O blog da AWS
Escolhendo Serverless: a história da migração da Babbel
Por Equipe editorial da AWS
Quem é a Babbel?
A Babbel é um ecossistema completo de ofertas de aprendizado de idiomas, incluindo o aplicativo de aprendizado de idiomas mais vendido do mundo. Com mais de 10 milhões de assinaturas vendidas e mais de 60.000 cursos para 14 idiomas, criamos o destino número 1 para estudantes de idiomas em todo o mundo. Executamos nossa plataforma na Amazon Web Services (AWS) desde o primeiro dia com o lançamento de nosso produto em 2007 e somos frequentemente os primeiros a adotar novas ofertas de serviços da AWS. Como nosso ecossistema de aprendizagem da Babbel é puramente digital, ele é fortemente dependente da tecnologia subjacente, que deve ser não apenas confiável e estável, mas também escalável a qualquer momento. Isso traz desafios e oportunidades ao longo do caminho, especialmente à medida que a oferta de produtos cresce e o cenário de serviços muda.
A Babbel vem expandindo nossa base de alunos constantemente e nosso tráfego aumentou posteriormente de 2007-2020. Durante 2020, a base de alunos da Babbel cresceu substancialmente com um aumento de duas a três vezes no tráfego dos EUA e de nossos principais mercados europeus. Com as diferentes regulamentações globais enfrentadas pela pandemia, muitas pessoas estavam optando por aprender um novo idioma ou melhorar suas habilidades linguísticas. Isso criou picos adicionais no tráfego de entrada que não haviam ocorrido nessa escala antes. Durante tudo isso, não questionamos se nossa infraestrutura seria desafiada pelas mudanças nas demandas dos usuários.
No entanto, antes de 2020, a plataforma que criamos na Babbel, que hospedava os serviços da Babbel, não estava aproveitando todos os serviços sem servidor da AWS. Ele dependia de uma pilha antiga em execução no AWS OpsWorks, que não se encaixava mais bem no que era necessário. Neste artigo, descrevemos o que levou a Babbel a pensar sobre a mudança, as opções que consideramos e como finalmente migramos nossas cargas de trabalho de produção para o Amazon ECS no AWS Fargate e no AWS Lambda.
Por que mudar nossa arquitetura?
Estando em um ambiente dinâmico e em constante crescimento, estamos motivados a mudar e melhorar as coisas. O que procuramos são oportunidades em que as melhorias proporcionem uma experiência de aprendizado aprimorada para nossos alunos. Como você pode imaginar, priorizar tópicos técnicos nem sempre se traduz facilmente em uma experiência aprimorada do aluno, mas há alguns pilares que tomamos como sinais:
- Acelerando a velocidade de desenvolvimento e os tempos de liberação
- Reduzir o trabalho de manutenção
- Ter e manter um ambiente atualizado
- Melhoria dos tempos de entrega
Antes de iniciar o projeto, estávamos executando uma versão antiga do OpsWorks, que exigia que usássemos uma versão desatualizada do Chef para gerenciar a configuração das instâncias do EC2 do OpsWorks. Essas instâncias foram baseadas em um tipo de instância mais antigo e usando uma versão do Ubuntu que estava chegando perto de seu ciclo de lançamento de fim de vida, então a ação era definitivamente necessária. Atualizar os livros de receitas do Chef para uma nova versão do Chef, atualizar a versão do Ubuntu e atualizar as instâncias antigas do EC2 do OpsWorks levaria um tempo considerável. Além disso, nossos tempos de implantação, reversão e atualização estavam consumindo muitas horas do desenvolvedor no trabalho de manutenção, o que queríamos diminuir. No caso de picos rápidos no tráfego, tivemos tempos de escalonamento mais longos do que gostaríamos, e o escalonamento automático não era confiável. Em alguns casos, levou até 25 minutos para adicionar instâncias do EC2 adicionais ao cluster do OpsWorks. Para balanceamento de carga, estávamos limitados a usar o ELB clássico, que não tinha todos os recursos que gostaríamos de usar, como Autenticação via Cognito e Roteamento. Esses recursos estavam disponíveis no Application Load Balancers (ALBs), mas o OpsWorks não era compatível com ALBs na época. Dadas essas circunstâncias, concluímos que a solução ideal deveria abordar esses tópicos, o que significava que tínhamos que nos afastar da configuração do OpsWorks EC2.
