亚马逊AWS官方博客
对症下药 – Redshift 调优方法漫谈
Amazon Redshift 是为OLAP场景云原生设计的企业级数据仓库,许多行业领先的第三方工具(BI商业智能、报表及可视化数据分析工具)都已经与Amazon Redshift 深度集成,可以对Amazon Redshift的数据进行加载、转换和可视化展现。Amazon Redshift 通过大规模并行处理(MPP)、列式数据存储和高效且具有针对性的数据压缩等特性的组合,实现了高效存储和优异的查询性能,因此一经推出就受到广大用户的好评。
此前的博客《善始方能善终- Amazon Redshift表设计探秘》介绍了Amazon Redshift中表设计的最佳实践,并通过实验让读者对不同表设计给相同查询带来的性能差异有一个直观的认识。然而所谓流水不腐户枢不蠹,任何一款数据库即使有完善的初始设计,随着数据量的增长变化,依然需要DBA的精心维护调优,才能保证数据库以最佳状态为客户提供服务。Amazon Redshift也是如此,本文将着重向读者介绍如何定位性能问题以及性能调优的最佳实践。 阅读本文需要一定的基础数据库知识。
一、 查询计划和执行工作流程
首先,我们先来了解一下Amazon Redshift中查询计划和执行工作的流程:

1.Amazon Redshift 集群由节点组成。每个集群包括一个领导节点以及一个或多个计算节点。领导节点接收查询并解析 SQL。
2.分析程序生成初步查询树,查询树是原始查询的逻辑表示。然后,Amazon Redshift 将该查询树输入到查询优化程序中。
3.优化程序评估查询并根据需要重写查询,以最大限度地提高其效率。该过程有时会创建多个相关查询来代替单个查询。
4.优化程序生成一个或多个查询计划(如果上一步生成了多个查询),以实现最佳性能。查询计划指定执行选项,如联接类型、联接顺序、聚合选项和数据分配要求。
5.执行引擎将查询计划转换成步骤、段 和流:段是并行完成的,段内的步骤是串行执行的
- 步骤(step)每个步骤都是查询执行期间需要的单独操作。步骤可以组合,使计算节点能够执行查询、联接或其他数据库操作。
- 段(segment)是多个步骤的组合,可由单个进程完成,它也是计算节点切片可执行的最小编译单元。切片是 Amazon Redshift 中并行处理的单元。流中的段并行运行。
- 流(stream)将在可用计算节点切片上分配的段的集合。
6.计算节点切片并行执行查询段。在该流程中,Amazon Redshift 利用优化的网络通信、内存和磁盘管理,将中间结果从一个查询计划步骤传递到下一个,这也有助于加快查询的执行。计算节点完成后,它们将查询结果返回到领导节点进行最终处理。领导节点将数据合并为一个结果集,并在必要时执行排序或聚合操作。之后,领导节点将结果返回给客户端。查询执行期间,计算节点可能会根据需要将某些数据返回给领导节点。例如,如果您有一个包含 LIMIT 子句的子查询,则在数据在集群间重新分配以进一步处理前会在领导节点上应用该限制。
二、执行计划解析
接下来我们来了解一下如何分析执行计划,在调优的过程中我们必然会借助查询计划获取有关查询各个操作的信息。使用explain命令可以查看执行计划,但请注意explain命令并不实际运行查询。它只显示查询在当前操作条件下运行时 Amazon Redshift 将执行的计划。如果您更改表的定义 或表内数据后,且再次运行 ANALYZE 以更新了统计元数据,则新的查询计划可能会与原来explain的结果不同。
2.1 基本指标
我们先用一个简单的查询来了解执行计划的一些基本指标,针对event表的eventname列进行分组,然后计算不同eventname的行数。计划中红色的部分是重点信息,后续部分的计划也以这种方法进行了标注。
