Live streaming content for 3.2 million viewers using AWS with Fetch
Learn how rewards service provider Fetch designed and implemented an ambitious live giveaway to drive new users to its app by using AWS.
Benefits
Overview
Fetch Rewards (Fetch) wanted to push the boundaries of traditional advertising by live streaming an innovative giveaway during the 2025 Super Bowl. With over 100 million viewers expected to tune in to the game, a live sweepstakes was a unique opportunity for Fetch to acquire new users and reengage lapsed ones.
Fetch had only 103 days to design a massively scalable architecture to support the potential traffic spikes during the giveaway. By building a live streaming architecture on Amazon Web Services (AWS), Fetch brought its vision to life. Through meticulous planning, extensive testing, and close collaboration, Fetch successfully delivered a groundbreaking live streamed sweepstakes, increasing brand awareness and user engagement.
Figure 1. Fetch's giveaway architecture
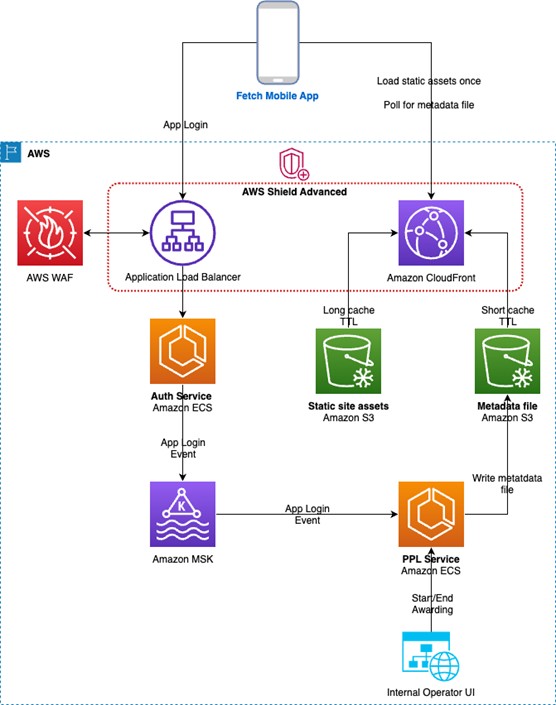
About Fetch Rewards
Fetch Rewards offers a mobile app that rewards users for everyday activity. Users can earn gift cards for buying specific products, shopping at participating brands, and playing games within the app.
Opportunity | Using AWS to deliver an unprecedented event for Fetch
With an estimated 120 million viewers tuning in to the 2025 Super Bowl, Fetch wanted to support a potential record number of people engaging with its app. The Super Bowl ad would invite viewers to download the Fetch app and create an account for the chance to win 10,000 dollars.
The company needed to solve several challenges: accommodating the traffic increase during the live stream, transitioning viewers back into the normal Fetch app experience afterward, and delivering a high-quality live streaming experience to millions. But Fetch didn’t know how many people would participate. “We’ve done promotions through standard channels, such as social media, billboards, and some commercials,” says Eric Lloyd, vice president of engineering at Fetch. “We’ve never done a promotion of this scale before.”
Fetch assembled a team to create and deliver the live stream, preparing for anywhere from 500,000 to 20 million viewers. Knowing that its backend services couldn’t support this volume, Fetch opted to use a content delivery network. This would optimize content availability, page load time, and bandwidth costs—regardless of the volume of traffic. After evaluating some providers, Fetch found that most of them couldn’t deliver the capacity or scalability required to support tens of millions of potential participants. “That’s when we knew that we needed to engage AWS,” says Lloyd.
Solution | Live streaming to millions by using Amazon CloudFront
Fetch was already using AWS as its primary cloud provider for its app, so adopting AWS services to support the live streaming experience was a natural choice. “We wanted to take things that were already running on AWS and figure out how to make them work for potentially 100 times the normal requests per second,” says Lloyd.
The company engaged AWS Enterprise Support, which assisted Fetch in outlining and validating its architecture. To plan capacity and identify risks, Fetch used AWS Countdown, which provides expert engineering support for high-impact launches, migrations, and peak events on AWS. Fetch selected Amazon CloudFront, a service that securely delivers content with low latency and high transfer speeds, to serve all web traffic and half of the video stream. Amazon Simple Storage Service (Amazon S3)—an object storage service offering industry-leading scalability—acted as the origin.
Fetch also used Amazon Managed Streaming for Apache Kafka (Amazon MSK), a streaming data service that manages Apache Kafka infrastructure and operations. This way, it could select and announce the winners in near real time (NRT) while successfully handling traffic spikes in its app. “Amazon MSK was absolutely critical for that piece of the app,” says Lloyd.
The big challenge was distributing dynamic updates, such as announcing winners, to millions of devices simultaneously, allowing every device to connect directly to Fetch’s backend services. “It would have been impossible to scale our services to handle the load,” says Lloyd. The solution was to generate updates, write them to Amazon S3, and use Amazon CloudFront to serve them at scale, implementing Amazon CloudFront Origin Shield to reduce the origin load. “What would have resulted in hundreds of thousands of requests was collapsed into a single request,” says Lloyd.
Strengthening the security of backend services was an equally critical consideration. So, Fetch extended its use of AWS WAF, which businesses implement to protect web applications from common bugs and bots, to all existing Amazon CloudFront distributions and Application Load Balancers—which load balance HTTP and HTTPS traffic—that supported backend services for the event. The company also expanded its use of AWS Shield Advanced for automatic mitigation of sophisticated distributed denial of service events.
In the weeks leading up to the Super Bowl, Fetch ran daily stress tests to simulate peak traffic loads and identify potential bottlenecks. The month before the event, the AWS team collaborated closely with the Fetch team to create a realistic test event to validate scaling strategies and verify that the infrastructure could support the traffic. The test uncovered some issues that the teams quickly resolved—ultimately helping improve the experience for the actual event. The AWS team assisted with NRT monitoring of the events and identifying solutions for bottlenecks.
The teams also conducted a comprehensive scaling exercise to check that after the live stream, users would be transitioned back into the regular app experience smoothly. This exercise included evaluating AWS services across Fetch’s entire backend stack to ensure that the proper scaling strategies and capacity were in place to support the event.
“By the end, we didn’t need to think about the motions we were going to go through,” says Lloyd. “All the minor issues were ironed out by that time. It would not have gone that smoothly if we hadn’t done so much testing in production.”
Outcome | Achieving business objectives through strong teamwork
During the event, 3.2 million people visited the Fetch app, resulting in 1.3 million new sign-ups. The traffic through Amazon CloudFront peaked at 2.67 million requests per second, with fans across the country tuning in to the groundbreaking live streaming event.
With an average view time of 9 minutes, Fetch achieved its goal of increasing engagement while showcasing the solution’s scalability. The strategic ad initiative helped the company grow its user base and gain the confidence to produce more large-scale promotional events.
This experience has proved that teamwork is essential to delivering unique and innovative solutions. “Finding key collaborators like AWS means that we don’t need to take the time to become experts in tech,” says Lloyd. “If you’re going to do something at this scale, you need to have a great team. I think that Fetch is set up for success in the way that we’re organized. It’s in our culture and our DNA.”
Finding key collaborators like AWS means that we don’t need to take the time to become experts in tech.
Eric Lloyd
Vice President of Engineering