亚马逊AWS官方博客
基于 Comprehend 的玩家评论分析解决方案
背景
如今,在一个互联网高度发达的社会中,人们的娱乐方式更多的由线下转为线上,而更好的游戏体验无疑是吸引更多的游戏玩家首要因素,而一个游戏的成功与否不仅仅是在于游戏产品设计师和游戏开发者的设计,更多的是在后续的游戏版本更迭中,更多的保留吸引用户的元素和用户喜爱的环节,去除用户不喜欢的元素,改掉用户提出的缺点。而如今游戏民意的收集却是广大游戏开发者和设计者的难题,原因一是在于游戏发布平台的非常广,且需要分别根据游戏名称,国家和版本进行分别归类,二是在于对于评论文字的分析并从中提取出用户的情绪和关键字,从而得知游戏的优缺点,这其实是一项基于机器学习自然语言处理的任务,需要专业的自然语言处理相关的算法工程师进行解决,由此投入不菲的人力物力。基于Comprehend 的玩家评论分析解决方案分别抓取Apple App Store 和Google Play这两大主流游戏发行平台的评论数据,并利用Comprehend—AWS托管的自然语言处理服务,进行情绪分析和关键词检测,定期抓取新增评论并进行分析,最终实现在QuickSight的可视化面板中展示分析结果。该解决方案可使用Cloudformation 快速部署,帮助用户快速实现对游戏评论分析的需求。
解决方案概述
此解决方案使用户可以快速在AWS 云上构建高可用和无服务器的玩家评论分析系统,用以实现对不同版本,不同国家游戏玩家体验的收集和分析,用于阶段性总结游戏的优势与缺点,为游戏的更迭和更好的吸引客户打下基础。该解决方案使用Fargate作为无服务器容器计算服务运行抓取代码,借助AWS Fargate,您无需预置和管理容器实例,相关代码逻辑会在初始化过程中和之后每天一次的频率由Cloudwatch自动触发运行,运行过程中会读取存储在S3中的相关游戏信息文件。CloudWatch是AWS的管理监控服务,本解决方案中,由CloudWatch配置定时任务规则,以便每天更新新的评论数据分析。另外,本解决方案使用Aurora Serverless版本作为系统数据库,用于存储抓取的评论数据和相关信息。Aurora Serverless 数据库集群会根据您应用程序的需求自动启动、关闭以及扩展或缩减容量,非常适合这种不频发的工作负载,同时大幅节省了成本。数据库表结构的初始化工作由Lambda完成。Lambda是AWS的无服务计算服务,无需预置或管理服务器即可运行代码。可以设置为自动从其他 AWS 产品触发,只需按使用的计算时间付费, Lambda 在本解决方案中由Cloudformation自动部署脚本触发执行数据库初始化的工作。对于本解决方案的核心,文本分析功能,我们使用Amazon Comprehend作为提取文本的分析工具,用于提取语句的关键词和情感倾向。Amazon Comprehend 是一项自然语言处理 (NLP) 服务,可通过机器学习发现文本中的见解和关系。不需要有机器学习经验。Comprehend拥有关键词提取,情绪分析,实体识别等诸多功能,可以分析一系列文本文件,并自动按相关术语或主题对它们进行整理,还可以基于自己的业务逻辑设置自定义标签,并基于此进行自定义文本分类,从而为客户提供个性化内容。可以用于客户意见分析,知识管理等多种场景。本解决方案中,Comprehend用于分析出文本中的实体,关键字和情感,便于统计和分析游戏的玩家反馈。更多关于Comprehend的功能请参考:https://docs.aws.amazon.com/zh_cn/comprehend/latest/dg/comprehend-general.html
系统架构
架构图
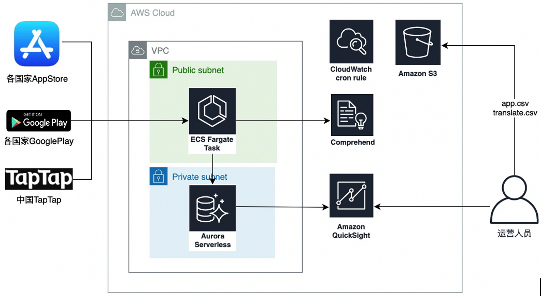
部署说明:
部署前提
- 下载Lambda代码并上传到部署区域的s3桶
- 从Github中下载Lambda 代码
- 上传Lambda 代码到未来部署所在的区域的s3 桶
- 运行aws s3 cp function.zip s3://destbucket/path
- csv文件
- csv文件记录了要进行分析的您的游戏的相关信息,在使用快速部署部署本解决方案之前首先要创建该文件并将其上传到s3上。
- 样例csv 可以点击下载,并基于此进行编辑。

- appname: 支持的平台中的游戏产品名称
- platform:支持的平台名称,如:“AppStore”
- country: 要分析的国家简称,如“us“
- appid:产品在平台的app id:如:1234567890
- 上传后请记录下csv所在的s3的路径。
- VPC
- 请准备一个拥有一个公有子网,一个私有子网的VPC

部署参数:
| 参数类型 | 名称 | 值 | 用途 |
| VPC | VPC | 点击下拉列表选择中的一个VPC | 用于部署Fargate和Aurora Serverless数据库 |
| VPC | publicSubnetA | 点击下拉列表选择VPC中的一个子网 | 用于部署Fargate和Aurora Serverless数据库 |
| VPC | publicSubnetB | 点击下拉列表选择VPC中的一个子网 | 用于部署Fargate和Aurora Serverless数据库 |
| 游戏相关信息 | appkey | 输入appkey.csv文件的S3上的路径 | 通过读取appkey.csv来确定要爬去评论的游戏 |
| S3 | bucketname | 输入appley.csv文件所在的s3桶的名称 | appkey.csv文件所在的桶,用于获取该文件 |
| Aurora | DatabasePassword | 新创建的Aurora的数据库密码 | Aurora 的数据库密码 |
| Aurora | DatabaseUsername | 新创建的Aurora的数据库用户名,默认值为admin | Aurora的数据库用户名 |
| Aurora | DatabaseName | 新创建的Aurora的数据库名称,默认值为review | Aurora的数据库名称 |
快速部署
- 启动CloudFormation
- 点击此出下载模版文件。

点击【下一步】。

- 配置堆栈选项
保持默认值
- 审核堆栈
保持默认值,但请勾选“ 我确认,AWS CloudFormation 可能创建具有自定义名称的IAM 资源。”的单选框。

点击【创建堆栈】。等待大概30 分钟,堆栈创建完成。
QuickSight创建与配置
- 配置QuickSight管理
- 点击“管理QuickSight,”进去管理界面后来到”管理VPC连接“界面。
- 若无“管理QuickSight” 请验证您是QuickSight管理员
- 点击“管理QuickSight,”进去管理界面后来到”管理VPC连接“界面。

-
-
- 若无管理VPC连接界面,请降版本切换至“企业版”
-
-
- 点击“添加VPC连接”,填入相应信息:
- VPC连接名称:您自定义的此连接的名称
- VPC ID:Fargate 运行的VPC ID,点击下拉框选取
- 子网ID:Fargate所在的子网ID,点击下拉框选取
- 安全组ID:该QuickSight网络接口的安全组ID
- 点击“添加VPC连接”,填入相应信息:

-
- 查看QuickSight ENI状态
- 来到相同区域下的EC2——网络接口界面

- 来到相同区域下的EC2——网络接口界面
- 查看QuickSight ENI状态

-
- 找到描述列下面,有“QuickSight”字样的网络接口,是否是绿色的:“in-use”状态
- 若为“in-use”状态,则QuickSight ENI 的状态已经就绪,可以继续下面的操作。
- 更多详细信息请参考:https://docs.aws.amazon.com/zh_cn/quicksight/latest/user/vpc-creating-a-connection-in-quicksight.html
- 找到描述列下面,有“QuickSight”字样的网络接口,是否是绿色的:“in-use”状态