- 成本是一个相对值,要比较计划中的操作,它很有用。成本由两个圆点分隔的两个数值组成,例如 cost=131.97..133.41。第一个值(本例中的97)提供返回该操作第一行的相对成本。第二个值(本例中的 133.41)提供完成操作的相对成本。查询计划中的成本是由下而上累积的,因此,本示例中的 HashAggregate 成本 (131.97..133.41) 包含其下方的 Seq Scan 的成本 (0.00..87.98)。
- 行数,预计返回的行数。在本示例中,预计扫描将返回 8798 行。预计 HashAggregate 运算符自身将返回 576 行(从结果集中针对eventname执行了聚合运算后)行数估算基于 ANALYZE 命令生成的可用统计数据。如果最近未运行过 ANALYZE,则估算的可靠性会降低。
- 宽度,平均行的预计宽度(以字节为单位)。在本示例中,平均行宽预计为 17 个字节宽。
- 顺序扫描运算符 (Seq Scan) 表示从头到尾按顺序扫描表中的每列,并评估每行是否符合查询条件(在 WHERE 子句中)。
2.2 聚合与排序运算符
聚合运算符
查询计划在涉及聚合函数和 GROUP BY 操作的查询中使用以下运算符。
- 聚合函数的运算符,如 AVG 和 SUM。
- HashAggregate 对未排序的数据执行分组聚合函数的运算符。
- GroupAggregate 对已排序的数据执行分组聚合函数的运算符。
排序运算符
当查询必须排序或合并结果集时,查询计划使用以下运算符。
- sort 评估 ORDER BY 子句及其他排序操作,如 UNION 查询和联接、SELECT DISTINCT 查询及窗口函数需要的排序。
- merge 根据从并行操作得到的中间排序结果生成最终排序结果。
了解聚合和排序运算符后,我们用学到的知识分析1个简单的语句,加深一下理解:
示例:联接、聚合和排序
- 上述语句将sales和event表根据eventid列进行联接,按照eventname分组,计算不同eventname的pricepaid总和,再以pricepaid总和值对结果集进行排序。
- 查询首先执行SALES 和 EVENT 表的哈希联接,而后完成聚合和排序操作,以便为执行 SUM 函数及 ORDER BY 子句做好准备。
- 初始 Sort 运算符在计算节点上并行运行。然后,Network 运算符将结果发送到领导节点,在领导节点上,Merge 运算符产生最终排序结果。
2.3 联接运算符
Amazon Redshift 会根据要联接的表的物理设计、联接所需的数据的位置以及查询本身的特定要求来选择联接运算符。
- 嵌套循环(Nested Loop)嵌套循环是优化程度最差的联接,主要用于交叉联接(笛卡尔积)和一些不等式联接。
- 哈希联接和哈希(Hash Join and Hash)哈希联接和哈希通常比嵌套循环联接快,用于内部联接和左/右外部联接。当表的联接列不全是分配键和排序键时使用hash join来联接。哈希运算符首先为联接运算的内部表创建哈希表;而后读取外部表,对联接列进行哈希处理,然后在内部哈希表查找匹配项。
- 合并联接(Merge Join)合并联接通常是最快的联接,用于内部联接和外部联接。合并联接不能用于完全联接。所谓完全联接是指完整外部联接返回左表和右表中的所有行。当某行在另一个表中没有匹配行时,则另一个表的选择列表列包含空值。当联接使用的联接列同时为涉及表的分配键和排序键时,且当 20% 以下的联接表未排序时,将使用此运算符。它按顺序读取两个已排序表并查找匹配的行。要查看未排序行的百分比,请查询SVV_TABLE_INFO系统表。
了解联接运算符后,我们同样用学到的知识分析2个简单的语句,加深一下理解:
示例:对两个表进行哈希联接
