ข้อมูลสังเคราะห์คืออะไร
ข้อมูลสังเคราะห์คืออะไร
ข้อมูลสังเคราะห์เป็นข้อมูลที่ไม่ได้สร้างขึ้นโดยมนุษย์ซึ่งเลียนแบบข้อมูลในโลกแห่งความเป็นจริง ข้อมูลประเภทนี้จะสร้างขึ้นจากอัลกอริทึมการประมวลผลและการจำลองโดยใช้เทคโนโลยีปัญญาประดิษฐ์ช่วยสร้าง ชุดข้อมูลสังเคราะห์จะมีคุณสมบัติทางคณิตศาสตร์เหมือนกับข้อมูลจริงที่ใช้สร้างข้อมูลดังกล่าวขึ้น แต่จะไม่มีข้อมูลใดๆ ที่เหมือนกันกับข้อมูลที่อยู่ในชุดข้อมูลจริง มีองค์กรจำนวนมากที่ใช้ข้อมูลสังเคราะห์เพื่อการวิจัย การทดสอบ การพัฒนาใหม่ๆ และการวิจัยแมชชีนเลิร์นนิง นวัตกรรมล่าสุดในด้าน AI ได้ทำให้การสร้างข้อมูลสังเคราะห์สามารถดำเนินการได้อย่างมีประสิทธิภาพและรวดเร็ว แต่ก็ทำให้การดำเนินการดังกล่าวมีความสำคัญมากขึ้นในด้านกฎระเบียบข้อมูลเช่นกัน
ประโยชน์ของข้อมูลสังเคราะห์มีอะไรบ้าง
ข้อมูลสังเคราะห์มีประโยชน์หลายประการต่อองค์กร เราจะมาดูประโยชน์ดังกล่าวบางส่วนกันที่ด้านล่างนี้
สร้างข้อมูลได้อย่างไม่จำกัด
คุณสามารถสร้างข้อมูลสังเคราะห์ได้ตามความต้องการ และสามารถปรับขนาดได้อย่างแทบจะไม่มีขีดจำกัด เครื่องมือสร้างข้อมูลสังเคราะห์เป็นวิธีที่คุ้มค่าในการค้นหาข้อมูลเพิ่มเติม นอกจากนี้ เครื่องมือนี้ยังสามารถระบุประเภท (จัดหมวดหมู่หรือทำเครื่องหมาย) ข้อมูลที่สร้างขึ้นล่วงหน้า สำหรับกรณีการใช้งานของแมชชีนเลิร์นนิงได้ด้วย ซึ่งจะทำให้คุณสามารถเข้าถึงข้อมูลที่ได้รับการจัดโครงสร้างและระบุประเภทได้โดยไม่ต้องดำเนินการแปลงข้อมูลดิบตั้งแต่เริ่มต้น คุณยังสามารถเพิ่มข้อมูลสังเคราะห์ลงในปริมาณข้อมูลทั้งหมดที่มี เพื่อให้มีข้อมูลการฝึกอบรมเพื่อการวิเคราะห์เพิ่มเติมได้ด้วย
ปกป้องความเป็นส่วนตัว
อุตสาหกรรม เช่น สุขภาพ การเงิน และภาคกฎหมายมีข้อบังคับด้านความเป็นส่วนตัว ลิขสิทธิ์ และการปฏิบัติตามกฎระเบียบมากมายเพื่อปกป้องข้อมูลที่ละเอียดอ่อน อย่างไรก็ตาม อุตสาหกรรมดังกล่าวยังคงต้องใช้ข้อมูลเพื่อการวิเคราะห์และการวิจัย และมักจะต้องเอาท์ซอร์สข้อมูลไปยังบุคคลที่สามเพื่อให้สามารถใช้ประโยชน์เหล่านั้นได้อย่างเต็มที่ แต่แทนที่จะใช้ข้อมูลส่วนบุคคล