- AWS Solutions Library
- Guidance for Data Lakes on AWS
Guidance for Data Lakes on AWS
Overview
How it works
AWS Serverless Data Lake Framework
This architecture diagram shows how to build a data lake on AWS in addition to demonstrating how to process, store, and consume data using serverless AWS analytics services.
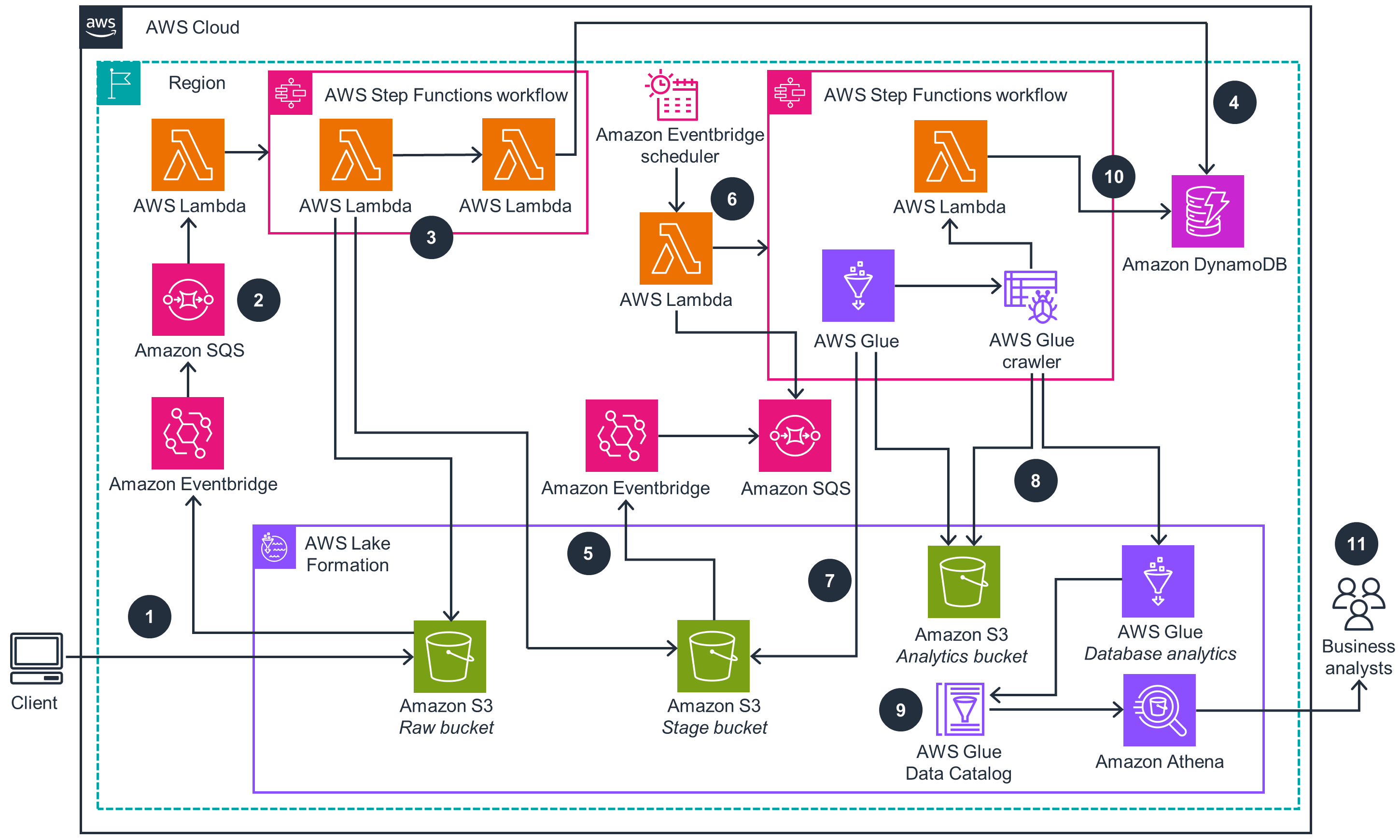
Multi-Source Analytics Lakehouse with AI-Powered Insights
This architecture diagram shows how to build a data lake on AWS in addition to demonstrating how to process, store, and consume data using Lakehouse for Amazon SageMaker and Amazon SageMaker Unified Studio.
