亚马逊AWS官方博客
使用 Apache MXNet 对基于 CNN 的检测器的训练时间进行基准测试
作者:Iris Fu 和 Cambron Carter
这是一篇由工程总监 Cambron Carter 和 GumGum 的计算机视觉科学家 Iris Fu 联合发布的访客文章。用他们自己的话说,“GumGum 是一家在计算机视觉领域具有深厚专业知识的人工智能公司,能帮助客户充分发挥网络、社交媒体及广播电视每天生产的图像和视频的价值。”
目标物检测的最新技术
检测是许多经典计算机视觉问题之一,已随着卷积神经网络 (CNN) 的采用而得到显著改善。随着 CNN 越来越多地用于图像分类,许多人都依靠粗糙和昂贵的预处理程序来生成候选区域 (region proposal)。通过诸如“选择性搜索”之类的算法根据区域的“客体性”(它们包含目标物的可能性) 生成候选区域,这些区域随后被馈送到训练用于分类的 CNN。虽然这种方法能得到准确结果,但需要很高的运行成本。Faster R-CNN,You Only Look Once (YOLO) 和 Single Shot MultiBox Detector (SSD) 等 CNN 架构通过将定位任务嵌入到网络中来折中解决该问题。
除了预测等级和置信度,这些 CNN 还尝试预测包含某些目标物的区域极值。在本文中,这些极值只是矩形的四个角点,通常称为边界框。先前提到的检测架构需要已经用边界框注释的训练数据,即,该图像包含一个人,而且此人在该矩形区域内。以下是分类训练数据和检测训练数据:

超级帅气又非常能干的工程师
我们开始对使用 Apache MXNet 和 Caffe 来训练 SSD 的体验进行比较。明显动机是以分布式方式训练这些新架构,而不降低准确性。有关架构的更多信息,请参阅“SSD: Single Shot MultiBox Detector”。
训练工具
对于这组实验,我们尝试了几款 NVIDIA GPU:Titan X、1080、K80 和 K520。我们使用 Titan X 和 1080 在内部进行了几次实验,但也使用了基于 AWS GPU 的 EC2 实例。此帖子仅限于 g2.2x 和 p2.8x 实例类型。幸运的是,我们已经有一些使用 MXNet 的可用 SSD 实施方案,例如这个,在此次讨论的实验中我们就使用了这个实施方案。值得注意的是,为了使实验更详尽,您应该将其他常见框架 (如 TensorFlow) 的基准测试数据也包含在内。
