue é o principal método usado pela maioria dos usuários do AWS Glue. Você pode usar um crawler para preencher o catálogo de dados do AWS Glue com tabelas. Um crawler pode rastrear vários armazenamentos de dados em uma única execução. Após a conclusão, o crawler cria ou atualiza uma ou mais tabelas no seu Catálogo de Dados. O Athena usa esse catálogo para executar consultas nas tabelas.
Depois que os dados brutos são catalogados, a transformação da origem para o destino é feita por meio de uma série de instruções Athena Create Table as Select (CTAS) e INSERT INTO. Os dados transformados são carregados em outro bucket do S3. Os arquivos também são particionados e convertidos no formato Parquet para otimizar o desempenho e o custo.
Preparando os dados
Para este artigo, usamos o conjunto de dados públicos de táxi de Nova York. Ele tem os dados de viagens feitas por táxis e veículos de aluguel na cidade de Nova York organizados em arquivos CSV por cada mês do ano a partir de 2009. Para nosso pipeline ETL, usamos dois arquivos contendo dados de táxi: um para demonstrar a criação inicial da tabela e carregar essa tabela usando CTAS, e o outro para demonstrar as inserções de dados em andamento nessa tabela usando a instrução INSERT INTO. Também usamos um arquivo de pesquisa para demonstrar união, transformação e agregação nesse pipeline de ETL.
- Crie um novo bucket do S3 com um nome exclusivo em sua conta.
Vamos utilizar esse bucket para copiar os dados brutos do conjunto de dados públicos de táxi de Nova York e armazenar os dados processados pelo Athena ETL.
- Crie os prefixos S3
athena, nyctaxidata/data, nyctaxidata/lookup, nyctaxidata/optimized-data e nyctaxidata/optimized-data-lookupdentro deste bucket recém-criado.
Esses prefixos são usados no código Step Functions fornecido posteriormente neste artigo.
- Copie os arquivos de dados de táxi do bucket público
nyc-tlcdescrito no registro do conjunto de dados público de táxi de Nova York para janeiro e fevereiro de 2020 no prefixonyctaxidata/datado bucket S3 que você criou em sua conta. - Copie o arquivo de pesquisa no prefixo
nyctaxidata/lookupque você criou.
Crie um pipeline de ETL usando a integração do Athena com o Step Functions
O Step Functions é um serviço de fluxo de trabalho visual low-code usado para orquestrar serviços da AWS, automatizar processos de negócios e criar máquina de estado serveless. Por meio de sua interface visual, você pode criar e executar uma série de fluxos de trabalho com pontos de verificação e orientados a eventos que mantêm o estado do seu fluxo. A saída de uma etapa atua como uma entrada para a próxima. Cada etapa do seu fluxo é executada em ordem, conforme definido pela sua lógica de negócios.
A integração do serviço Step Functions com o Athena permite que você use o Step Functions para iniciar e interromper execuções de consultas e obter resultados de consultas.
Para o pipeline ETL neste post, mantemos o fluxo simples. No entanto, você pode criar um fluxo complexo usando diferentes recursos do Step Functions.
O fluxo do pipeline é o seguinte:
- Crie um banco de dados se ele ainda não existir no Catálogo de Dados. O Athena, por padrão, usa o Catálogo de Dados como seu metastore.
- Se não houver tabelas neste banco de dados, execute as seguintes ações:
- a. Crie a tabela para os dados brutos do táxi amarelo e a tabela bruta para os dados de pesquisa.
- b. Use o CTAS para criar as tabelas de destino e use as tabelas brutas criadas na etapa anterior como entrada na instrução SELECT. O CTAS também particiona a tabela de destino por ano e mês e cria arquivos Parquet otimizados no bucket do S3 de destino.
- c. Use uma exibição para demonstrar as partes de junção e agregação do ETL.
- Se houver alguma tabela nesse banco de dados, itere a lista de todos os arquivos CSV restantes e processe usando a instrução INSERT INTO.
Casos de uso diferentes podem tornar o pipeline de ETL bastante complexo. Você pode estar obtendo dados contínuos da origem com o AWS DMS no modo batch ou CDC ou pelo Kinesis no modo de streaming. Isso requer mecanismos para processar todos esses arquivos durante uma janela específica e marcá-lo como concluído para que, na próxima vez que o pipeline for executado, ele processe apenas os arquivos recém-chegados. Em vez de adicionar DDL manualmente no pipeline, você pode adicionar etapas do crawler do AWS Glue no pipeline do Step Functions para criar um schema para os dados brutos. Em vez de uma visualização para agregar dados, talvez seja necessário criar uma tabela separada para manter os resultados prontos para consumo. Além disso, muitos casos de uso obtêm dados de alteração como parte do feed, que precisam ser mesclados com os conjuntos de dados de destino. Etapas extras no pipeline Step Functions são necessárias para processar esses dados caso a caso.
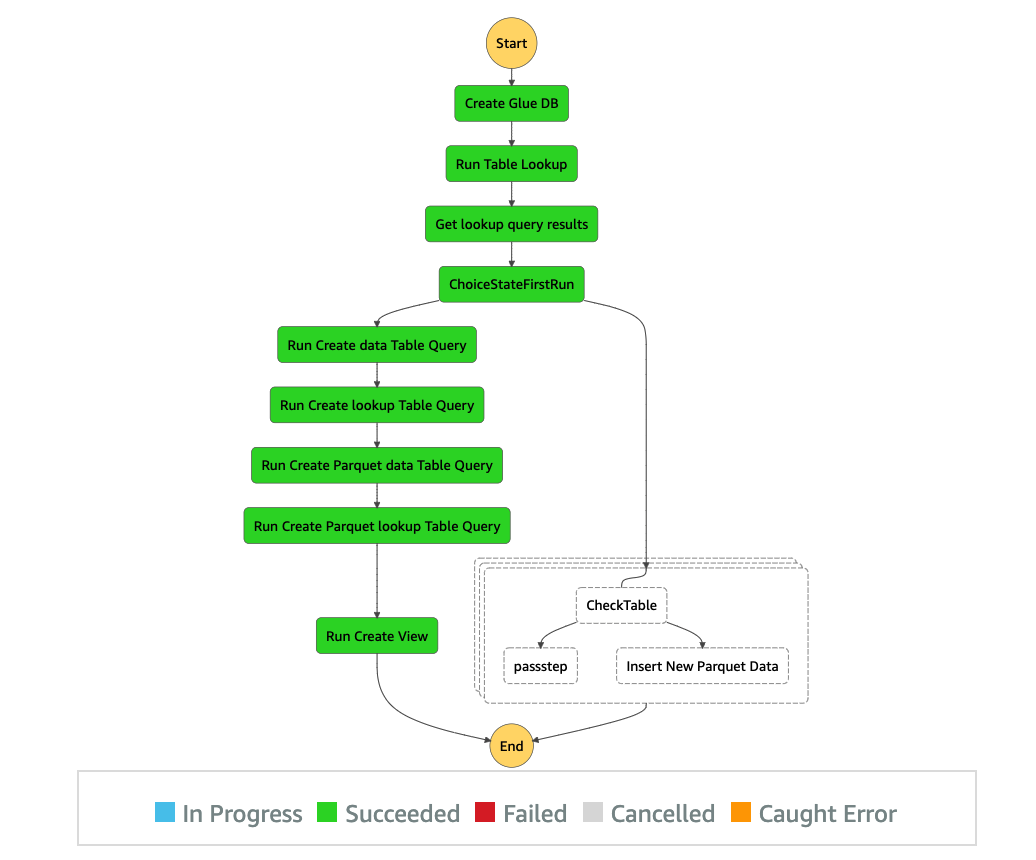
O código a seguir para o pipeline Step Functions cobre o fluxo anterior que descrevemos. Para obter mais detalhes sobre como começar a usar o Step Functions, consulte a documentação. Substitua os nomes do bucket do S3 pelo nome exclusivo do bucket que você criou na sua conta.
Na primeira vez que executamos esse pipeline, ele segue o caminho do CTAS e cria a visualização de agregação.
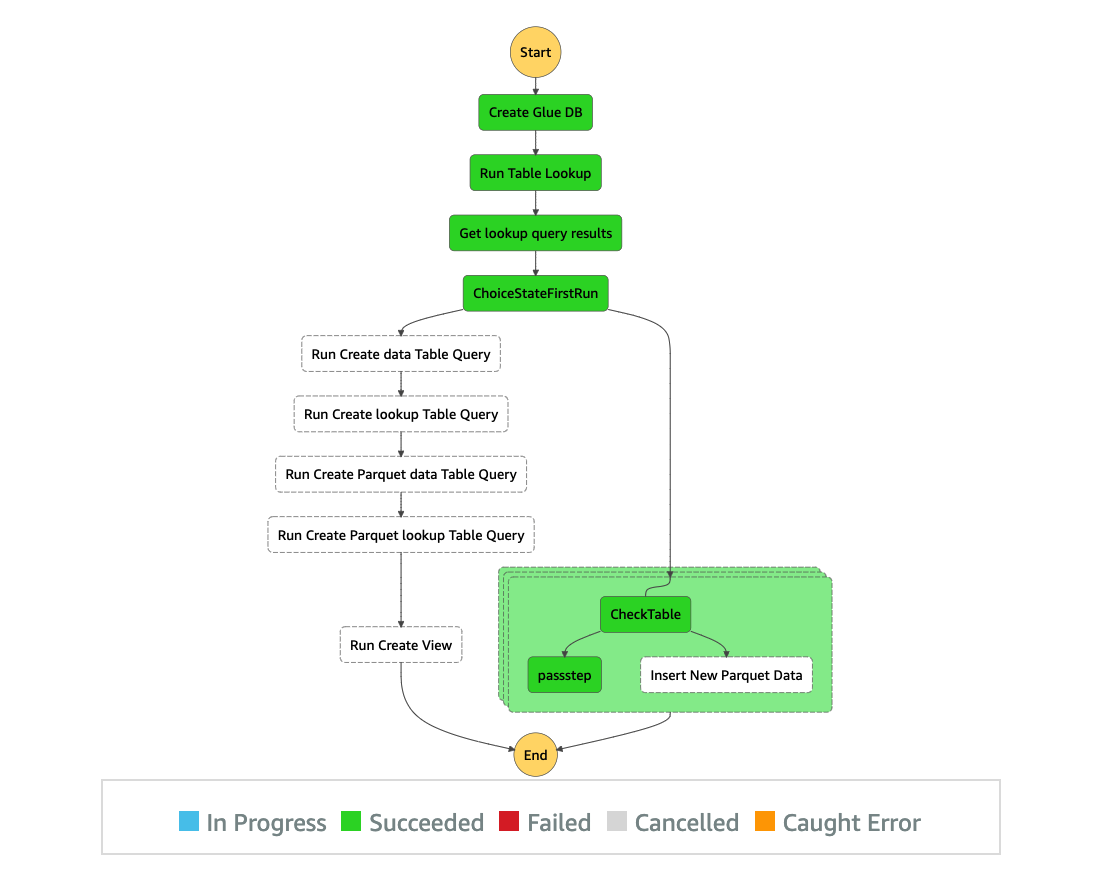
Na segunda vez que o executamos, ele segue o caminho da instrução INSERT INTO para adicionar novos dados às tabelas existentes.
Quando usar esse padrão
Você deve usar esse padrão quando os dados brutos estiverem estruturados e os metadados puderem ser facilmente adicionados ao catálogo.
Como as cobranças do Athena são calculadas pela quantidade de dados varridos, esse padrão é mais adequado para conjuntos de dados que não são muito grandes e precisam de processamento contínuo.
Esse padrão é mais adequado para converter dados brutos em formatos colunares, como Parquet ou ORC, e agregar um grande número de arquivos pequenos em arquivos maiores ou particionar e agrupar seus conjuntos de dados.
Conclusão
Neste post, mostramos como usar o Step Functions para orquestrar um pipeline ETL no Athena usando instruções CTAS e INSERT INTO.
Como próximas etapas para aprimorar esse pipeline, considere o seguinte:
- Crie um pipeline de ingestão que coloque dados continuamente no bucket bruto do S3 em intervalos regulares
- Adicione uma etapa do crawler do AWS Glue no pipeline para criar automaticamente o schema bruto
- Adicione etapas extras para identificar dados de alteração e mesclar esses dados com o destino
- Adicionar mecanismos de tratamento e notificação de erros no pipeline
- Agende o pipeline usando o Amazon EventBridge para ser executado em intervalos regulares
Este artigo foi traduzido do Blog da AWS em Inglês.
Sobre os autores
 Behram Irani, Sr Analytics Solutions Architect
Behram Irani, Sr Analytics Solutions Architect
 Dipankar Kushari, Sr Analytics Solutions Architect
Dipankar Kushari, Sr Analytics Solutions Architect
 Rahul Sonawane, Principal Analytics Solutions Architect
Rahul Sonawane, Principal Analytics Solutions Architect
Tradutora
 Erika Nagamine é Technical Trainer na AWS
Erika Nagamine é Technical Trainer na AWS