1.前言
在量化交易策略的开发工作中,需要历史数据来验证交易策略的表现,这种模式称之为回测。历史数据会随着时间的推移增长,策略研究员也会研究新的交易因子,结合交易品种的数量,会催生大量的回测任务计算需求。这种计算任务对于计算资源的需求,非常适合利用云上的弹性计算资源来实现。 本文会介绍一种基于AWS Batch服务建立的量化回测系统,利用AWS Batch服务,可以利用容器化技术,快速调度计算资源,完成回测任务。
2.方案介绍
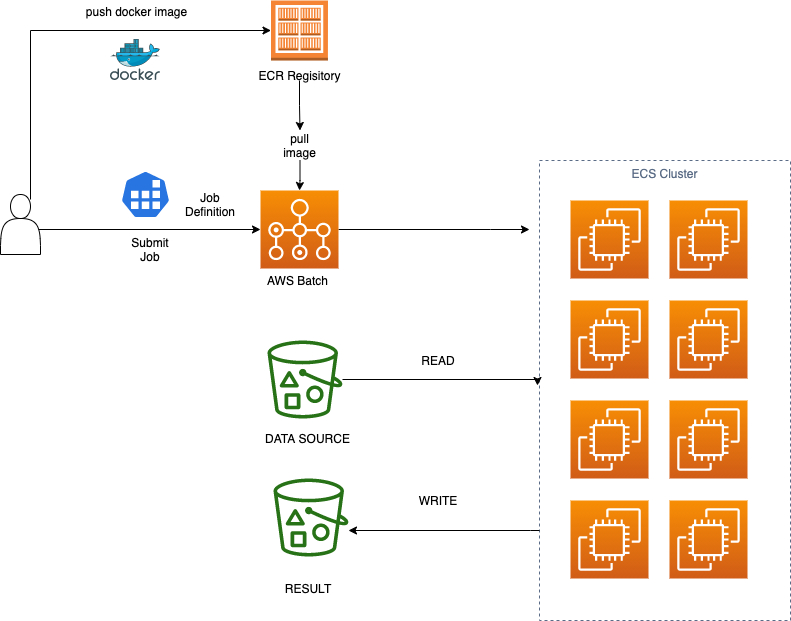
方案架构图如下所示,用户会使用Sagemaker Jupyter Notebook进行代码编写和任务提交等操作。在这个方案中,用户的回测任务提交只需要以下三个步骤:
- 将策略代码打包成为docker镜像
- 推送到托管服务ECR中
- 提交任务到AWS Batch
AWS Batch会根据提交的参数,自动分配计算资源,下载特定品种的历史数据,回测完成后,上传结果数据到S3存储桶,并自动回收计算资源。

