亚马逊AWS官方博客
Category: Artificial Intelligence

使用大模型技术构建机票分销领域人工智能客服助手
一. 需求背景 1.1 行业痛点 在机票分销领域,大型票务代理是供应链的中转枢纽,他们上游对接各大航空公司,下 […]
基于Strands Agent框架的考题生成及Agent 效果评估
一、项目概述 1.1 项目背景与目标 在教育领域,考试(一年级-高三年级,数学/科学/英语/历史等多学科)作为 […]
基于 HAMi 的 GPU 虚拟化实践
1. 引子 在当下的 AI/ML 应用实践中,我们能明显感受到两股趋势的并行发展: 一方面,传统的小模型推理与 […]
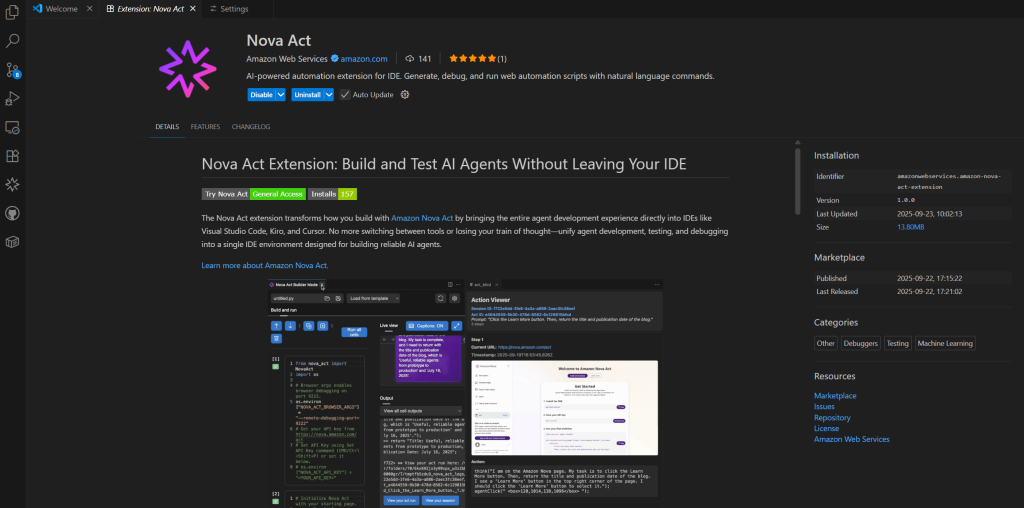
使用 Nova Act IDE 扩展程序加速人工智能代理开发
今天,我很高兴地宣布推出 Nova Act 扩展程序,该工具简化了无需离开 IDE 即可构建浏览器自动化代理的 […]
阿尔特携手 Amazon AgentCore ,打造懂你的AI,智能搜索成本降低34%
关于Monus AI Monus AI是由南京阿尔特科技推出的一款专注于消费决策的AI搜索应用,在搜索垂类工具 […]
Agentic AI基础设施实践经验系列(一):Agent应用开发与落地实践思考
探讨Agent开发和运维Agent(AgentOps)的基本要素和实践思考。
Amazon Bedrock AgentCore Memory:亚马逊云科技的托管记忆解决方案
亚马逊云科技提供开箱即用的托管服务,通过AI Agent构建平台Bedrock AgentCore中的记忆模块 […]
Agentic AI基础设施实践经验系列(四):MCP服务器从本地到云端的部署演进
引言 随着人工智能技术的快速发展,特别是大语言模型(LLM)的广泛应用,Agentic AI(智能体AI)正在 […]
Agentic AI基础设施实践经验系列(三):Agent记忆模块的最佳实践
本文将深入探讨 Agent应用中的记忆需求、记忆类型、技术组件和主流开源框架,并介绍基于亚马逊云科技的数据产品自行构建记忆模块,以及基于Agent构建平台Bedrock AgentCore的Agent memory的托管方案。
Agentic AI基础设施实践经验系列(七):可观测性在Agent应用的挑战与实践
一. 引言: 我们正处在一个由 AI Agent 驱动的范式转换前夜。它们不再只是简单的文本生成器,而是能够理 […]