- 在 CATID 列上联接 EVENT 和 CATEGORY。CATID 是 CATEGORY(但不是 EVENT)的分配键和排序键。哈希联接以 EVENT 作为外部表、CATEGORY 作为内部表执行。因为 CATEGORY 是较小的表,所以,计划程序在查询期间使用 DS_BCAST_INNER 将其副本广播到计算节点。在本示例中,联接成本占计划累积成本中的绝大部分。
- EXPLAIN 输出中运算符的缩进对齐有时表示这些操作不互相依赖,可以并行执行。但在前面的示例中,尽管对 EVENT 表的扫描和哈希操作是对齐的,但 EVENT 扫描必须等待哈希操作彻底完成。
示例:对两个表进行合并联接
- 查询还使用 SELECT *,但它在 LISTID 列上联接 SALES 和 LISTING,其中,LISTID 已设置为两个表的分配键及排序键。
- 选择了合并联接,该联接不要求重新分配数据 (DS_DIST_NONE)。
2.4 数据重新分配
联接还可能会指定在集群上移动数据以便进行联接的方法。数据移动可以采用广播方法或重新分配。在广播方法中,联接一侧的数据值从每个计算节点复制到所有其他计算节点,最终使每个计算节点都拥有该数据的完整副本。在重新分配中,参与数据值从其当前切片发送到新的切片(可能在不同的节点上)。如果分配键是联接列之一,则数据通常会重新分配,以匹配参与联接的其他表的分配键。如果两个表都没有基于任一联接列的分配键,则两个表都分配到每个节点,或内部表广播到每个节点。
EXPLAIN 输出还引用内部表和外部表。内部表首先扫描并显示在查询计划中更靠近底部的位置。内部表是用于探测匹配的表。它通常保留在内存中,一般是用于执行哈希操作的源表,只要可能,会是要联接的两个表中较小的一个。外部表是用于匹配内部表的行的源表。它通常从磁盘读取。查询优化程序根据最近一次运行 ANALYZE 命令得到的数据库统计数据选择内部表和外部表。查询的 FROM 子句中的表顺序并不区分内部表和外部表。
您可以通过查询计划中的以下属性了解数据的移动方式(以便执行查询):
- DS_BCAST_INNER
将整个内部表的副本广播到所有计算节点。
- DS_DIST_ALL_NONE
无需重新分配,因为内部表已使用 DISTSTYLE ALL 分配到所有节点。
- DS_DIST_NONE
无需重新分配表。可以进行并置联接,因为相应切片的联接无需在节点间移动数据。
- DS_DIST_INNER
内部表重新分配。
- DS_DIST_OUTER
外部表重新分配。
- DS_DIST_ALL_INNER
整个内部表重新分配到单个切片,因为外部表使用 DISTSTYLE ALL。
- DS_DIST_BOTH
两个表都重新分配。
三、调优思路
3.1 系统表和视图
接下来我们要了解一下Amazon Redshift的系统表和视图,我们需要查询系统表和视图来了解系统的运行情况和语句性能。
- 系统表分两种类型:STL 表和 STV 表。STL 表从长久保存到磁盘的用于提供系统历史记录的日志生成。STV 表为包含当前系统数据快照的虚拟表。它们基于临时的内存数据,不会长久保存到基于磁盘的日志或常规表中。
- 只包含对 STL 表的引用的视图称为 SVL 视图。包含对任意临时的 STV 表引用的系统视图称为 SVV 视图。
- 系统表及视图不使用与常规表相同的一致性模型。在查询它们时,特别是查询 STV 表和 SVV 视图时,一定要注意这个问题。下面针对系统表的查询可能返回行:select * from stv_exec_state where currenttime > (select max(currenttime) from stv_exec_state)该查询可能返回行的原因在于:currenttime 是临时的,查询中的两个引用在求值时可能返回不同的值。
- 自动或手动集群备份(快照)中不包含系统表。STL 日志表仅保留大约 2 到 5 天的日志历史记录,具体取决于日志使用情况和可用磁盘空间。如果需要保留日志数据,则需要定期将数据复制到其他表或将数据卸载到 Amazon S3。