3.服务介绍
本方案主要使用了AWS Batch作为计算资源的调度服务,要了解方案必须要对AWS Batch的以下几个概念有所了解:
3.1AWS Batch
AWS Batch可帮助运行任意规模的批量计算工作负载,该服务根据工作负载的数量和规模自动预配置计算资源并优化工作负载分配,通过使用AWS Batch,不再需要安装或管理批量计算软件,从而使您可以将时间放在分析结果和解决问题。
compute environment
- 计算环境是一组用于运行任务的托管或非托管计算资源。使用托管计算环境,您可以在多个详细级别指定所需的计算类型(Fargate 或 EC2)。您可以设置使用特定类型 EC2 实例的计算环境。AWS Batch根据需要高效地启动、管理和终止计算类型。
queue
- 当您提交AWS Batch作业时,会将其提交到特定的任务队列中,然后作业驻留在那里直到被安排到计算环境中为止。
Job Definition
- Job Definition指定作业的运行方式。您可以把任务定义看成是任务中的资源的蓝图。您可以为您的任务提供 IAM 角色,以提供对其他AWS资源的费用。您还可以指定内存和 CPU 要求。任务定义还可以控制容器属性、环境变量和持久性存储的挂载点。任务定义中的许多规范可以通过在提交单个任务时指定新值来覆盖。
Jobs
- 提交到 AWS Batch 的工作单位 (如 shell 脚本、Linux 可执行文件或 Docker 容器映像)。会作为一个容器化应用程序运行在AWS Fargate或 Amazon EC2 上,使用您在Job Definition中指定的参数。
3.2 SageMaker Notebook实例
Amazon SageMaker Notebook 实例是一个机器学习 (ML) 计算实例,运行 Jupyter Notebook 应用程序。Jupyter Notebook 提供一种网页形式的简单 IDE,可以在网页中交互式地编写代码和运行代码,直接返回逐段代码的运行结果。同时 Notebook 中还可以穿插必要的说明文档和图片,便于对代码进行说明和解释
4.环境准备
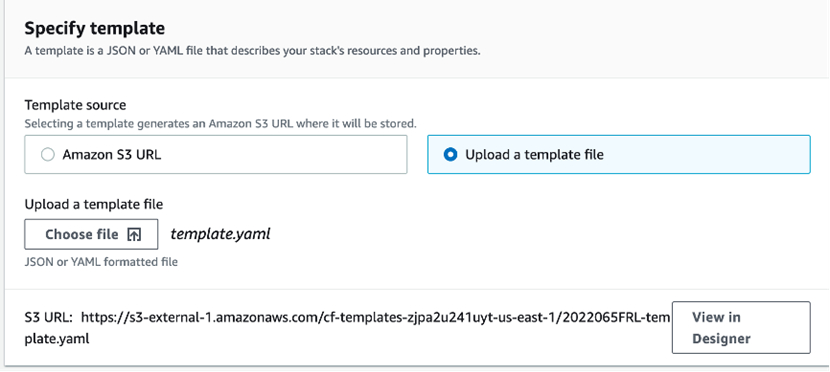
为了实验方便,我们推荐使用Cloudformation快速创建环境。在这个环节中,我们将通过预先准备好的 CloudFormation 模板创建实验的基础网络环境和实验资源。通过以下代码下载template.yaml。
curl -LJO https://raw.githubusercontent.com/forhead/build_backtest_with_aws_batch/main/content/template.yaml
通过此链接直接导航到 CloudFormation 控制台创建新堆栈的界面:CloudFormation。
- 在控制台选择Upload a template file,然后点击Chose file,选择上一步中下载的模板

- 上传完成后点击Next
- 在下一步中,列出了模板所需的参数。在Stack name 选项中填入 backtest,其他参数保持默认,然后点击Next:
- 直接点击Next到最终的审核步骤
- 滑到最下方,勾选I acknowledge that AWS CloudFormation might create IAM resources with custom names.,然后点击Create stack按钮:

5.方案实现
下面跟着我们一步步的搭建基于AWS Batch的量化回测方案。
- 首先执行以下代码,下载
backtest.ipynb
curl -LJO https://raw.githubusercontent.com/forhead/build_backtest_with_aws_batch/main/content/backtest.ipynb

- 打开后,点击上传按钮,上传
backtest.ipynb文件

- 上传完成后,打开Notebook,可以看到以下的界面,点击运行可以执行Notebook中的代码块

import boto3
aws_account_id = boto3.client('sts').get_caller_identity().get('Account')
repository_name = 'backtest-repo'
aws_region = 'us-east-1'
s3_source = 'backtest-source-2022-03-07' # 用于存储数据源,请按照自己的习惯修改修改名称
s3_dest = 'backtest-dest-2022-03-07' # 用于存储计算结果,请按照自己的习惯修改名称
- 创建两个S3存储桶,分别用来作为数据源存储股票历史数据,以及存储回测结果
import boto3
s3 = boto3.client('s3',region_name=aws_region)
# 创建存储桶
s3.create_bucket(Bucket=s3_source)
s3.create_bucket(Bucket=s3_dest)
# 确认存储桶创建成功
if s3.head_bucket(Bucket=s3_source)['ResponseMetadata']['HTTPStatusCode']==200:
print(s3_source,' created')
if s3.head_bucket(Bucket=s3_dest)['ResponseMetadata']['HTTPStatusCode']==200:
print(s3_dest,' created')
! rm -rf /home/ec2-user/SageMaker/build_backtest_with_aws_batch
! git clone https://github.com/forhead/build_backtest_with_aws_batch.git
! aws s3 sync build_backtest_with_aws_batch/data_source s3://{s3_source}/
- 因为AWS Batch执行任务基于容器来运行,所以只需要让代码可以接受参数,在参数中定义”历史数据存储桶位置”,”历史数据文件名”以及”结果存储桶位置”。
!mkdir batch
%%writefile batch/backtest.py
#!/usr/bin/env python
from __future__ import (absolute_import, division, print_function,
unicode_literals)
import datetime
import boto3
import json
import numpy as np
import pandas as pd
import os.path
import sys
import pytz
import time
from os.path import exists
import backtrader as bt
class MyStrategy(bt.Strategy):
## 1、全局参数
params=(('maperiod', 15),
('printlog', False),)
## 2、初始化
def __init__(self):
# 初始化交易指令、买卖价格和手续费
self.order = None
self.buyprice = None
self.buycomm = None
# 添加15日移动均线指标。Backtrader 集成了 talib,可以自动算出一些常见的技术指标
self.sma = bt.indicators.SimpleMovingAverage(self.datas[0], period=self.params.maperiod)
## 3、策略核心逻辑
def next(self):
# 记录收盘价
# self.log('收盘价:%.2f' % self.datas[0].close[0])
if self.order: # 检查是否有指令等待执行
return
# 检查是否持仓
if not self.position: # 没有持仓
# 执行买入条件判断:收盘价格上涨突破15日均线
if self.datas[0].close > self.sma[0]:
self.size = int(self.broker.cash / self.datas[0].close[0])
self.log('买入委托:%.2f * %.0f' % (self.datas[0].close[0], self.size))
#执行买入
self.order = self.buy(size=self.size)
else:
# 执行卖出条件判断:收盘价格跌破15日均线
if self.datas[0].close < self.sma[0]:
self.log('卖出委托:%.2f * %.0f' % (self.datas[0].close[0], self.size))
#执行卖出
self.order = self.sell(size=self.size)
## 4、日志记录
# 交易记录日志(可选,默认不输出结果)
def log(self, txt, dt=None, doprint=False):
if self.params.printlog or doprint:
dt = dt or self.datas[0].datetime.date(0)
print(f'{dt.isoformat()},{txt}')
# 记录交易执行情况(可选,默认不输出结果)
def notify_order(self, order):
# 如果 order 为 submitted/accepted,返回空
if order.status in [order.Submitted, order.Accepted]:
return
# 如果 order 为 buy/sell executed,报告价格结果
if order.status in [order.Completed]:
if order.isbuy():
self.log(f'买入:\n价格:%.2f,\
现金流:-%.2f,\
手续费:%.2f' % (order.executed.price, order.executed.value, order.executed.comm))
self.buyprice = order.executed.price
self.buycomm = order.executed.comm
else:
self.log(f'卖出:\n价格:%.2f,\
现金流:%.2f,\
手续费:%.2f' % (order.executed.price, order.executed.price*self.size, order.executed.comm))
self.bar_executed = len(self)
# 如果指令取消/交易失败, 报告结果
elif order.status in [order.Canceled, order.Margin, order.Rejected]:
self.log('交易失败')
self.order = None
# 记录交易收益情况(可省略,默认不输出结果)
def notify_trade(self,trade):
if not trade.isclosed:
return
self.log(f'策略收益:\n毛收益 {trade.pnl:.2f}, 净收益 {trade.pnlcomm:.2f}')
# 回测结束后输出结果(可省略,默认输出结果)
def stop(self):
self.log('(MA均线: %2d日) 期末总资金 %.2f' %
(self.params.maperiod, self.broker.getvalue()), doprint=True)
def downloadFile(bucket_name, object_name, file_name):
s3 = boto3.client('s3',region_name='us-east-1')
s3.download_file(bucket_name, object_name, file_name)
def uploadFile(file_name,bucket_name, key_name):
s3 = boto3.client('s3',region_name='us-east-1')
s3.upload_file(file_name,bucket_name, key_name)
def readData(file_name):
df = pd.read_csv(file_name)
df['ticker'] = df['ticker'].apply(lambda x: str(x))
df['ticker'] = df['ticker'].apply(lambda x: '0'*(6-len(x)) + x)
df['openprice'] = df['openprice'] * df['accumadjfactor'] / df['accumadjfactor'].iloc[-1]
df['closeprice'] = df['closeprice'] * df['accumadjfactor'] / df['accumadjfactor'].iloc[-1]
df['highestprice'] = df['highestprice'] * df['accumadjfactor'] / df['accumadjfactor'].iloc[-1]
df['lowestprice'] = df['lowestprice'] * df['accumadjfactor'] / df['accumadjfactor'].iloc[-1]
df = df[df['isopen'] == True]
df.drop('isopen', 1, inplace=True)
df.drop('accumadjfactor', 1, inplace=True)
df.set_index('tradedate', inplace=True)
df.rename(columns={'openprice': 'open'}, inplace=True)
df.rename(columns={'closeprice': 'close'}, inplace=True)
df.rename(columns={'highestprice': 'high'}, inplace=True)
df.rename(columns={'lowestprice': 'low'}, inplace=True)
df.rename(columns={'turnovervol': 'volume'}, inplace=True)
df['openinterest'] = 0 # A股回测中一般并不考虑利率,通常可以直接设为 0
return df
if __name__ == '__main__':
# 创建 Cerebro 对象
cerebro = bt.Cerebro()
# 读取输入参数,读取s3数据源数据,然后转化为dataframe
source_bucket_name = sys.argv[1]
source_file_name = sys.argv[2]
dest_bucket_name = sys.argv[3]
dest_file_name = source_file_name[:-3]+time.strftime("%Y-%m-%d-%H_%M_%S",time.localtime(time.time()))
downloadFile(source_bucket_name, source_file_name, source_file_name)
while not os.path.exists(source_file_name):
time.sleep(5)
df = readData(source_file_name)
# 创建 Data Feed
df.index = pd.to_datetime(df.index)
start = df.index[0]
end = df.index[-1]
print(start, '-', end)
data = bt.feeds.PandasData(dataname=df, fromdate=start, todate=end)
# 将 Data Feed 添加至 Cerebro
cerebro.adddata(data)
# 添加策略 Cerebro
cerebro.addstrategy(MyStrategy, maperiod=15, printlog=True)
# 设置初始资金
cerebro.broker.setcash(100000.0)
# 设置手续费为万二
cerebro.broker.setcommission(commission=0.0002)
# 在开始时 print 初始账户价值
print('Starting Portfolio Value: %.2f' % cerebro.broker.getvalue())
# 运行回测流程
cerebro.run()
# 在结束时写入结果到S3存储桶
f = open(dest_file_name, "a")
f.write('Final Portfolio Value: %.2f\n' % cerebro.broker.getvalue())
f.write('Return: %.4f' % (float(cerebro.broker.getvalue())/1e5 - 1))
f.close()
uploadFile(dest_file_name,dest_bucket_name,dest_file_name)
sys.exit(0)
!pip install --upgrade pip
!pip install backtrader
!pip install matplotlib==3.2.0
!pip show backtrader
!python batch/backtest.py {s3_source} 600519.csv {s3_dest}
除了可以看到大量输出外,还可以在存储结果的S3存储桶(这里是 backtest-dest-2022-03-07)中看到结果文件