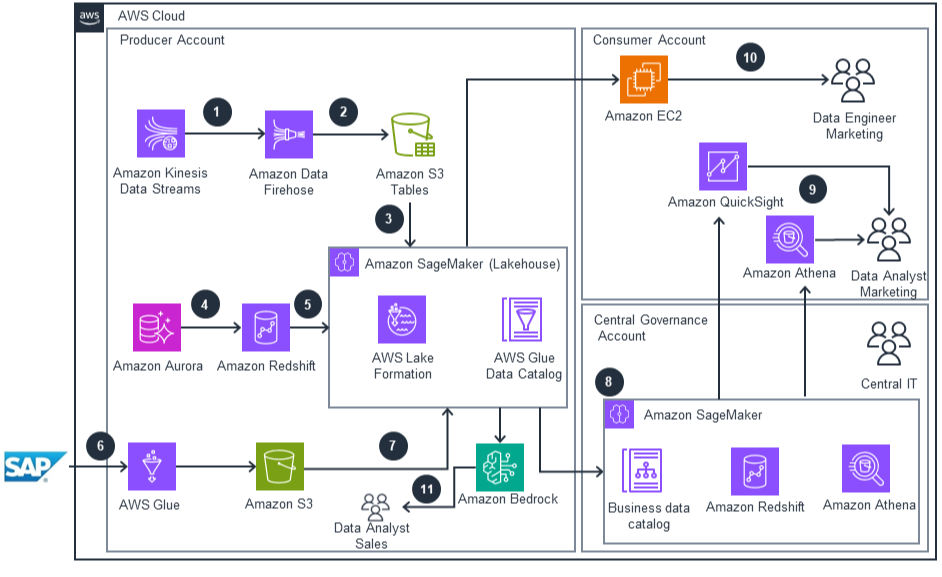
Deploy with confidence
Ready to deploy? Review the sample code on GitHub for detailed deployment instructions to deploy as-is or customize to fit your needs.
Benefits
Architecture 1: Deploy a serverless data lake framework that transforms raw data into actionable insights using AWS analytics services. Enable your business analysts to query processed data through Amazon Athena while maintaining comprehensive data governance through AWS Lake Formation.
Architecture 2: Deploy a unified data lakehouse architecture that seamlessly ingests data from diverse sources including streaming inventory, relational databases, and enterprise systems like SAP. Reduce development time by leveraging zero-ETL capabilities and open table formats that eliminate complex data pipeline engineering.
Architecture 1: EImplement automated, event-driven data pipelines that efficiently transform and catalog your data across its lifecycle. AWS Step Functions orchestrates the workflow while AWS Glue handles ETL processes, converting data to optimized formats for improved query performance.
Architecture 2: Enable business teams to generate actionable insights through natural language queries with Amazon Bedrock and visualize results with Amazon QuickSight. Query data through existing spark platform or leveraging the AWS services under one unified platform. Marketing and sales teams can independently access the data they need while IT maintains centralized governance through AWS Lake Formation.
Architecture 1: Create a unified data environment where teams can access and analyze data through their preferred tools while maintaining centralized governance. AWS Lake Formation provides fine-grained access controls while Amazon SageMaker and Amazon Bedrock enable advanced analytics and AI-powered insights from your data lake.
Architecture 2: Implement a secure, well-governed data environment using Lakehouse for Amazon SageMaker with federated catalogs and AWS Lake Formation controls. This architecture allows you to maintain data security and compliance while enabling cross-account data sharing between producer and consumer accounts.
Disclaimer
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages