亚马逊AWS官方博客
如何利用 Amazon ElastiCache for Redis 构建实时游戏排行榜
Original URL: https://amazonaws-china.com/cn/blogs/database/building-a-real-time-gaming-leaderboard-with-amazon-elasticache-for-redis/
游戏排行榜使玩家们能够直接比较自己在游戏中的表现,并以社交功能的形式提高玩家参与度、激励更多玩家投身于比赛。另外,排行榜数据还将为游戏中的算法提供信息支持,确保为玩家匹配到技战术水平相当的竞争对手。
在今天的文章中,我们将探讨使用传统关系数据库构建及扩展游戏排行榜时存在的实际挑战,同时研究如何利用现代内存内数据存储(特别是Redis)建立起高效且可扩展的解决方案。
在示例解决方案中,我们将把排行榜中的存储与查询功能由传统关系数据库转移至功能更强大的Redis Amazon ElastiCache。文中提及的方法不仅适用于游戏排行榜,也广泛适用于需要在应用程序内生成排名的各类使用场景。
背景介绍
使用传统关系数据库时,基础排行榜功能的构建步骤非常简单,通常包括:
- 创建一个表。
- 在分数发生变化时插入或更新分数值。
- 查询该表,并按降序方式检索排名。
以下为基于关系数据库的基础排行榜实现思路:
表中所示为基础排行榜schema的实现方式。当然,某些特定实现需求可能引入更多信息,例如引用其他游戏的game_id值或按时间戳对并列得分做出进一步排序。但其中的排行榜查询与更新思路仍然完全相同。
下面来看执行基础排行榜的表创建脚本:
在这种情况下,我们在user_id及score上添加了索引以实现快速添加及排序。在这里,我们使用以下原子SQL语句以增加或减少具体分数:
只要同时参与游戏的用户数量处于中低水平,以上设计就足以支撑起正常的排行榜功能。但随着游戏并发访问量的增加,这套架构将变得难以扩展:
- 表的规模越大,计算排名所带来的计算量就越大。
- 显示单一玩家排名,需要对排行榜上的所有相对位置进行计算。
- 排行榜中批量处理模式的生成与结果缓存机制虽然减少了循环计算量,但却拉低了整体用户体验。
对于规模较大的排行榜而言,计算特定玩家的排名可能占用大量资源。我们以下列查询为例:
在使用嵌套查询来计算用户排名的情况下,时间复杂度将呈现出平方关系。以包含5000万条记录(即使存在索引)的表为例,运行查询的平均时长达35秒。由于分数与排名一直在不断变化,我们将很难快速存储得分结果。
真正理想的解决方案,应该能够在用户数量快速增加的情况下,继续提供可预测的性能表现。同样的,这类解决方案也应实现轻松便捷的排行榜操作性能(例如检索最低分,或者按得分检索水平相似的玩家),而不必求助于缓慢而复杂的查询操作。
Redis为我们带来了一种高效且可扩展的解决方案。Redis是一种内存内数据存储方案,支持基本键-值功能。此外,它还支持多种数据结构,包括哈希、列表、集、排序集、范围查询以及地理空间索引等等。从这个角度来看,使用ElstiCache for Redis(而非传统关系数据库)将在存储与查询等操作层面带来潜在的性能优势。
ElastiCache for Redis具有以下优点:
- 为其他类型的请求预留更多数据库资源。
- 带来更高请求率,适用于缓存难度较高的数据。
- 支持经过优化的数据结构,更高效地处理排行榜用例。
ElastiCache简介
ElastiCache是一款全托管、低延迟的内存内数据存储方案,支持Memcached及Redis。利用ElastiCache,您可以轻松完成设置、安装、补丁修复、配置、监控、备份以及恢复恢复等常规管理任务,将更多精力集中在应用程序的实际开发当中。