เหล่าธุรกิจจากภาคอุตสาหกรรมสามารถใช้ข้อมูลสังเคราะห์เพื่อทำหน้าที่เดียวกับชุดข้อมูลส่วนตัวเหล่านี้ได้ ซึ่งจะสร้างข้อมูลที่คล้ายกันที่สามารถแสดงข้อมูลที่มีความสำคัญทางสถิติเช่นเดียวกันได้ โดยไม่ต้องเปิดเผยข้อมูลส่วนตัวหรือข้อมูลที่ละเอียดอ่อน เมื่อพิจารณาการสร้างข้อมูลสังเคราะห์จากชุดข้อมูลสดของการวิจัยทางการแพทย์ จะเห็นได้ว่าข้อมูลสังเคราะห์ที่สร้างขึ้นสำหรับการใช้งานดังกล่าวจะยังคงสามารถรักษาอัตราร้อยละของลักษณะทางชีวภาพและเครื่องหมายทางพันธุกรรมต่างๆ ได้เช่นเดียวกับชุดข้อมูลดั้งเดิม แต่ชื่อ ที่อยู่ และข้อมูลส่วนบุคคลอื่นๆ ของผู้ป่วยทั้งหมดจะเป็นข้อมูลปลอม
การลดอคติ
คุณสามารถใช้ข้อมูลสังเคราะห์เพื่อลดอคติในโมเดลการฝึก AI ได้ เนื่องจากโมเดลขนาดใหญ่มักจะฝึกบนข้อมูลที่เปิดเผยต่อสาธารณะ จึงทำให้อาจมีอคติในข้อความได้ นักวิจัยสามารถใช้ข้อมูลสังเคราะห์เพื่อเป็นตัวอย่างเปรียบเทียบกับภาษาหรือข้อมูลอคติใดๆ ที่โมเดล AI รวบรวมได้ ตัวอย่างเช่น หากเนื้อหาจากความคิดเห็นบางอย่างให้ความสำคัญกับกลุ่มใดกลุ่มหนึ่งมากเป็นพิเศษ คุณก็สามารถสร้างข้อมูลสังเคราะห์เพื่อปรับสมดุลของชุดข้อมูลโดยรวมได้
ข้อมูลสังเคราะห์มีประเภทใดบ้าง
ข้อมูลสังเคราะห์มีสองประเภทหลัก ได้แก่ ข้อมูลสังเคราะห์บางส่วนและข้อมูลสังเคราะห์เต็มรูปแบบ
ข้อมูลสังเคราะห์บางส่วน
ข้อมูลสังเคราะห์บางส่วนแทนที่บางส่วนของชุดข้อมูลจริงเท่านั้นด้วยข้อมูลสังเคราะห์ การดำเนินการดังกล่าวจะใช้เพื่อปกป้องส่วนที่ละเอียดอ่อนต่างๆ ของชุดข้อมูล ตัวอย่างเช่น หากต้องการวิเคราะห์ข้อมูลลูกค้าบางรายโดยเฉพาะ คุณก็สามารถสังเคราะห์แอตทริบิวต์ เช่น ชื่อ รายละเอียดการติดต่อ และข้อมูลในโลกแห่งความเป็นจริงอื่นๆ ที่อาจสามารถใช้ติดตามกลับไปยังบุคคลที่เฉพาะเจาะจงได้
ข้อมูลสังเคราะห์เต็มรูปแบบ
ข้อมูลสังเคราะห์เต็มรูปแบบจะใช้เมื่อคุณต้องการสร้างข้อมูลใหม่ขึ้นทั้งหมด ชุดข้อมูลสังเคราะห์เต็มรูปแบบจะไม่มีข้อมูลในโลกแห่งความเป็นจริงเลย อย่างไรก็ตาม ชุดข้อมูลดังกล่าวจะใช้ความสัมพันธ์ การแจกแจงพล็อต และคุณสมบัติทางสถิติเหมือนกับข้อมูลจริง แม้จะไม่ได้มาจากข้อมูลที่บันทึกจริง ชุดข้อมูลดังกล่าวก็ยังสามารถช่วยให้คุณได้รับข้อสรุปเดียวกันได้