速度:使用 MXNet 调整批处理大小和 GPU 计数的影响
首先,我们来看看使用 MXNet 的多 GPU 训练会话的性能影响。前几个实验侧重于在 EC2 实例上使用 MXNet 对 SSD 进行训练。我们使用 PASCAL VOC 2012 数据集。这第一个练习的目的是了解 GPU 计数和批处理大小对特定 GPU 速度的影响。我们使用了几种不同的 GPU 来说明它们的绝对性能差异。如果您想进一步探索,还可了解有关不同 GPU 的价格和性能的许多信息。让我们从 g2.2x 实例附带的 K520 开始:
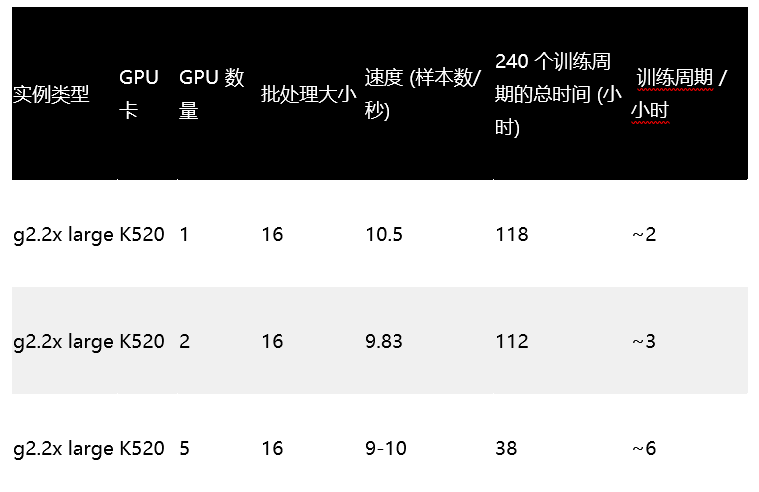
请注意,在批处理大小不变的情况下,添加额外的 g2.2x 实例 (每个实例一个 K520) 会使每台机器有大致恒定的速度。因此,每小时的训练周期数几乎呈线性增加。添加机器应该能继续缩短运行时间,但在某一点上可能会影响准确性。我们不在此处探讨这种情况,但需要提一下。
然后,我们想看看在本地 1080 上是否观察到这一趋势:
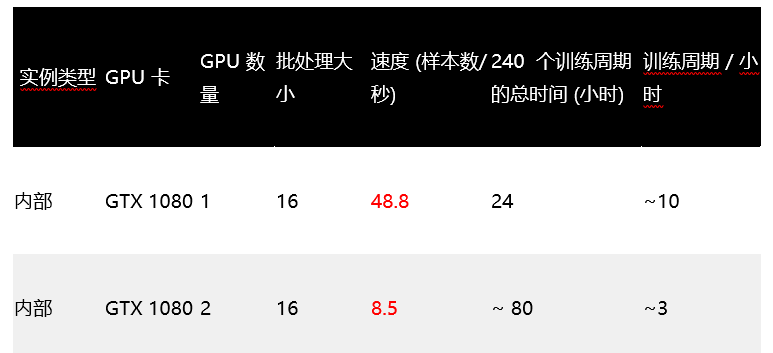
如预期的一样,一个 1080 轻松胜过五个 K520。除了发现的这个情况外,该实验也引起了一些人的质疑。我们发现在组合中再加入一个 1080 时,每个 GPU 的速度会大大降低。由于本实验中的进程间通信通过以太网进行,因此一开始我们认为自己受到了办公网络的限制。但根据 Iperf 数据,该假设并不成立:

我们的测试表明,我们办公网络中的带宽和传输量都高于两个 EC2 实例之间的这两个值。这就引出了我们的下一个问题:如果批处理大小是导致效率低下的原因怎么办?

啊哈!虽然仍比使用一个 1080 慢得多,但在增加一个 1080 (在单独的机器上) 的同时增加批处理大小可提高速度。我们来看一下训练对具有多个互连 GPU 的机器的影响:
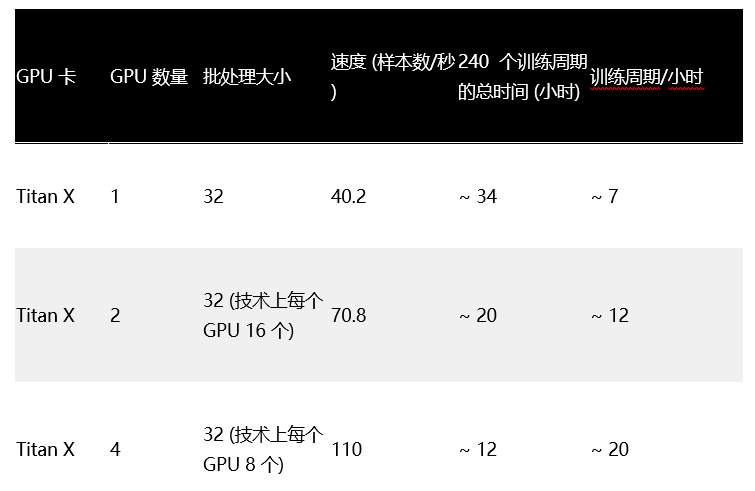
我们使用了自己的内部 NVIDIA DevBox,其中包含四个 Titan X。保持批处理大小不变,但增加 GPU 数量 (技术上减少每个 GPU 的单个批处理大小),可将速度提高大约 2.5 倍!这就引出了一个显而易见的问题:如果我们增加每个 GPU 的批处理大小会怎样?