以Redis为使用场景,EastiCache允许大家对读取及写入操作进行灵活的“纵向”及“横向”扩展。集群模式还提供额外的分片支持,借此实现写入扩展。EastiCache最多可支持250个分片,带来高达170.6 TB的内存内数据容量。此外,在线集群大小调整能够以零停机时间实现对各分片的规模伸缩。您也可以根据Amazon CloudWatch警报进行自动规模伸缩。要读取扩展方面,只需要添加更多读取副本,ElastiCache即可自动完成扩容工作。
排序集简介
排序集中容纳着具有相应分数的成员列表。尽管集中的各成员是唯一的,但分数值可以重复。分数用于按升序对列表成员进行排名。
排序集与关系数据库之间的一大主要区别,在于二者对列表进行排序操作的具体时间。排序集会在插入或更新操作期间自动以正确顺序放置各条目。由于存在这种预排序过程,因此查询的运行速度将明显加快。大家可以快速高效地查询列表的中间位置,或者获取特定成员的当前排名。排序集会以对数形式找到与成员数量成正比的特定排名。
相比之下,关系数据库会在查询期间对项目进行排序,从而显著提升了数据库的计算负担。获取特定玩家排名的速度,与时间复杂度的平方成正比。
下面来看利用排序集构建排行榜的几条常用命令:
- ZADD—向排序集中添加一个新成员,或者更新列表中原有成员的得分。
- ZRANGE—按升序方式获取特定范围内的排序成员,并利用排名范围(零索引)对其进行过滤。在降序排序场景中,需使用ZREVRANGE。
- ZRANK—获取成员的当前排名(零索引)。此排名按升序形式排列。在降序排序场景中,需使用ZREVRANK。
- ZRANGEBYSCORE—与ZRANGE类似,但对分数进行过滤。在降序排序场景中,需使用ZREVRANGEBYSCORE。
- ZSCORE—检索成员分数。
- ZREM—从排行榜中删除成员。
任何包含“rev”表示的排序集命令,都代表倒序或降序含义。
综合演练
为了演示上述功能的相互作用方式,我们创建出以下演示应用。下图所示为该应用的宏观架构。
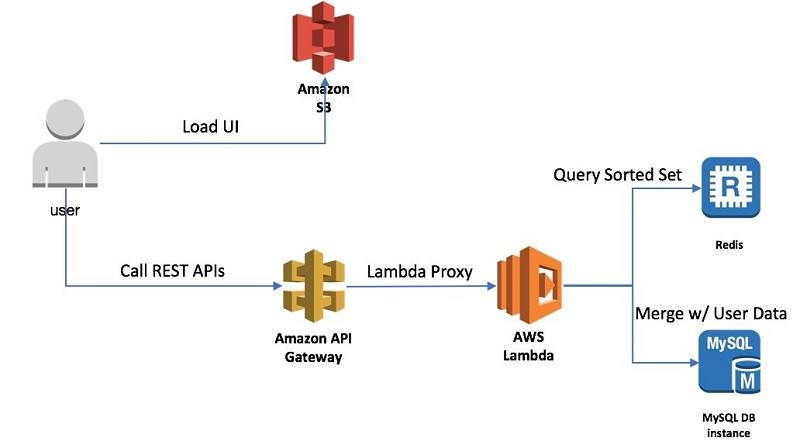
要测试这些元素如何协同工作,请启动AWS CloudFormation堆栈。该堆栈将创建以下资源:
- AWS Lambda函数
- Amazon API Gateway API操作
- 参数
Lambda函数
下表列出了由AWS CloudFormation堆栈为演示应用程序创建的各项函数。
| 函数 | 描述 |
| LeaderboardRetrievePlayerInfo | 从Redis中检索玩家的排名与得分。 |
| LeaderboardUpsertScore | 在Redis中更新或插入现有玩家得分。 |
| LeaderboardSearchUser | 搜索MySQL数据库内的users表。 |
| LeaderboardRetrieveTop10 | 从Redis中检索前10名用户,并将结果与MySQL数据库中的用户详情信息合并。 |
| LeaderboardLoadFrontend | 由AWS CloudFormation模板用作自定义资源,对作为托管前端的S3存储桶进行正确初始化。 |
API Gateway API操作
AWS CloudFormation模板还将创建作为Lambda函数代理的API。API的基本结构如下:
参数
下表所示,为AWS CloudFormation(https://eu-west-1.console.aws.amazon.com/cloudformation/home?region=eu-west-1#/stacks/create/review?templateURL=https://s3-eu-west-1.amazonaws.com/jan-elasticache-blog/leaderboard_demo.yaml&stackName=RedisLeaderboardDemo)堆栈为演示应用程序创建的参数。
| 路径 | 用途 |
| /leaderboard/player-info | 通过查询字符串传递user_id参数,借此指示排名与分数信息检索操作所指向的用户。 |
| /users/score | 在请求正文中传递以下JSON: |