ข้อมูลสังเคราะห์เต็มรูปแบบจะใช้เมื่อทำการทดสอบโมเดลแมชชีนเลิร์นนิง ซึ่งจะมีประโยชน์อย่างมาก เมื่อคุณต้องการทดสอบหรือสร้างโมเดลใหม่ แต่ไม่มีข้อมูลสำหรับฝึกจากโลกแห่งความเป็นจริงเพื่อปรับปรุงความแม่นยำของ ML เพียงพอ
ข้อมูลสังเคราะห์ถูกสร้างขึ้นอย่างไร
การสร้างข้อมูลสังเคราะห์เกี่ยวข้องกับการใช้วิธีการเชิงคำนวณและการจำลองเพื่อสร้างข้อมูล ผลลัพธ์ที่ได้จะเลียนแบบคุณสมบัติทางสถิติของข้อมูลในโลกแห่งความเป็นจริง แต่จะไม่มีข้อมูลในโลกแห่งความเป็นจริงอยู่ ข้อมูลที่สร้างขึ้นนี้อาจอยู่ในหลากหลายรูปแบบ ได้แก่ ข้อความ ตัวเลข ตาราง หรือประเภทที่ซับซ้อนมากขึ้น เช่น รูปภาพและวิดีโอ การสร้างข้อมูลสังเคราะห์มีสามวิธีหลักด้วยกัน โดยแต่ละวิธีมีระดับความแม่นยำและประเภทของข้อมูลที่แตกต่างกัน
การแจกแจงทางสถิติ
ในแนวทางนี้ ข้อมูลจริงจะได้รับการวิเคราะห์ก่อนเพื่อระบุการแจกแจงทางสถิติที่สำคัญ เช่น การแจกแจงแบบปกติ เอ็กซ์โพเนนเชียล หรือไคสแควร์ จากนั้น นักวิทยาศาสตร์ข้อมูลจะสร้างตัวอย่างสังเคราะห์จากการแจกแจงที่ระบุเหล่านี้เพื่อสร้างชุดข้อมูลที่คล้ายกับต้นฉบับในเชิงสถิติ
ตามโมเดล
ในแนวทางนี้ โมเดลแมชชีนเลิร์นนิงจะได้รับการฝึกเพื่อทำความเข้าใจและจำลองลักษณะของข้อมูลจริง เมื่อโมเดลได้รับการฝึกแล้ว จะสามารถสร้างข้อมูลเทียมที่เป็นไปตามการแจกแจงทางสถิติเช่นเดียวกับข้อมูลจริง แนวทางนี้มีประโยชน์อย่างยิ่งสำหรับการสร้างชุดข้อมูลแบบไฮบริด ซึ่งรวมคุณสมบัติทางสถิติของข้อมูลจริงเข้ากับองค์ประกอบสังเคราะห์เพิ่มเติม
วิธีการดีปเลิร์นนิง
สามารถนำเทคนิคขั้นสูง เช่น Generative Adversarial Network (GANs), Variational Autoencoders (VAE) และอื่นๆ มาใช้เพื่อสร้างข้อมูลสังเคราะห์ได้ วิธีการเหล่านี้มักใช้สำหรับประเภทข้อมูลที่ซับซ้อนมากขึ้น เช่น ภาพหรือข้อมูลแบบอนุกรมเวลา และสามารถสร้างชุดข้อมูลสังเคราะห์คุณภาพสูงได้
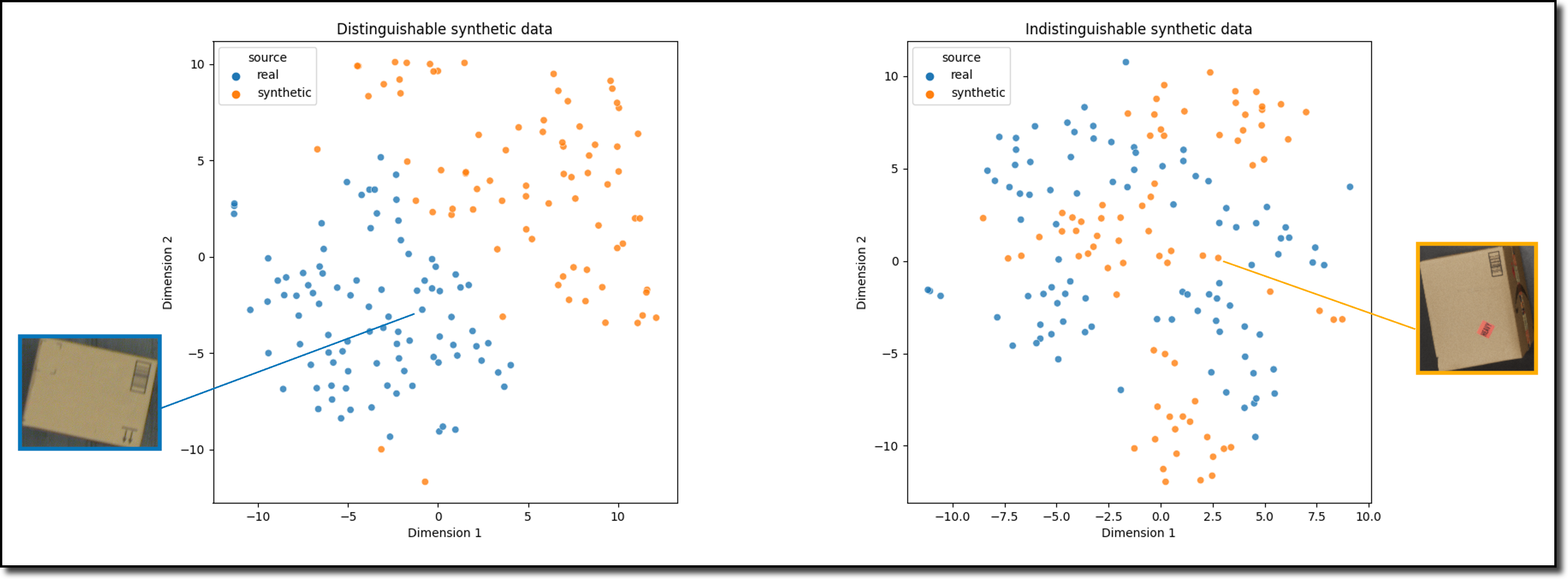
เทคโนโลยีการสร้างข้อมูลสังเคราะห์คืออะไร
เราสรุปเทคโนโลยีขั้นสูงบางอย่างที่คุณสามารถใช้สำหรับการสร้างข้อมูลสังเคราะห์ได้ไว้ด้านล่างนี้