3.2 了解数据占用空间
磁盘使用情况监控
当我们要了解整个集群磁盘使用情况时,我们可以通过客户端登录集群后(这里对登录方法不做赘述)使用以下SQL语句进行查询,查询返回已用磁盘空间和容量(1 MB 磁盘块的数目),并计算磁盘利用率(占原始磁盘空间的百分比)。原始磁盘空间包括 Amazon Redshift 保留供内部使用的空间,因此它大于名义磁盘容量(可供用户使用的磁盘空间量)。

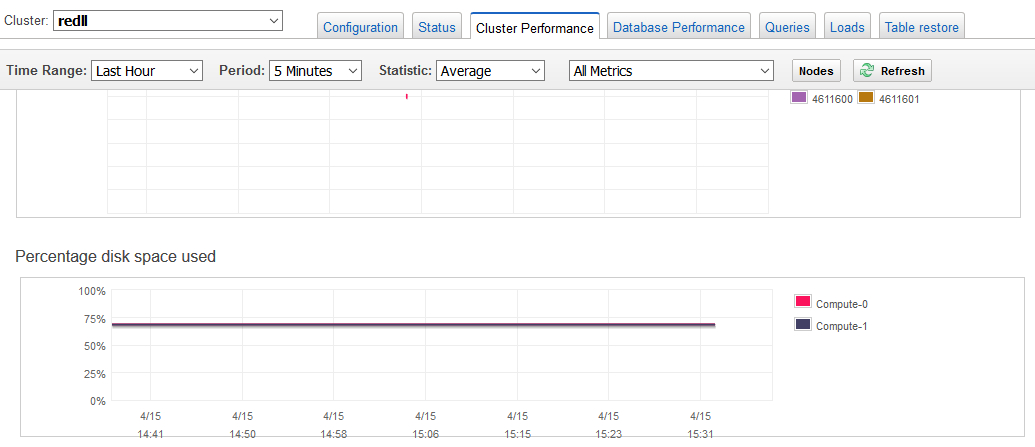
查询显示在两个节点组成的集群上(每个节点有2个逻辑盘分区),各磁盘空间的利用率,我们可以看到利用率较为平均大概在59%左右。虽然原始磁盘容量大于名义磁盘容量,但是强烈建议您不超过集群的名义磁盘容量。尽管这在技术上可能可行,但在某些情况下,超过名义磁盘容量会降低集群的容错能力并增加丢失数据的风险。
除此以外,我们也可以在Amazon Redshift 管理控制台的 Performance 选项卡上找到 Percentage of Disk Space Used 指标报告,了解集群所使用的名义磁盘容量百分比。建议您监控 Percentage of Disk Space Used 指标并通过释放空间或增大集群来维持集群的名义磁盘容量的可使用量。
单表磁盘使用情况监控
当我们要了解具体某个表占用的空间大小时,可以通过客户端登录集群后使用以下SQL语句进行查询,size列值显示了每个表占用的表空间,单位是MB。

需要提醒大家注意的是,和我们通常的认知有所不同,同一张表使用ALL数据分配所占用的空间并不一定大于使用EVEN或KEY数据分配所占用的空间,因为每个表占用的磁盘存储空间差异是由以下因素决定的:
- 每个 Amazon Redshift 集群上填充的切片数量
- 每个表使用的段的数量
- 如果 Amazon Redshift 表具有排序键,则该表中会有两个段:一个已排序的段和一个未排序的段。如果 Amazon Redshift 表中没有排序键,则所有数据都未经过排序,因此该表有一个未排序的段。
- 对于使用 KEY 或 EVEN 分配方式创建的表:
最小表大小 = 数据块大小 (1MB) *(用户列数 + 3 个系统列)* 填充切片数 * 段数。 - 对于使用 ALL 分配方式创建的表:
最小表大小 = 数据块大小 (1MB) *(用户列数 + 3 个系统列)* 集群节点数 * 段数。
我们查询结果中的countries表有10个用户列,有排序键,集群有2个dc1.large节点,每个节点2个切片,所以我们可以计算不同数据分配下该表的初始大小为:
- All分配:1MB * (10 + 3) * 2 * 2 = 52MB /*因为一共有2个节点,2个段*/
- KEY或EVEN分配:1MB * (10 + 3) * 4 * 2 = 104MB /*因为一共有4个切片,2个段*/
所以,当表较小时,因为ALL分配每个节点只保存一份数据,也就说只在一个切片上初始化数据,而EVEN/KEY分配需要在每个切片上初始化数据,所以如果节点加大,相应的切片数增加,会使得一张表采取EVEN/KEY分配后初始化的最小大小远远大于同一张表采取ALL分配初始化后的最小大小。如果您的应用会用到大量的小表,请务必考虑这一点。
3.3 了解并发查询和连接
概念
Amazon Redshift 主要用于大数据分析场景,它处理的典型查询更多是少量并发但单个运行时间较长的复杂查询。Amazon Redshift限制每个集群和每个数据库用户的连接数量。当达到此限制时,后续连接尝试失败,出现错误“非引导用户超出连接限制 500”。我们可以将 STV_SESSIONS 表与 STL_CONNECTION_LOG 表合并,以查看与连接关联的 IP 地址。例如,以下查询会检查不同远程 IP 地址的连接计数:
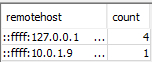
此外我们可以通过 AWS 管理控制台打开 Amazon Redshift 控制台,选择cluster后点击cluster performance选项卡后即可获取当前查询和连接信息。


如果并发连接较多,就要考虑实施工作负载管理了,譬如多个会话或多名用户同时运行查询时,某些查询可能会长时间占用集群资源,从而影响其他查询的性能。例如,假设一组用户时不时提交复杂、耗时的查询(从多个大型表中选择和排序行)。另一组用户经常提交短查询(仅从一个或两个表中选择少量行,运行时长只有数秒)。这种情况下,短时查询可能不得不在队列中等待耗时查询完成。
您可以修改 WLM 配置,为耗时查询和短时查询分别创建队列,以提升系统性能和用户体验。在运行时,您可以根据用户组或查询组将查询路由到这些队列。默认情况下,Amazon Redshift 配置以下查询队列:
- 一个超级用户队列。超级用户队列是专为超级用户预留的队列,无法进行配置。仅当您需要运行影响系统的查询或用于故障排除目的时,才应使用该队列。例如,如果需要取消用户的耗时查询或向数据库添加用户,则可使用该队列。不应使用它来执行常规查询。该队列不显示在控制台中,但在数据库的系统表中显示为第五队列。要在超级用户队列中运行查询,用户必须以超级用户身份登录并使用预定义的superuser 查询组运行查询。
- 一个默认用户队列。默认队列初始配置为并发运行五个查询。您可以更改默认队列的并发、超时和内存分配属性,但不能指定用户组或查询组。默认队列必须是 WLM 配置中最后一个队列。未能匹配条件路由到其他队列的查询将在默认队列中运行。
您可以向默认 WLM 配置添加其他查询队列,最多可添加八个用户队列,并设置可在每个队列中同时运行的查询数。您可以设置规则以根据运行查询的用户或指定的标签将查询路由到特定的队列。您还可以配置分配到每个队列的内存量,使大型查询在内存更多的队列中运行。您也可以配置 WLM 超时属性以限制耗时查询。您可以为每个查询队列配置以下内容:
- 并发级别,队列中的查询以并发方式运行,直到它们达到为该队列定义的WLM 队列插槽计数或并发级别。达到并发级别后,后续查询将在队列中等待。
- 用户组,您可以通过指定每个用户组的名称或使用通配符将一组用户组分配给某个队列。当所列用户组的成员运行某个查询时,该查询将在相应的队列中运行。您可以向队列分配任意数量的用户组。
- 查询组,您可以通过指定每个队列组的名称或使用通配符将一组查询组分配给某个队列。查询组只是一种标签。在运行时,您可以将查询组标签分配给一系列查询。分配给所列查询组的任意查询都将在相应的队列中运行。您可以向队列分配任意数量的查询组。
- 要使用的 WLM 内存百分比,要指定分配给查询的可用内存量,您可以设置WLM Memory Percent to Use 参数。默认情况下,会向每个用户定义队列分配相等的用户定义查询可用内存。例如,如果有四个用户定义队列,则会向每个队列分配 25% 的可用内存。超级用户队列有自己的分配内存,无法进行修改。要更改分配,您可以向每个队列分配整数比例的内存,总计最高为 100%。例如,如果配置了四个队列,则可以按以下方式分配内存:20%、30%、15%、15%。其余的 20% 未分配,由Amazon Redshift管理。
- WLM 超时,要限制允许查询在给定 WLM 队列中停留的时间,您可以为每个队列设置 WLM 超时值。超时参数指定 Amazon Redshift 在取消或跳过查询前等待查询执行的时间量 (单位为毫秒)。超时基于查询执行时间,不包括在队列中等待的时间。
- WLM 查询队列跳跃,WLM 尝试跳过CREATE TABLE AS (CTAS) 语句和只读查询,例如 SELECT 语句。无法跳过的查询将被取消。