下载后可以看到类似以下的输出:
Final Portfolio Value: 164109.44
Return: 0.6411
- 创建一个镜像仓库,并推送容器镜像,依次执行notebook中的代码
import boto3
ecr = boto3.client('ecr', region_name=aws_region)
ecr.create_repository(repositoryName=repository_name)
创建Dockerfile
%%writefile batch/Dockerfile
FROM python:3.8
RUN pip --no-cache-dir install \
backtrader\
boto3 \
pandas
RUN pip install matplotlib==3.2.0
ENV PYTHONUNBUFFERED=TRUE
ENV PYTHONDONTWRITEBYTECODE=TRUE
COPY backtest.py /
RUN chmod -R 777 backtest.py
将容器推送到远程的ECR镜像仓库
!docker build batch -t {repository_name}
!docker tag {repository_name} {aws_account_id}.dkr.ecr.{aws_region}.amazonaws.com/{repository_name}
!aws ecr get-login-password | docker login --username AWS --password-stdin {aws_account_id}.dkr.ecr.{aws_region}.amazonaws.com
!docker push {aws_account_id}.dkr.ecr.{aws_region}.amazonaws.com/{repository_name}
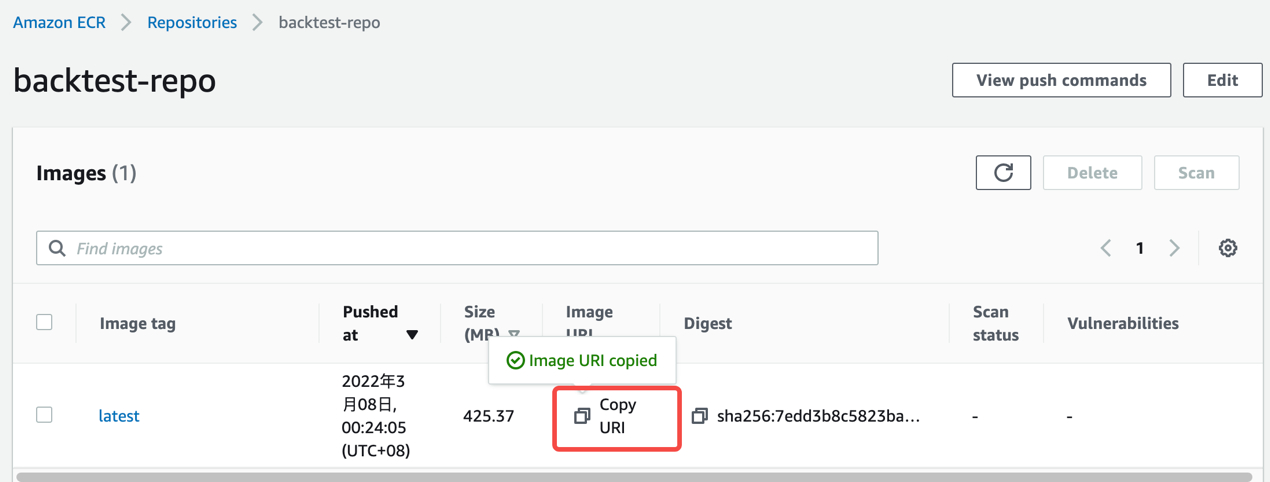
- 至此,我们已经成功将回测程序容器化,并且推送到ECR的镜像服务器上。打开以下地址 Repositories,可以看到创建的镜像仓库。