我们观察到,当我们保持批处理大小恒定 (16),并增加同一机器上的 GPU 数量时,最终速度也会提高大约 2 倍。我们本想进一步探索,但 DevBox 风扇嗡嗡作响,让我们无法再增加批处理大小。我们 1080 实验的奇案仍然无解,作为一个悬而未决的问题而为人所知。AWS 的潜在解决方案可能是使用放置组,在本文中我们不探讨此方案。
准确性:使用 MXNet 调整批处理大小的影响
由于我们花那么精力来调整批处理大小,因此值得探讨一下调整批处理大小如何影响准确性。目标很简单:我们希望在保持准确性的同时尽可能地缩短训练时间。我们在用于徽标检测的内部数据集中进行了这组实验。我们使用 MXNet 在一个 p2.8x large 实例上开展这些实验。如果检测区域和地面实测区域之间的交并比为 20% 或更高,则我们认为检测是正确的。首先,我们尝试了批处理大小 8:

训练的三个不同阶段的查准率查全率曲线。SSD 使用 300×300 像素的输入尺寸,批处理大小为 8。
如果我们同等地对查准率和查全率进行加权,就会得到大约 65% 的查准率和查全率。让我们看看使用 MXNet 调整 SSD 中的输入尺寸时会发生什么:

SSD 使用的输入尺寸为 512×512 像素,其他所有数据均与上一个实验相同。
此时,我们实际上看到性能有所改善,查准率和查全率均为 70% 左右。输入尺寸仍为 512×512 像素,我们来研究一下调整批处理大小对准确性有何影响。同样,我们的目标是保持准确性,同时尽可能缩短运行时间。
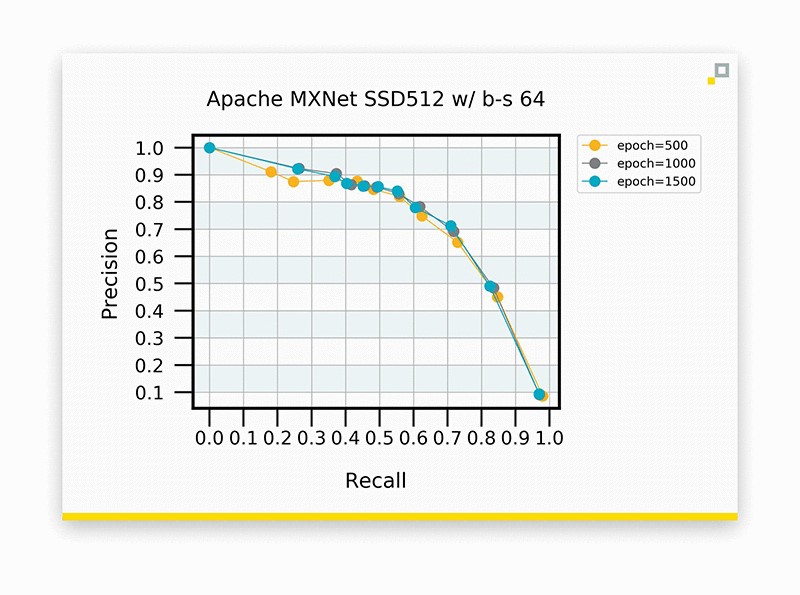
SSD 使用的输入尺寸为 512×512 像素,批处理大小为 64。准确性与之前的实验不差上下。