- 查询监控规则,查询监控规则为 WLM 查询定义基于指标的性能界限,并指定在查询超出这些界限时需要采取的操作。例如,对于短时间运行查询专用的队列,您可创建中止运行超过 60 秒的查询的规则。要跟踪设计不佳的查询,您可创建记录包含嵌套循环的查询的其他规则。
当用户运行查询时,WLM 基于这些规则将查询分配给第一个匹配的队列。
- 如果用户以超级用户身份登录并在带有超级用户标签的查询组中运行某个查询,则该查询会分配到超级用户队列。
- 如果用户属于所列用户组或用户的查询可以匹配到查询组,则该查询会分配给第一个匹配队列。
- 如果某个查询不满足任何条件,则该查询会分配给默认队列,即 WLM 配置中定义的最后一个队列。
监控
关于查询队列的详细配置信息请参阅《 Amazon Redshift 数据库开发人员指南》,在此不做赘述,我们主要介绍在更改 WLM 配置后如何 监控队列情况,首先创建WLM_QUEUE_STATE_VW 视图
视图中各列含义如下:
| 列 | 描述 |
| queue | 与表示一个队列的行关联的编号。队列编号确定了队列在数据库中的顺序。 |
| description | 一个值,用于描述队列是仅适用于某些用户组、某些查询组还是所有类型的查询。 |
| slots | 分配给队列的槽位数量。 |
| mem | 分配给队列的内存量(以每个槽的 MB 数为单位)。 |
| max_execution_time | 在查询终止之前允许其运行的时间量。 |
| user_* | 一个值,用于指示是否允许在 WLM 配置中使用通配符来匹配用户组。 |
| query_* | 一个值,用于指示是否允许在 WLM 配置中使用通配符来匹配查询组。 |
| queued | 正在队列中等待进行处理的查询的数量。 |
| executing | 目前正在执行的查询的数量。 |
| executed | 已执行的查询的数量。 |
查看视图:

从结果中我们可以看到:
- 当前Amazon Redshift配置了三个queue。
- 队列没有在 WLM 配置中使用用户或者查询的通配符来匹配查询组。
- 当前所有队列中都没有等待进行处理的查询,其中1号队列中有一个查询在执行。
在日常运维中,我们时常关注是队列中等待处理的查询数量是否在可接受的范围内,如果您发现有大量的并发短促查询(运行时间较短的查询)因为等待长时间执行的复杂查询而排队,Amazon Redshift还提供了短查询加速 (SQA)功能,Amazon Redshift 使用机器学习算法分析每个CREATE TABLE AS (CTAS) 语句和只读查询,并预测查询的执行时间。默认情况下,WLM 会在分析集群的工作负载后给SQA 最大运行时间动态分配一个值。或者,您也可以指定一个介于 1 和 20 秒之间的固定值。假设有查询的预测运行时小于定义的 SQA 最大运行时间,而且查询需要在队列中等待时, SQA 将查询与 WLM 队列分开,并将其排定为优先执行。如果查询运行的时间长于 SQA 最大运行时间,WLM 依然会根据 WLM 队列分配规则将查询移动到第一个匹配 WLM 队列。随着时间的推移,预测准确度会随着 SQA 从您的查询模式中学习而提高。
默认情况下,为默认参数组和所有新参数组启用 SQA。要在 Amazon Redshift 控制台中禁用 SQA,请编辑参数组的 WLM 配置并选择取消Enable short query acceleration (启用短查询加速)。
您可以用以下查询显示遍历每个查询队列 (服务类) 的查询数量。它还显示平均执行时间、等待时间排在第九十百分位数的查询数量以及平均等待时间。SQA 查询使用服务类 14。
3.4 了解表维护信息
统计信息收集