- 选择Fargate,其他全部选择默认即可,点击创建,计算环境创建完毕

- 创建Job Queue。 选择左侧的Job queues菜单,然后在右边点击Create按钮。

- 输出名称,backtest-queue,然后再选择compute environment的下拉框中选择上一步创建的计算环境,点击创建后等待Queue的状态变成VALID。

- 创建Job Definition。点击Job definitions,创建任务定义,选择Single-node模式,取名backtest_600519, timeout选择300s

- 平台选择Fargate,Execution role选择ecsTaskExecutionRole, 并开启 Assign public IP开关,


- 把拷贝的URI地址设置为Image地址,并将执行指令设置到Command中
python backtest.py backtest-source-2022-03-07 600519.csv backtest-dest-2022-03-07

- 设置Job Role的执行角色为 ecsTaskExecutionRole,并指定重试次数为一次


- 提交任务。选中创建的Job Definition,点击Submit new job,创建任务,如下图所示

按照以下截图设置任务名称后,其他都设置默认值,提交任务

- 在Jobs页面等待任务的状态变成 SUCCEEDED 后,代表任务完成。去S3存储桶查看,可以发现已经有了结果文件

6.进阶部分
上面创建了基础的AWS Batch所需的环境,并且提交了单个任务。下面我们要实现的是提交多个回测任务,并行计算。有了前面的基础之后,我们再次回到Sage Maker Notebook。 在上面的实验中,在提交任务(Job)的时候,我们可以选择更改Command属性,来覆盖Job Definition中的执行指令。利用这一个特性,可以通过遍历所有已经存在的历史数据文件名,来批量生成Command,提交任务覆盖Job Definition中的Command,在本次实验中,我们可以执行以下代码来批量提交回测任务
import boto3
batch_client = boto3.client('batch')
def submit_job(job_name, queue_name, job_definition, command):
response = batch_client.submit_job(
jobName=job_name,
jobQueue= queue_name,
jobDefinition=job_definition,
containerOverrides={
'command': command
}
)
# 在AWS Batch中定义好的任务queue
quene_name = 'backtest-queue'
# 在AWS Batch中定义好的job definition名
job_definition = 'backtest_strategy_1'
# 存储桶名
s3_source = 'backtest-source-2022-03-07' # 用于存储数据源,请按照自己的习惯修改修改名称
s3_dest = 'backtest-dest-2022-03-07' # 用于存储计算结果,请按照自己的习惯修改名称
source_file_list=['600519.csv','600559.csv','600560.csv']
# 循环提交所有的任务,通过复用job definition,覆盖Command的方式提交Job
for file in source_file_list:
# 依据文件名生成不同的Job任务的执行指令
#"python","backtest.py","backtest-source-2022-03-07","600519.csv","backtest-dest-2022-03-07"
command = ["python","backtest.py",s3_source,file,s3_dest]
job_name = job_definition + '_for_'+file[:-4] # Job名称为 jobDefinition_for_filename
submit_job(job_name,quene_name,job_definition,command)
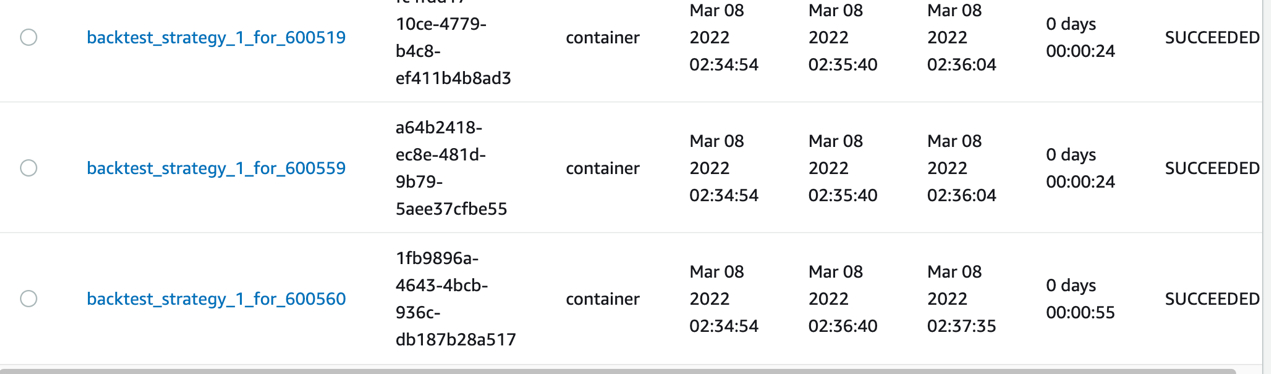
- 提交任务后,可以看到提交的三个任务已经成功,并且在S3存储桶中,也有三个结果文件,如下所示:


7.总结
在本篇文章中,我们基于AWS Batch实现了批量运行Backtest的方案,所有的backtest任务结束后,计算资源都会自动回收,充分利用了云的弹性。 除了在文章中展示的方案内容,我们还可以利用AWS的托管服务实现以下的功能:
- 基于IAM做了权限的管控和资源隔离
- 基于SNS做事件通知
- 基于Lambda定时任务清理Job
- 基于Cloudwatch做资源使用效率监控,优化资源利用率
本篇作者