| /users/search | 通过查询字符串传递username参数,从而搜索现有用户。此用户名中可包含通配符,因此可在未完整输入的情况下实现搜索。 |
Redis与MySQL
我们已经在两个数据库内预先加载了100万条用户/得分记录。在MySQL中,数据库包含两份表:users与leaderboard。在Redis方面,排序集键为leaderboard。MySQL与Redis中的数据内容基本相同,因此大家可以快速比较二者的查询响应时间。
访问前端与后端
在AWS CloudFormation完成堆栈构建之后,我们可以从堆栈的Output选项卡中找到两条URL,具体如以下截图所示。

其中APIGatewayInvokeURL为指向REST API后端的URL。要查看返回的实际有效负载,请直接对该端点执行API调用。关于更多详细信息,请参阅前文中的API Gateway章节。
大家可以在浏览器内直接打开FrontendURL以查看演示应用程序。具体参见以下截图。

您可以在这里搜索用户名称、查看其当前排名与分数,并更改其当前分数。分数更新过程会刷新前10名列表。
与Redis交互
在演示应用程序向Redis实例发送命令之前,我们首先需要完成以下两项工作:
- 安装node_redis。
- 安装客户端对象。
安装node_redis库
由于演示应用程序使用Node.js,因此请运行以下命令以安装该库:
客户端对象初始化
在库安装完成后,您可以使用以下命令创建一个客户端对象,进而接入Redis实例:
通过Redis命令执行常见的排行榜操作
以下为各类常见排行榜操作及其对应Redis命令:
插入/更新用户得分
要插入或更新玩家得分,请使用以下命令:
redisClient.zadd([key, score, userId], callback);
检索用户得分
以下命令可检索特定用户ID的得分。在使用zadd命令插入成员及其得分时,本示例使用user_id作为成员标识符:
redisClient.zscore([key, userId], callback);
检索用户列表
我们可以使用zrange与zrevrange两条命令检索用户范围。在演示应用程序中,我们选择使用zrevrange,这是因为本排行榜采用降序排列:
redisClient.zrevrange([key, min, max, “WITHSCORES”], callback);
排序集基于零索引数组上的min或max参数,其中min的最小值为#1.参数“WITHSCORES”意味着结果将包含各玩家的得分。此参数将影响结果数组,例如:[<user1>, <score>, <user2>, <score>, <user3>, <score>…]。如果不添加“WITHSCORES”参数,则结果只显示用户数组。
检索用户排名
与检索用户列表一样,我们也可以使用以下两条命令检索用户排名:zrank与zrevrank。在演示应用程序当中,我们选择使用zrevrange,这是因为本排行榜采用降序排列:
redisClient.zrevrank([key, userId], callback);
规模伸缩
ElastiCache支持在线集群大小调整,能够以零停机时间为前提实现各分片的规模伸缩。您也可以根据CloudWatch警报来调整集群大小,从而自动适应峰值与非峰值期的实际流量水平。
负责实现大小调整功能的API为ModifyReplicationGroupShardConfiguration,其能够添加其他分片、删除分片或者对现有分片进行键空间重新均衡。
总结
在正确的用例中使用正确的数据存储方案并配合正确的数据访问模式,不仅能够显著提升应用程序性能,同时也将有效降低运营成本。
除了排序集之外,Redis还提供其他多种数据结构,能够充分满足流行行业的实际需求。Redis说明文档中还详细介绍了每条命令的时间复杂度,帮助大家了解系统性能将如何随用户数量的增加而变化。
本篇作者