优化器生成执行计划的基础是统计信息,如果统计信息不正确,那么生成的执行计划也很容易不可靠。下面的查询提供对缺失统计数据的表运行的查询的计数。如果该查询返回任意行,则查看 plannode值以确定受影响的表,然后对其运行 ANALYZE命令收集统计信息。

重新排序
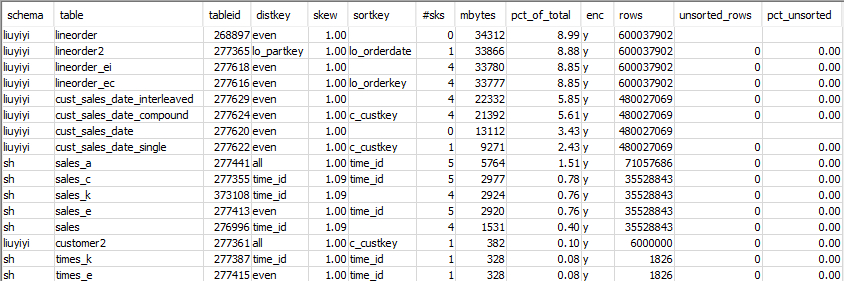
在此前的博客《善始方能善终-Amazon Redshift表设计探秘》中,我们反复强调了数据分配和排序的意义,正确的数据分配和排序可以大大减少不必要的IO,从而提升性能。下面的查询可找到具有不均匀数据分配(数据偏斜)或未排序行占比较高的表。skew 值较低表明表数据分配适当。如果表的 skew 值达到 4.00 或以上,可以考虑修改其数据分配方式。如果表的 pct_unsorted 值大于 20%,可以考虑运行 VACUUM 命令。
3.5调优问题语句
定位问题语句
接下来,我们要进入重头戏,调优问题语句。当您的查询在Amazon Redshift上性能不理想时,我们首先要先定位问题SQL,以便有的放矢地进行调优。这需要借助以下几个查询:
通过以下查询可找出过去 7 天执行的前 50 条最耗时的语句。您可以利用这些结果发现特别耗时的查询以及经常运行的查询(在结果集中多次出现的查询)。通常优化此类查询后可以提高系统性能。

上图的结果显示了redll这个数据库中,最近七天最耗时的语句,我们可以通过n_qry看到每个语句的执行次数,通过qrytext看到语句的内容,通过max_query_id获取这个语句最近一次执行的query id。
调优语句
找到问题语句之后,我们就可以对它们进行调优,首先,我们可以借助一些视图,进一步收集信息,协助定位问题,并获取可能的解决问题的建议。
STL_ALERT_EVENT_LOG
当查询优化程序发现可能指示性能问题的条件时记录警报。使用 STL_ALERT_EVENT_LOG 表标识用于改进查询性能的机会。STL_ALERT_EVENT_LOG 对所有用户可见。超级用户可以查看所有行;普通用户只能看到自己的数据。

- 如果我们已经确认了query id,那么可以直接通过query字段筛选信息,如果不知道query id,我们可以检查substring 字段中的截断查询文本,以确定要选择的 query 值。
- 请注意,并非所有查询都在 STL_ALERT_EVENT_LOG 中拥有行(仅限存在已发现的问题的查询)。
- event字段描述了警报事件。
- solution字段给出了建议的解决方案。
SVL_QUERY_REPORT
Amazon Redshift 通过对一系列 Amazon Redshift STL 系统表执行 UNION 来创建 SVL_QUERY_REPORT 视图,以提供有关所执行的查询步骤的信息。此视图按切片和按步骤细分所执行的查询的相关信息,这有助于诊断 Amazon Redshift 集群中的节点和切片问题。SVL_QUERY_REPORT 对所有用户可见。超级用户可以查看所有行;普通用户只能看到自己的数据。我们可以通过以下查询对问题语句的执行情况以及问题原因进一步探查。

从查询结果中,我们可以获取以下信息
- 对于每个步骤,检查所有切片是否处理大致相同的行数,对于每个步骤,检查所有切片是否花费大致相同的时间。如果这些值存在较大差异,则可能表明存在数据分配偏斜(因为向该特定查询应用了非最优分配方式),要解决问题考虑遵循最佳实践修改数据分配方式。
- 查看任意步骤的is_diskbased 字段的值是否为 t (true)。通过扫描 IS_DISKBASED 的值,您能够了解哪些查询步骤溢出到磁盘。如果系统没有充足的内存分配给查询处理作业时,哈希、聚合和排序操作是可能向磁盘写入数据的。要修复这一问题,请临时增加查询使用的查询槽的数目,以向其分配更多的内存。工作负载管理 (WLM) 在查询队列中预留与为查询设置的并发级别相等的槽数。例如,并发级别为 5 的队列拥有 5 个槽。分配给队列的内存平均分配到每个槽。将多个槽分配给一个查询可使该查询访问所有这些槽的内存。