- 创建QuickSight的新的数据集,点击右上角“新数据集”按钮




点击Aurora 创建Aurora数据源,点击后按照之前Cloudformation的数据库的设置输入连接相关参数,点击创建数据源。
进入到table loading 环节 则表明连接已成功,选择“customer-reviews“表,作为数据源。点击“使用自定义SQL”来到数据源编辑界面。此时我们已经成功创建了第一个数据源:“customer-reviews“
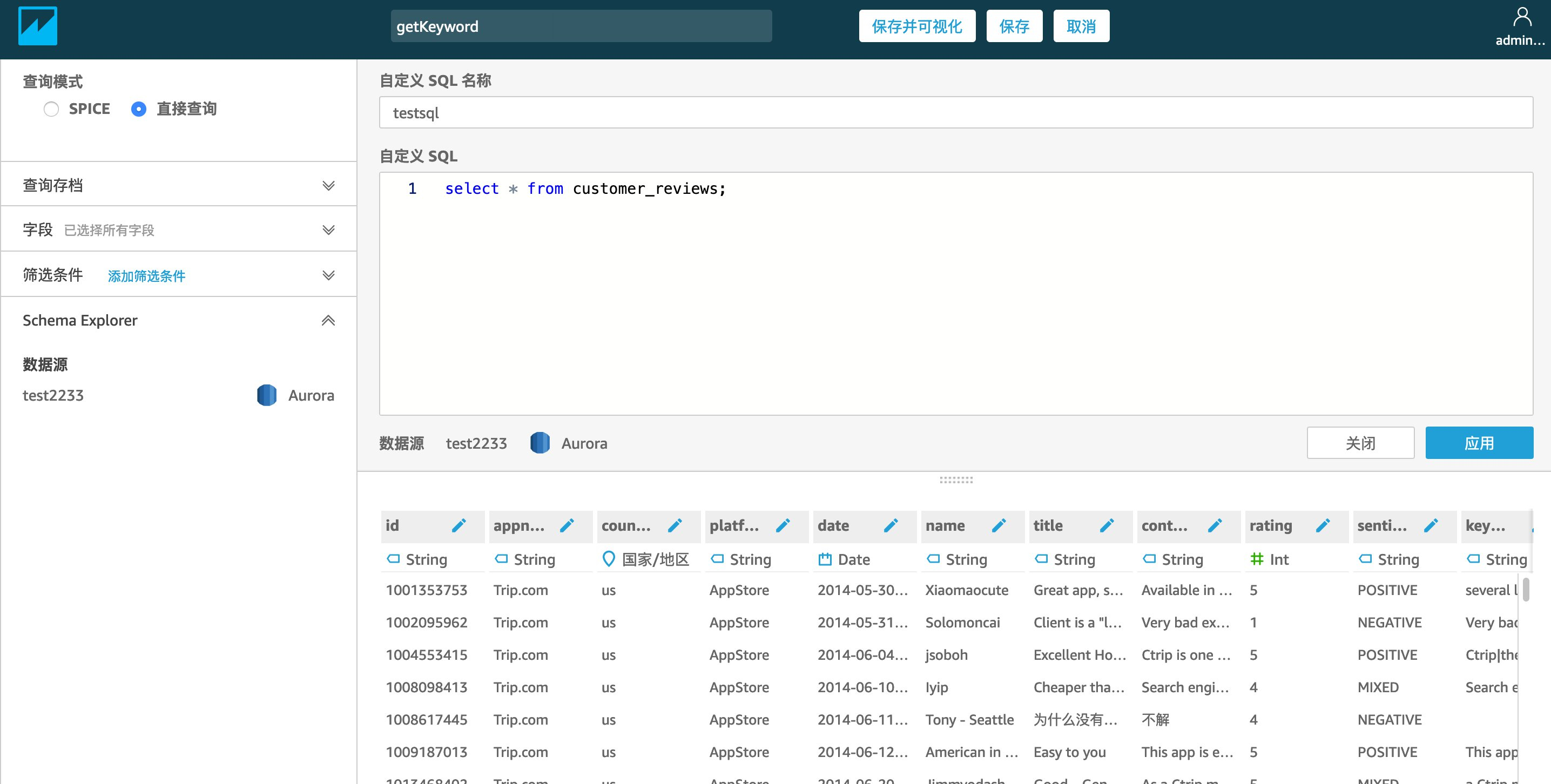
重复上述步骤,在执行到输入SQL中,在SQL框中写入以下SQL语句,生成用于提取分析后的结果的第二个数据集:“keyword”,再点击应用。 经过SQL过滤的新的结果将作为数据源 进行展示。数据源无误后点击“保存并可视化”来到创建图表界面.在此界面中,您可以创建您想要创建的BI报表。
更多可视化表格数据分析请您参考“https://docs.aws.amazon.com/zh_cn/quicksight/latest/user/working-with-visuals.html”

此时我们来到可视化界面,在数据集下拉框我们首先选择“customer_reviews” 作为数据集
- 示例控件创建:




创建参数,参数可以作为全局筛选条件进行数据筛选。比如示例中是按照国家来进行筛选,则进行筛选后显示的均是国家是‘us’的评论数据。设置动态默认值,使下拉列表的选项和数据库中的值关联。
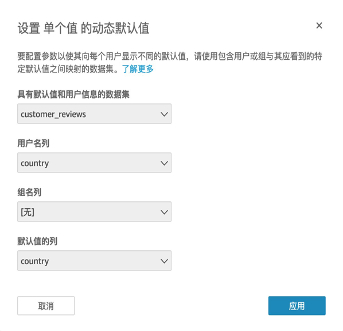