再试一次!准确性保持一致,我们可以通过更大的批处理大小来缩短训练时间,从而从中获益。本着科学的精神,让我们进一步深入实验…

SSD 使用的输入尺寸为 512×512 像素,批处理大小为 192。准确性与之前的实验不差上下。
基本相同,虽然我们的操作准确性与上一曲线相比有所下降。尽管如此,我们成功地保持了准确性,同时将批处理大小增加了 24 倍。重申一下,每个实验都是使用 MXNet 在实施了 SSD 的 p2.8x large 实例上进行的。下面是批处理大小实验的总结,显示了各个实验不差上下的准确性:

MXNet 的 SSD 与使用 Caffe 训练的 SSD 一样准确。
要点是准确性不差上下。言归正传,我们来研究一下训练时间:
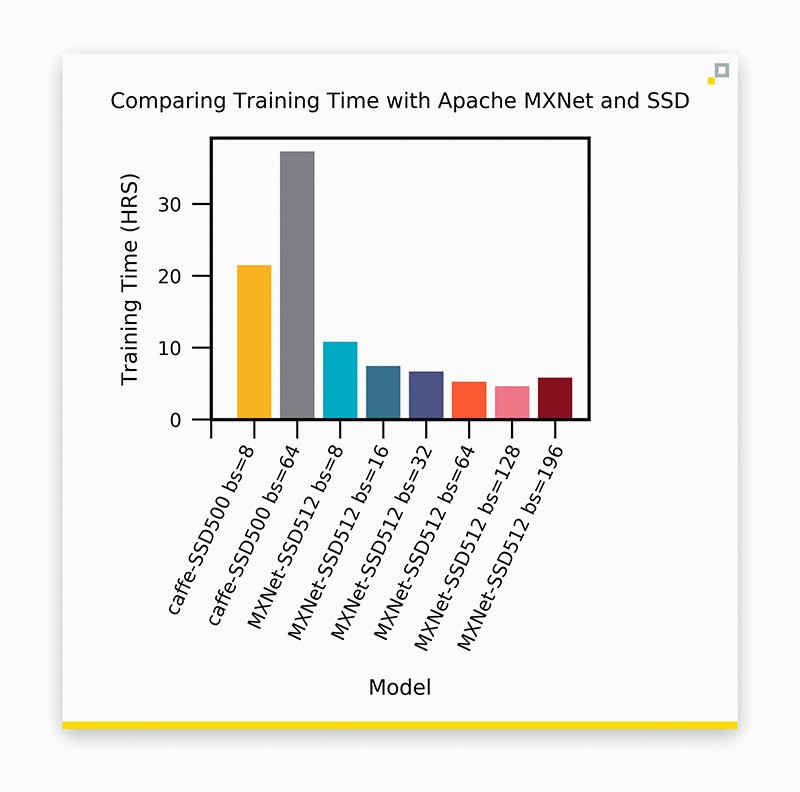
使用多种批处理大小的 Caffe 和 MXNet 的训练时间汇总。
当批处理大小增加时,预计减少的训练时间是显而易见的。不过,为什么我们在 Caffe 中增加批处理大小时,训练时间会大幅增加?我们来看看这两个 Caffe 实验的 nvidia-smi:
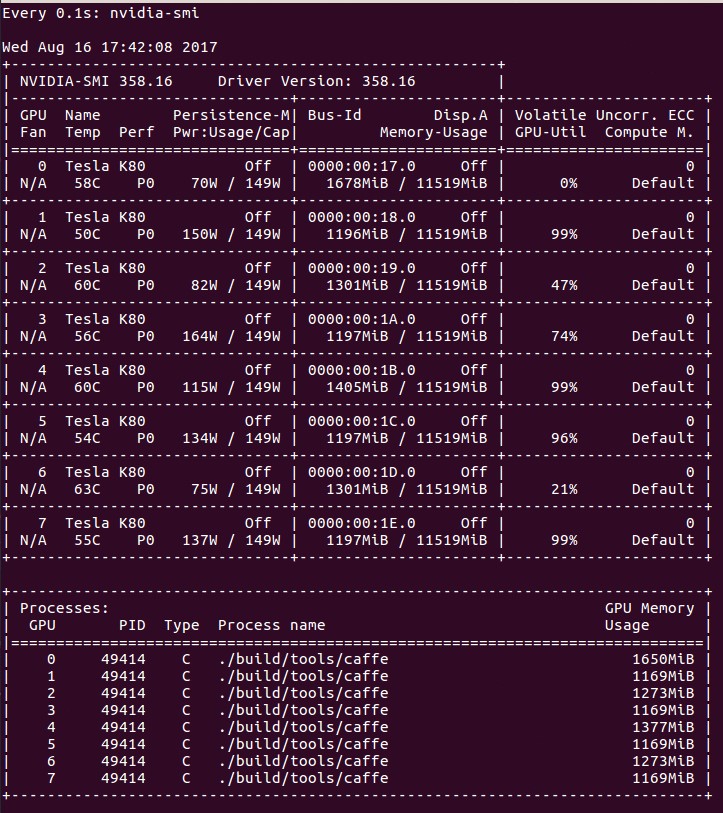
使用 Caffe 训练时 nvidia-smi 的输出,使用的批处理大小 8。请注意 GPU 使用率的波动。
GPU 要处理反向传播的巨大计算开销,这通过使用率峰值反应出来。为什么使用率会波动?可能是因为需要将训练数据从 CPU 批量传输到 GPU。在这种情况下,当 GPU 等待下一个批处理加载时,使用率将下降为 0%。我们来看看将批处理大小增加为 16 后的使用率:
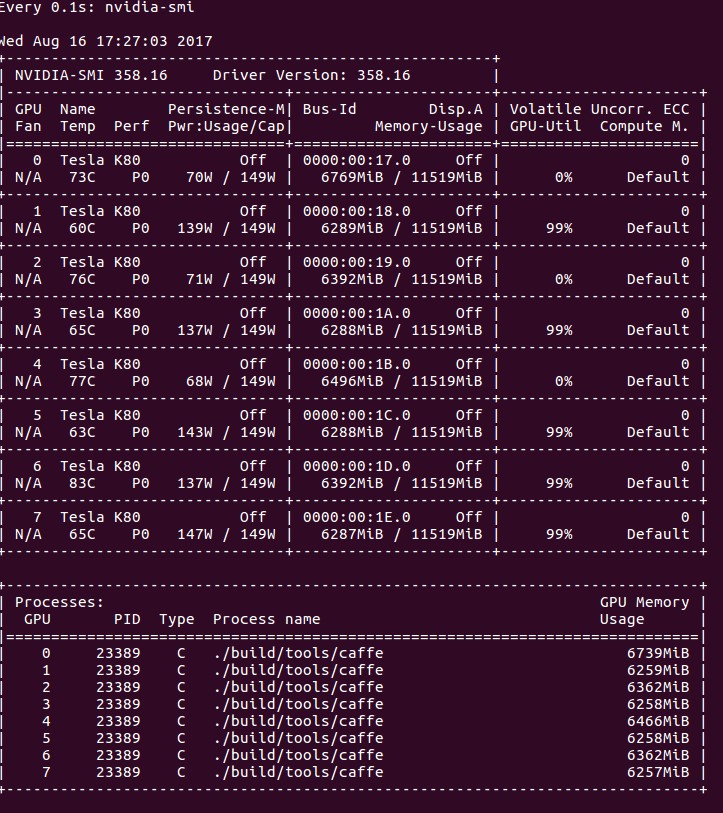
使用 Caffe 训练时 nvidia-smi 的输出,使用的批处理大小 16。
使用率停滞的情况更为夸张,揭示出显而易见的低效率。这解释了为什么增加批处理大小后训练时间反而增加的现象。这并不新鲜或出乎意料。事实上,我们使用 Keras (和 TensorFlow 后端) 训练 Siamese-VGG 网络时,也遇到过这个问题。关于这个话题的讨论通常倾向于“您的模型越复杂,您能感知到的 CPU 到 GPU 的瓶颈就越少。”虽然这是事实,但并没有多大帮助。是的,如果您通过增加计算梯度的方式让 GPU 承担更多工作,一定会看到平均 GPU 利用率的增加。我们不想增加模型的复杂性,即使我们这样做了,也不是为了帮助我们实现总体目标。在这里,我们关注的是绝对运行时间,而不是相对运行时间。
如果对我们的实验加以总结,那就是使用 Caffe 的 SSD 训练时间远远多于使用 MXNet 的训练时间。使用 MXNet,我们观察到训练时间稳步减少,直至我们达到 192 这一批处理大小临界规模。仅通过采用 MXNet,我们就将训练时间从 21.5 小时缩短为 4.6 小时。与此同时我们没有发现准确性有所降低。这么说绝不是在攻击 Caffe – 它是我们非常看重的一个框架 – 而只是为了庆祝 MXNet 取得的成功。我们可以通过多种方式批评数据加载问题。也许 Caffe2 已经解决了这个问题。在这里我想说明的是我们并不需要这么做,如果有任何东西能够让机器学习开发人员感到暖心,那就是编写尽可能少的代码。虽然我们还有一些问题尚未得到解答,但这是采用新工具时的正常现象。我们很乐意被当做“实验豚鼠”,并且对 MXNet 的未来充满希望。