- 查看label 字段的值,确定步骤中是否存在任意 AGG-DIST-AGG 序列。如果有该序列,则表明存在代价高昂的两步聚合。要解决这一问题,请将 GROUP BY 子句更改为使用分配键(如果存在多个分配键,则是第一个键)
分析执行计划
以上视图会帮助我们了解问题SQL的详细信息,有时候甚至已经诊断出了问题并提供了解决方案,但是很多时候我们还是要分析SQL语句的执行计划,找出问题,进而进行调优。在前面第二章我们已经介绍了如何读取解析执行计划,那么接下来我们用一个例子去看一下怎么调优性能欠佳的SQL语句。
实验的数据集按星型模型设计,其中sales表是事实表, times,customers 以及products是维度表。其中sales事实表大小3G,times维度表大小0.3G,products维度表大小0.2G,customers维度表大小0.2G。所有的表都采取EVEN数据分配方式。用以下的语句为例我们来了解如何分析一条性能欠佳的SQL语句的执行计划。
其结果如下:

从执行计划中,我们需要关注以下信息:
- 我们需要关注每一个步骤的cost以及rows,如果rows与实际情况出入较大,要考虑统计信息不准确,使用4节叙述的方法重新收集统计信息或对数据重新排序。本例中的统计信息都是最新的。
- 查看联接的类型是否符合预期,尤其关注是否有嵌套循环nest loop,如果有此类联接要检查是否存在交叉联接,除非我们的查询确实需要,否则一定要避免交叉联接。因为交叉联接是无联接条件的联接,它会导致对两个表执行笛卡尔积操作,而这是最慢的可能联接类型。3节介绍了不同联接类型的应用场景和优势,这里不再赘述。本例中都是hash join。
- 关注每个步骤的数据重新分配,DS_BCAST_INNER/ DS_DIST_ALL_INNER/ DS_DIST_BOTH意味着高成本的操作,要解决这一问题,我们就需要考虑是否遵循了表设计的最佳实践,将数据进行了最优分配。本例中有大量DS_BCAST_INNER,需要特别关注,之所以如此是因为所有的表都采取EVEN数据分配方式,导致计划执行时不得不将表广播到所有计算节点,大大影响了性能。
针对以上的问题,我们需要调整数据分配,我们将事实表sales的数据以key分配并使用复合排序键,维度表times 数据也按key分配且使用与事实表联接的键列,其他维度表数据全部all分配,重新分配数据后,我们再次进行相同查询,执行计划变为:

我们分析执行计划可以清楚地看到以下几个变化:
- 我们可以看到修改了数据分配方式后,每个步骤的数据重新分配显示为DS_DIST_ALL_NONE/ DS_DIST_NONE,这意味着无需重新分配数据,大大减少了性能损耗。
- 此外,我们的事实表sales与维度表times因为基于联接键列做KEY分布,所以两个表的联接方式从原来的hash join变为了merge join,这通常是最快的联接方式。
- 我们可以看到执行计划的cost从53变为了711842.20 ,而语句首次运行时间也从1.69秒减少到了0.28秒。我们可以看到通过遵循数据分配最佳实践,消除不必要的数据重分配,改进联接方式,大大提升了SQL语句的性能。
请注意:笔者的实验环境用的是两台dc1.large组成的集群,硬件环境不同,数据集不同,实验结果也会有变化,但调优的方法和步骤都是想通的。
结束语
希望读者在阅读本文后,能够理顺思路,建立完善的机制去监控数据库的运行状况,发现问题,尽早消除隐患,从而始终如一地保持Amazon Redshift的活力,为我们的业务提供最优质的服务。
参考文档
《Amazon Redshift数据库开发人员指南》