Generative Adversarial Network
แบบจำลอง Generative Adversarial Network (GAN) ใช้เครือข่ายประสาทสองเครือข่ายที่ทำงานร่วมกันเพื่อสร้างและจำแนกข้อมูลใหม่ เครือข่ายหนึ่งจะใช้ข้อมูลดิบเพื่อผลิตข้อมูลสังเคราะห์ ในขณะที่เครือข่ายที่สองจะทำหน้าที่ประเมิน จำแนกลักษณะ และจำแนกข้อมูลดังกล่าว เครือข่ายทั้งสองจะแข่งขันกันไปมาจนกว่าเครือข่ายการประเมินจะไม่สามารถแยกความแตกต่างระหว่างข้อมูลสังเคราะห์กับข้อมูลต้นฉบับได้อีกต่อไป
คุณสามารถใช้ GAN เพื่อสร้างข้อมูลที่สร้างขึ้นโดยวิธีสังเคราะห์ซึ่งมีความเป็นธรรมชาติสูง และนำเสนอข้อมูลในโลกแห่งความเป็นจริงรูปแบบต่างๆ ได้อย่างละเอียด เช่น วิดีโอและรูปภาพที่ดูสมจริง
อ่านเกี่ยวกับเครือข่ายปฏิเสธภาพเชิงสร้างสรรค์ (GAN)”
Variational auto-encoders
Variational auto-encoders (VAE) เป็นอัลกอริทึมที่สร้างข้อมูลใหม่ตามการแสดงข้อมูลดั้งเดิม อัลกอริธึมที่ไม่ได้รับการกำกับดูแลนี้จะเรียนรู้การกระจายข้อมูลดิบ จากนั้นก็ใช้สถาปัตยกรรมตัวเข้ารหัส-ตัวถอดรหัส เพื่อสร้างข้อมูลใหม่ผ่านการแปลงสองครั้ง ตัวเข้ารหัสจะบีบอัดข้อมูลอินพุตให้เป็นตัวแทนที่มีขนาดน้อยกว่าและตัวถอดรหัสจะสร้างข้อมูลใหม่ขึ้นมาใหม่จากการตัวแทนแฝงนี้ โมเดลนี้จะใช้การคำนวณความน่าจะเป็นเพื่อการสร้างข้อมูลใหม่อย่างราบรื่น
VAE มีประโยชน์มากที่สุดเมื่อสร้างข้อมูลสังเคราะห์ที่คล้ายกันมากให้มีหลากหลายรูปแบบ ตัวอย่างเช่น คุณสามารถใช้ VAE เมื่อสร้างภาพใหม่ๆ ได้
โมเดลที่ใช้ Transformer
หม้อแปลงที่ผ่านการฝึกอบรมล่วง หน้าแบบสร้างหรือแบบจำลองที่ใช้ GPT ใช้ชุดข้อมูลต้นฉบับขนาดใหญ่เพื่อทำความเข้าใจโครงสร้างและการกระจายข้อมูลโดยทั่วไป ส่วนใหญ่แล้ว คุณจะใช้โมเดลนี้ในการสร้างการประมวลผลภาษาธรรมชาติ (NLP) ตัวอย่างเช่น โมเดลข้อความที่ใช้ Transformer ได้รับการฝึกด้วยชุดข้อมูลขนาดใหญ่ของข้อความภาษาอังกฤษ โมเดลจะเรียนรู้โครงสร้าง ไวยากรณ์ และแม้แต่ความแตกต่างของภาษาดังกล่าว เมื่อสร้างข้อมูลสังเคราะห์ โมเดลจะเริ่มต้นด้วยข้อความ Seed (หรือพรอมต์) และคาดการณ์คำถัดไปตามความน่าจะเป็นที่ได้เรียนรู้มาเพื่อสร้างลำดับที่สมบูรณ์