设置相关联的数值的表和列,选择后点击“应用”随后点击“创建”


选择“控件”创建控件,输入显示的控件名称,选择“下拉列表”样式,输入相关联的数据集和列名称,点击添加
此时“视图”界面会显示刚刚创建的筛选控件,并自动关联表格中选中列的数据。



将控件关联筛选:

点击筛选条件进行编辑,以和控件进行关联,点击“应用”
- 示例图标创建:
- 示例图表1:
创建每日新增评论统计,选中date数据,选中折线图图表类型
所示图表中,x轴为各个日期的评论时间,Y轴为相应时间的评论数据条数。

-
- 示例图表2:
查看当前APP在所选国家一共有多少条评论
选择rating
选择auto图表类型

-
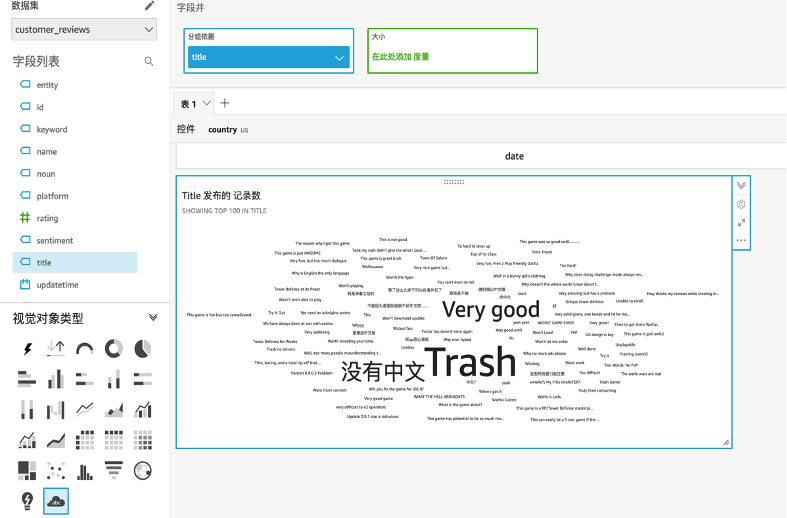
- 示例图表3:
查看当前的评论概览
选择title
选择“词云”图表类型
-
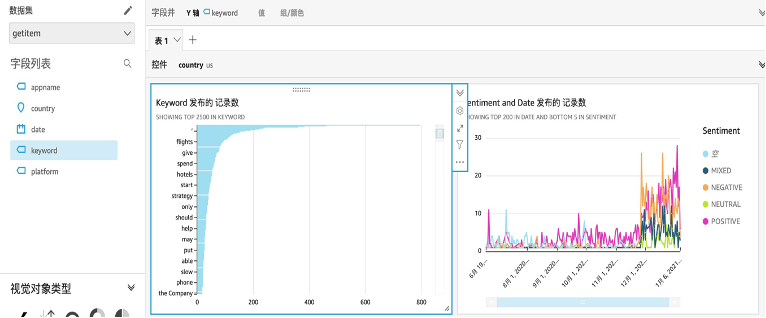
- 示例图标4:
切换数据集,将数据库切换到keyword和词性分析数据集上
选择keyword 选择柱状图 可看到keyword的数量柱状图,
选择sentiment 选择时间折线图,可看到不同类型的评论随时间变化的趋势图
- 发布控制面板:
点击右上角的“共享”点击“发布控制面板”可以将现有的可视化图表发布为控制面板。您可以出于报告目的与其他 Amazon QuickSight 用户共享。控制面板会保留您在发布控制面板时的分析配置,包括筛选、参数、控件和排序顺序等。用于分析的数据不会作为控制面板的一部分捕获。当您查看控制面板时,它将反映分析使用的数据集中的当前数据。


生成的控制面板,如下可以共享给其他人员进行共同操作。
最终可以实现,基于关键字查找评论,查看分析的情感倾向等等操作。

总结

本解决方案利用Comprehend, ECS Fargate,Aurora Serverless为主要组件,构造了基于Comprehend的玩家评论分析方案,借助此解决方案,客户可以查看并分析游戏在GooglePlay和AppStore中的游戏评论,并得到由Comprehend解析出的相关洞见。Comprehend会分析出可每条评论的情感倾向和关键词,帮助游戏开发者第一时间掌握用户反馈,并基于此进行更迭改进。