Considerando as opções de migração
Antes de analisar as possíveis soluções técnicas, discutimos qual era a solução ideal para nós do ponto de vista dos recursos. Concordamos que, idealmente, a solução deveria
- Integre-se bem à nossa arquitetura existente da AWS e ao nosso investimento e estrutura do Terraform
- Seja ativamente desenvolvido e atualizado com uma equipe dedicada de serviço e suporte
- Libere tempo operacional e de manutenção para nos permitir trabalhar nas coisas que agregam mais valor aos alunos ou às equipes de engenharia da Babbel
Ficou claro para nós que a solução era ficar sem servidor. Continuamos analisando as soluções disponíveis para nos afastarmos do OpsWorks e substituirmos toda a camada de computação e hospedagem. As opções que consideramos foram:
- AWS Lambda
- Amazon Elastic Container Service (Amazon ECS)
- Serviço Amazon Elastic Kubernetes (Amazon EKS)
Chegamos às seguintes conclusões sobre essas opções:
AWS Lambda
Idealmente, estaríamos executando quase tudo no Lambda. O dimensionamento é automatizado por padrão, sem necessidade de configuração, não há instâncias para manter, sem atualizações de sistema operacional e segurança que precisamos fazer nós mesmos na camada do sistema operacional e as implantações/reversões são instantâneas. Para alguns dos serviços, isso foi possível e tomamos a decisão de usar o Lambda para eles. No entanto, decidimos que o Lambda não seria a solução certa para todos os nossos serviços. Tínhamos alguns serviços multiuso que exigiam o Docker e, no momento de nossa avaliação no início de 2020, o suporte do Lambda para formato de imagem de contêiner ainda não era um recurso.
Amazon ECS
Como o Lambda não era uma opção para esses tipos de serviços, tivemos que tomar uma decisão sobre qual plataforma executar nossos contêineres (Docker). Avaliamos o Amazon EKS e o Amazon ECS e tínhamos as quatro opções a seguir para escolher:
- ECS no EC2
- ECS no Fargate
- EKS no EC2
- EKS no Fargate
Como usar o ECS no Fargate e o ECS no EC2 são muito semelhantes, eles eram uma solução alternativa para todo o ecossistema versus o Kubernetes e o EKS (no EC2 ou no Fargate), então avaliamos os prós e os contras do uso de qualquer pilha de tecnologia. Em 2019, a execução do ECS no Fargate foi lançada e inicialmente perdemos alguns recursos de que precisávamos naquela época (por exemplo, tags de alocação de custos para contêineres). Nossos gerentes de conta da AWS nos ajudaram com nossas solicitações de recursos e essas funcionalidades foram implementadas posteriormente. Depois que os recursos foram lançados, não havia bloqueadores para transferirmos todos os nossos serviços recém-Dockerized para o ECS no Fargate. Entre o EC2 e o Fargate, o Fargate foi a melhor escolha para nossa arquitetura, pois elimina o esforço de manutenção das máquinas EC2 subjacentes. Essa pilha de tecnologia também foi fácil de integrar com os serviços restantes da AWS e com nossa base de código Terraform, que já tínhamos experiência em gerenciar.
Amazon EKS
Ao ponderar os prós e os contras de executar o EKS, decidimos que não era necessário para nosso caso de uso e configuração de infraestrutura. Nosso principal objetivo era ter uma plataforma que escalasse nossos contêineres Docker com o mínimo de esforço e com o menor número de alterações no restante do nosso ambiente e em nossa integração de serviços da AWS. Além disso, queríamos garantir que a quantidade de trabalho operacional fosse mínima, pois não agrega nenhum valor aos nossos alunos. Com o Kubernetes, sentimos que teríamos uma curva de aprendizado mais acentuada, precisaríamos fazer mais alterações em nosso ambiente existente e ter mais trabalho operacional e de manutenção. Pensamos que poderíamos ter uma melhor separação entre desenvolvimento e infraestrutura com uma infraestrutura mais centrada na AWS como código, que estamos gerenciando via Terraform (um exemplo disso seria usar o AWS IAM). Em resumo, queríamos mudar nosso cenário de computação/hospedagem sem ter que fazer uma adaptação maior de nossos sistemas e serviços e a configuração de como executamos implantações, gerenciamos nossas redes, grupos de segurança e assim por diante.
Em 2019/início de 2020, o EKS ainda era um serviço mais novo. Na época, nossa decisão de não adotar o EKS (ou Kubernetes) era uma preocupação em relação ao suporte aos recursos do Kubernetes executados na AWS. Embora o EKS use o código upstream do Kubernetes (sem modificações), nossa preocupação era o delta entre as versões mais recentes do Kubernetes e as versões disponíveis com o EKS. Na época, não tínhamos certeza se teríamos acesso a todos os recursos mais recentes do Kubernetes imediatamente. Nesse caso, não tivemos problemas com relação a um recurso específico e decidimos que queríamos usar um serviço AWS First, em vez de um serviço de código aberto gerenciado pela AWS. Certamente há muitas vantagens em usar o Kubernetes, como a capacidade de executar um ambiente de nuvem híbrida com controle mais refinado, mas isso não era importante para nós. Em resumo, devido aos motivos acima mencionados, decidimos usar o ECS em vez do EKS (portanto, não comparamos se deveríamos executar o EKS no EC2 ou no Fargate).
Migrando as cargas de trabalho
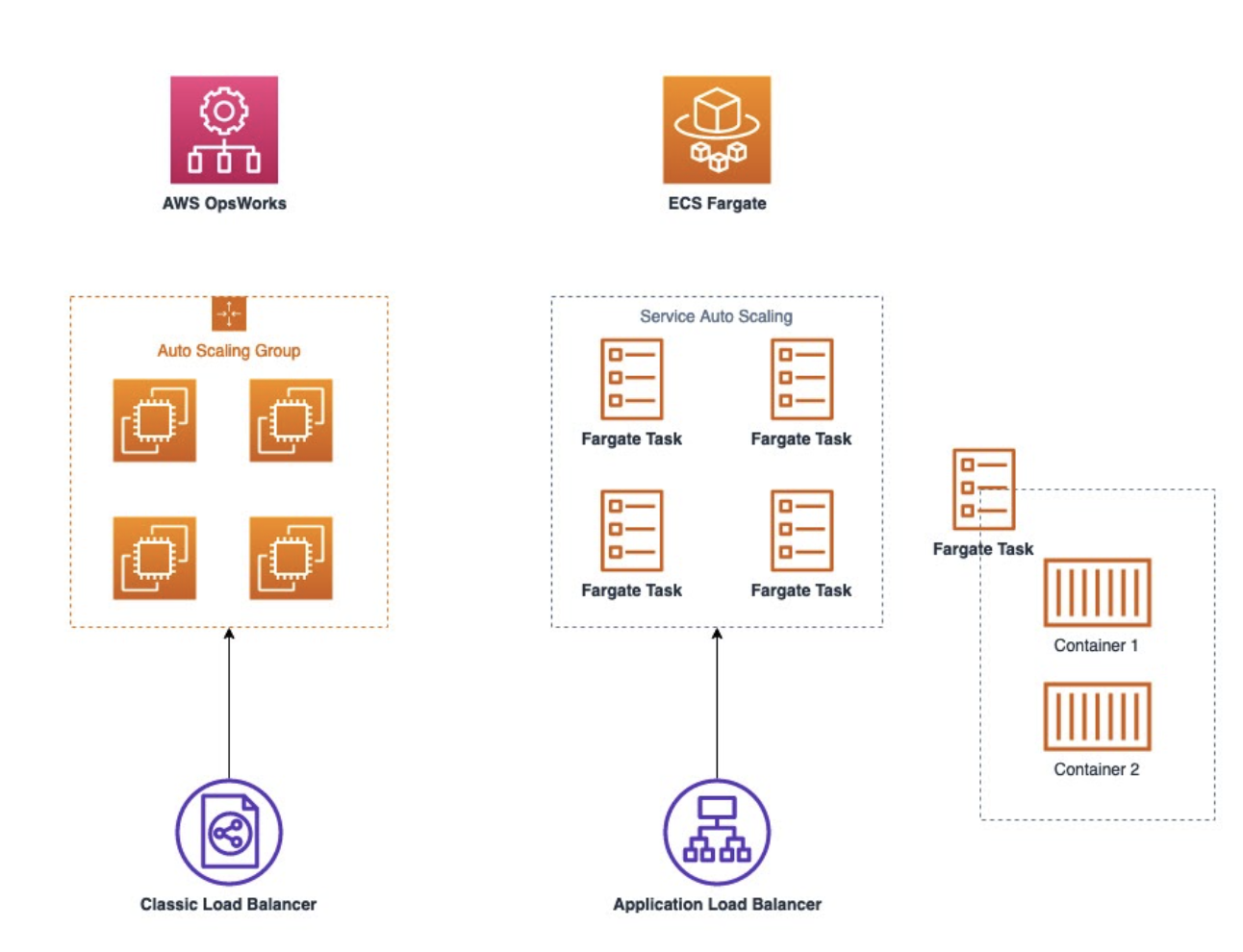
Como tínhamos experiência anterior na execução do AWS Lambda, a migração inicial dos serviços do AWS OpsWorks para o AWS Lambda foi rápida e sem problemas imprevistos. Como não tínhamos nenhuma experiência com o AWS Fargate, tivemos que encaixar todos os nossos serviços restantes antes de começar a migração para o AWS Fargate. Além dos desafios técnicos que tivemos que superar devido à falta de experiência nesse tipo de migração, foi necessária muita coordenação entre equipes, pois a migração estava atingindo mais de 10 serviços, tanto voltados para o cliente quanto para serviços internos. Naturalmente, os primeiros serviços foram os que levaram mais tempo, pois tínhamos que descobrir qual era a melhor maneira de fazer as implantações, ajustar nosso escalonamento automático e garantir que a migração dos serviços para o Docker funcionasse conforme o esperado. Começamos a migrar serviços internos que não tiveram impacto no produto, continuando com os serviços internos que tiveram impacto no cliente e terminando com os serviços voltados para o cliente no final. A configuração final agora varia, porque nossos serviços têm diferentes integrações e ambientes (ou seja, às vezes usamos o AWS Cognito com ALBs ou temos CDNs na frente dos ALBs etc.). Aqui está uma comparação simplificada de antes/depois ilustrada abaixo:
Conclusão
Depois de concluirmos as mudanças técnicas do nosso projeto, era hora de avaliar se alcançamos nossos objetivos. Para resumir, os pontos problemáticos iniciais foram:
- Alto esforço de manutenção do OpsWorks/Chef/EC2, gastando um tempo significativo de desenvolvimento na manutenção em vez de melhorar o aplicativo para os clientes
- Dimensionamento não confiável com longo tempo de aquecimento de mais de 20 minutos devido à pilha subjacente do OpsWorks e do Chef
- Uma configuração com o OpsWorks que não era capaz de usar Application Load Balancers, que tinha recursos que queríamos usar
Com a mudança para o Amazon ECS no AWS Fargate e o AWS Lambda, obtivemos os seguintes benefícios:
- Lançamentos e tempos de reversão mais rápidos com tempos de manutenção reduzidos, permitindo que nos concentremos na criação de novos recursos para nossos alunos. Passamos dos tempos de implantação de 25 a 30 minutos por cluster do OpsWorks para implantações/reversões quase instantâneas com o AWS Lambda e o Amazon ECS no AWS Fargate.
- Escalabilidade automatizada rápida em comparação com nossa configuração anterior. Isso acabou sendo útil quando o rápido aumento inesperado do tráfego em março de 2020 produziu picos de demanda 24 horas por dia e em todo o mundo.
- Usar um serviço da AWS que integramos com outros serviços da AWS para diferentes finalidades, como integrar varreduras de segurança como parte do nosso processo de lançamento usando a verificação de imagem do Amazon ECR ou a autenticação direta via ALBs
- Custo reduzido como efeito colateral da utilização de nossas cargas de trabalho de computação de forma mais eficiente. Descrevemos isso em detalhes em https://www.babbel.com/en/magazine/how-to-do-more-with-fewer-servers
Sobre a Babbel
A Babbel é conduzida por uma missão: Todos. Aprendendo. Idiomas. Isso significa criar produtos que ajudem as pessoas a se conectarem e se comunicarem entre culturas. A Babbel, a Babbel Live e a Babbel for Business usam linguagens em situações reais, com pessoas reais. E funciona: estudos com a Yale University, City University of New York e Michigan State University comprovam sua eficácia. A chave é uma mistura de humanidade e tecnologia. Mais de 60.000 aulas em 14 idiomas são feitas à mão por mais de 150 linguistas, com os comportamentos dos usuários continuamente analisados para moldar e ajustar a experiência do aluno. Da sede em Berlim e Nova York, 750 pessoas de mais de 60 nacionalidades representam todas as diferenças que tornam os humanos únicos. A Babbel é o aplicativo de aprendizado de idiomas mais lucrativo do mundo, com mais de 10 milhões de assinaturas vendidas. Para obter mais informações, visite www.babbel.com ou baixe os aplicativos na App Store ou Play Store.
Este artigo foi traduzido do Blog da AWS em Inglês.
Sobre o autor
 Gyorgi Stoykov MSc. é gerente sênior que trabalha na equipe de infraestrutura da Babbel, atualmente sediada em Berlim. Ele tem uma vasta experiência em computação em nuvem e infraestrutura em uma variedade de ambientes, desde empresas da Fortune 500, start-ups, bem como academia. Ele é profundamente apaixonado por DevOps, AWS e por ajudar as organizações a criar produtos nativos da nuvem aplicando as melhores práticas ágeis e de DevOps.
Gyorgi Stoykov MSc. é gerente sênior que trabalha na equipe de infraestrutura da Babbel, atualmente sediada em Berlim. Ele tem uma vasta experiência em computação em nuvem e infraestrutura em uma variedade de ambientes, desde empresas da Fortune 500, start-ups, bem como academia. Ele é profundamente apaixonado por DevOps, AWS e por ajudar as organizações a criar produtos nativos da nuvem aplicando as melhores práticas ágeis e de DevOps.