ความท้าทายในการสร้างข้อมูลสังเคราะห์คืออะไร
การสร้างข้อมูลสังเคราะห์นั้นมีความท้าทายหลายประการ ด้านล่างนี้เป็นข้อจำกัดทั่วไปและความท้าทายที่คุณอาจพบในการสร้างข้อมูลสังเคราะห์
การควบคุมคุณภาพ
คุณภาพของข้อมูลมีความสำคัญในด้านสถิติและการวิเคราะห์ ก่อนที่คุณจะรวมข้อมูลสังเคราะห์เข้ากับโมเดลการเรียนรู้ คุณต้องตรวจสอบว่าข้อมูลนั้นถูกต้องและมีคุณภาพของข้อมูลขั้นต่ำ อย่างไรก็ตาม การทำให้แน่ใจว่าจะไม่มีใครสามารถติดตามจุดข้อมูลสังเคราะห์กลับไปยังข้อมูลจริงได้ อาจทำให้ต้องลดความแม่นยำลง การที่ต้องลดความแม่นยำเพื่อรักษาความเป็นส่วนตัวนี้อาจมีผลกับคุณภาพ
คุณสามารถทำการตรวจสอบข้อมูลสังเคราะห์ด้วยตนเองก่อนการใช้งาน ซึ่งสามารถช่วยแก้ไขปัญหานี้ได้ อย่างไรก็ตามการตรวจสอบด้วยตนเองอาจใช้เวลานานในกรณีที่คุณต้องการสร้างข้อมูลสังเคราะห์จำนวนมาก
ความท้าทายทางเทคนิค
การสร้างข้อมูลสังเคราะห์เป็นเรื่องยาก คุณต้องเข้าใจเทคนิค กฎ และวิธีการในปัจจุบันเพื่อให้มั่นใจถึงความถูกต้องและประโยชน์ใช้สอย คุณต้องมีความเชี่ยวชาญระดับสูงในสาขานี้ก่อนที่จะสร้างข้อมูลสังเคราะห์ที่มีประโยชน์ขึ้นมาได้
ไม่ว่าคุณจะมีความเชี่ยวชาญมากแค่ไหน การสร้างข้อมูลสังเคราะห์ที่เป็นการเลียนแบบโลกแห่งความเป็นจริงให้สมบูรณ์แบบก็เป็นเรื่องท้าทาย ตัวอย่างเช่น ข้อมูลในโลกแห่งความเป็นจริงมักจะมีค่าผิดปกติและความผิดปกติที่อัลกอริธึมการสร้างข้อมูลสังเคราะห์แทบไม่สามารถสร้างขึ้นมาใหม่ได้
ความสับสนของผู้มีส่วนได้เสีย
แม้ว่าข้อมูลสังเคราะห์จะเป็นเครื่องมือเสริมที่มีประโยชน์ แต่ใช่ว่าผู้มีส่วนได้ส่วนเสียทุกคนจะเข้าใจความสำคัญของข้อมูลนี้ เนื่องจากนี่เป็นเทคโนโลยีล่าสุด ผู้ใช้ที่เป็นธุรกิจบางรายอาจไม่ยอมรับการวิเคราะห์ข้อมูลสังเคราะห์ว่ามีความเกี่ยวข้องกับโลกแห่งความเป็นจริง ในทางกลับกัน ผู้ใช้รายอื่นๆ อาจเน้นผลลัพธ์มากเกินไปเนื่องจากสามารถควบคุมการสร้างสรรค์ได้ ให้สื่อสารเรื่องขีดจำกัดของเทคโนโลยีนี้และผลลัพธ์ให้กับผู้มีส่วนได้ส่วนได้เสีย เพื่อให้แน่ใจว่าพวกเขาจะเข้าใจทั้งประโยชน์และข้อบกพร่องต่างๆ
