亚马逊AWS官方博客
Category: Analytics

使用 Apache SeaTunnel 快速集成数据到S3 Tables
本文将介绍,如何使用 Apache SeaTunnel ,一个高性能、分布式的大规模数据集成工具,通过兼容 Iceberg rest catalog 的实现对接 S3 Tables 实现实时和批量数据集成。
新一代SageMaker+Databricks统一目录:机器学习与数据分析工作流打通方案
通过SageMaker Unified Studio与Databricks Unity Catalog的深度集成,企业既能充分利用Databricks强大的数据分析能力,又能与AWS上现有的业务系统深度融合,真正实现数据价值的最大化
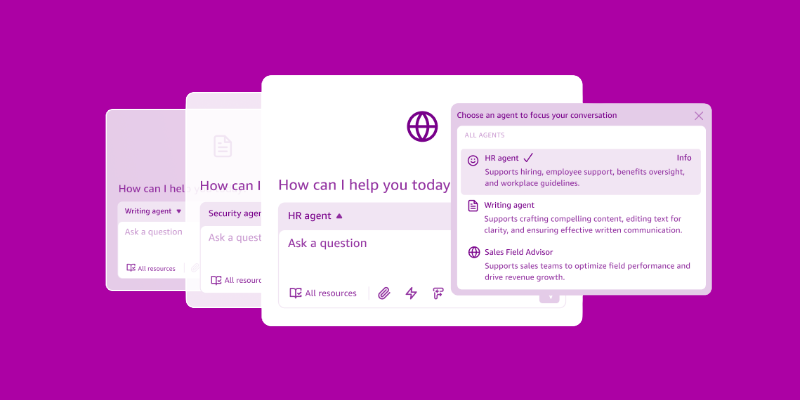
宣布推出 Amazon Quick Suite:您的代理式团队成员,负责回答问题和采取措施
今天,我们宣布推出 Amazon Quick Suite,这是一个新的代理式团队成员,可以快速回答您在工作 […]

AWS 一周综述:Amazon S3、Amazon Bedrock AgentCore、AWS X-Ray 等(2025 年 9 月 29 日)
真是不敢相信! 已经快到年底了。大家都知道,接下来我们会举行 AWS re:Invent! 这是我们最大的活动 […]
如何在Amazon Athena中在线解密在Amazon Glue DataBrew中加密的数据
背景分析 在企业数字化转型的浪潮中,依托于数据驱动的决策和洞察变得尤为重要。云端数据湖已成为企业汇聚、加工和分 […]
使用大模型技术构建机票分销领域人工智能客服助手
一. 需求背景 1.1 行业痛点 在机票分销领域,大型票务代理是供应链的中转枢纽,他们上游对接各大航空公司,下 […]

AWS 一周综述:SQS 公平队列、CloudWatch 生成式人工智能可观测性等(2025 年 7 月 28 日)
说实话,我还没从纽约 AWS Summit 中缓过劲儿来,正在努力了解 Amazon Bedrock Agen […]
基于 CoT 协调多 MCP Tool — 智能运维 Redshift
本文详细介绍了一种基于 Q Developer CLI+Remote MCP+Redshift 的智能化运维解决方案,提升性能优化、错误排查与集群巡检等 Redshift 常见运维场景的效率。方案中基于思维链(Chain of Thought, COT)协调多个模型上下文协议(Model Context Protocol, MCP),让 Q Developer CLI 按照预期完成工作,有效解决了单纯”Agent+Remote MCP”模式中 Agent 任务规划不符合用户预期的问题。
基于 Amazon Q Developer+Remote MCP 访问 Amazon Redshift
Amazon Q Developer 结合模型上下文协议(MCP)实现了与 Amazon Redshift 的创新集成,使开发者能够通过自然语言直接查询和分析数据仓库中的信息,比如查询数据仓库中的业务表数据,以及自动生成系统表的 SQL 定位 Amazon Redshift 常见问题。

AWS AI League:学习、创新,在全新终极 AI 巅峰对决中一较高下
自 2018 年以来,AWS DeepRacer 已吸引全球超 56 万名开发者参与,这表明开发者能在竞技体验 […]