AWS จะสนับสนุนความพยายามในการสร้างข้อมูลสังเคราะห์ของคุณได้อย่างไร
Amazon SageMaker เป็นบริการที่มีการจัดการอย่างเต็มรูปแบบที่ใช้ในการเตรียมข้อมูลและสร้าง ฝึกอบรม และปรับใช้โมเดลการเรียนรู้ของเครื่อง (ML) โมเดลเหล่านี้เหมาะสมสำหรับทุกกรณีการใช้งานที่มีโครงสร้างพื้นฐาน เครื่องมือ และเวิร์กโฟลว์ที่มีการจัดการเต็มรูปแบบ SageMaker มีสองตัวเลือกที่ช่วยให้คุณสามารถระบุประเภทข้อมูลดิบได้ เช่น รูปภาพ ไฟล์ข้อความ และวิดีโอ รวมถึงสร้างข้อมูลสังเคราะห์ที่ได้รับการระบุประเภทแล้วเพื่อสร้างชุดข้อมูลคุณภาพสูงสำหรับการฝึกโมเดล ML
-
Amazon SageMaker Ground Tru th เป็นข้อเสนอบริการตนเองที่ทำให้การติดฉลากข้อมูลได้ง่าย ทำให้คุณมีตัวเลือกในการใช้คำอธิบายประกอบของมนุษย์ผ่าน Amazon Mechanical Turk, ผู้ให้บริการจากภายนอก หรือทีมงานส่วนตัวของคุณเอง
-
Amazon SageMaker Ground Truth Plus เป็นบริการที่มีการจัดการเต็มรูปแบบ ซึ่งช่วยให้คุณสามารถสร้างชุดข้อมูลการฝึกที่มีคุณภาพสูงได้ คุณไม่จำเป็นต้องสร้างแอปพลิเคชันการระบุประเภทข้อมูลหรือจัดการแรงงานเพื่อการระบุข้อมูลด้วยตัวคุณเอง
ขั้นแรก คุณระบุข้อกำหนดของภาพสังเคราะห์หรือมอบแอสเซท 3 มิติและภาพพื้นฐานมาให้ เช่น ภาพการออกแบบโดยใช้คอมพิวเตอร์ช่วย (CAD) จากนั้นศิลปินดิจิทัล AWS จะสร้างภาพใหม่ขึ้นมาจากศูนย์หรือใช้แอสเซทที่ลูกค้าให้ไว้ ภาพที่สร้างขึ้นจะเลียนแบบท่าทางและตำแหน่งของวัตถุ รวมถึงความหลากหลายของวัตถุหรือฉาก และรวมรายละเอียดที่เฉพาะเจาะจงเข้าไป เช่น รอยขีดข่วน รอยบุบ และการปรับเปลี่ยนอื่นๆ วิธีนี้จะช่วยลดกระบวนการรวบรวมข้อมูลที่ใช้เวลานานหรือความจำเป็นในการสร้างความเสียหายให้กับส่วนต่างๆ เพื่อสร้างภาพขึ้นมา คุณสามารถสร้างภาพสังเคราะห์นับแสนภาพที่ผ่านการระบุประเภทแล้วโดยอัตโนมัติด้วยความแม่นยำสูง
เริ่มต้นด้วยการสร้างข้อมูลสังเคราะห์บน AWS โดย การสร้างบัญชีฟรี วันนี้
Browse all cloud computing concepts
Browse all cloud computing concepts content here:
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages