亚马逊AWS官方博客
使用 Amazon Polly 和 简单 Python 脚本将你的文本转换成 MP3 格式
文本转语音技术可将任何数字文本转换为多媒体体验,让用户能够在处理多任务或进行其他活动时收听新闻、博客文章、甚至是 PDF 文档。借助 Amazon Polly,您可以转换 RSS 源或电子邮件,以音频文件形式存储合成语音。
目前,Amazon Polly 控制台支持粘贴长度不超过 1500 个字符的文本、选择语言和区域以及选择语音。之后,您可以聆听转换后的文本或将其下载为 MP3 文件。此外,您还可以使用 AWS 命令行界面 (AWS CLI) 从 AWS 管理控制台执行转换。
复制少量要试听的文本,然后打开控制台。
1. 在搜索框中键入 Polly。
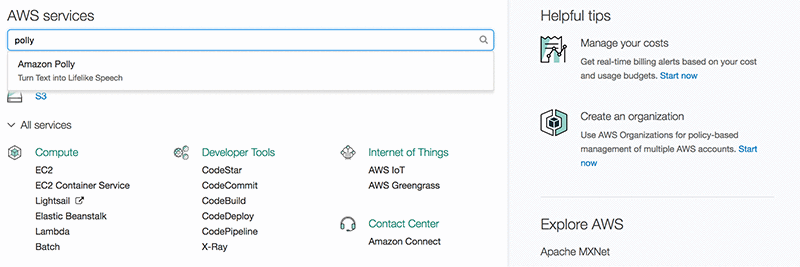
2. 要试用 Amazon Polly 服务,请在 Plain text 选项卡中粘贴文本并聆听输出。

如果要使用 Amazon Polly 将书籍等长格式文本转换为语音,则需要将文本切分成 1500 字符长的数据块。如果 AWS CLI 命令能够接受不限大小的文本文件作为输入并自动转换成 MP3 文件,岂不是更好?
经过快速调查,我发现了两种解决方案:一种是基于 AWS Lambda 和 AWS Batch 的云解决方案,一种是基于 Node.js 的解决方案。第一种解决方案是一个全面的生产系统,要求对 AWS 服务和服务配置有很好的了解。第二种解决方案需要安装 Node.js。我希望找到一种只需极少的配置就能从计算机本地测试这项服务的快捷方法。因此,我决定创建一个简单的 Python 脚本,让我能够输入不限大小的文本文件,并输出一个 mp3 文件。
此脚本依赖 AWS CLI 工具和一个标准 Linux/Unix 命令:“cat”。它的原理很简单:读取 .txt 文件并将其传递给 AWS CLI 命令进行转换。但我发现 MP3 输出文件的句子和段落之间没有停顿。因此,我使用了语音合成标记语言 (SSML) 而不是简单的文本。SSML 是一种具有各种标签的标记语言。例如,要在句子之间加入停顿,可以使用 标记,其中 1s 代表停顿 1 秒。
源代码
# coding: utf-8
import subprocess
import codecs
f = codecs.open("story.txt", encoding='utf-8')
cnt = 0
file_names = ''
for line in f:
rendered = ''
line = line.replace('"', '\\"')
command = 'aws polly synthesize-speech --text-type ssml --output-format "mp3" --voice-id "Salli" --text "{0}" {1}'
if '\r\n' == line:
#A pause after a paragraph
rendered = '<speak><break time= "2s"/></speak>'
else:
#A pause after a sentence
rendered = '<speak><amazon:effect name=\\"drc\\">' + line.strip() + '<break time=\\"1s\\"/></amazon:effect></speak>'
file_name = ' polly_out{0}.mp3'.format(u''.join(str(cnt)).encode('utf-8'))
cnt += 1
command = command.format(rendered.encode('utf-8'), file_name)
file_names += file_name
print command
subprocess.call(command, shell=True)
print file_names
execute_command = 'cat ' + file_names + '>result.mp3'
subprocess.call(execute_command, shell=True)
execute_command = 'rm ' + file_names
print 'Removing temporary files: ' + execute_command
subprocess.call(execute_command, shell=True)此脚本将生成许多 MP3 文件,因为每一行都会导致生成一个 MP3 文件。为了仅获得一个 MP3 文件,我使用 cat 命令 (cat polly_out0.mp3 polly_out1.mp3>result.mp3) 简单地合并这些文件。这样做有一个特点:cat 命令只是将一个文件直接附加到另一个文件末尾,不会为最终的 MP3 文件重新创建元数据。输出的 MP3 文件应该适用于大多数新式音频播放器。
3. 打开一个文本编辑器 (Linux/Unix/MacOS 上可以打开 Nano 或 Vim,Windows 上可以打开“记事本”),键入内容并将文件保存为“story.txt”。

4. 在控制台中键入 python polly.py,将内容文件转换为音频文件。脚本输出可让您跟踪执行过程,不过您也可以将其注释掉。

现在,您可以将刚生成的 MP3 文件上传到 Amazon Music 上并在 Alexa 上播放了!
在本文中,我介绍了如何借助简单的 Python 脚本利用 AWS Polly 服务将文本转换为音频。您可以使用它将任何长度的文本转换为 MP3 文件。此外,还介绍了如何使用 SSML 语言提高语音质量。希望这篇文章可以帮助享受自己的多媒体体验。如果您有任何疑问,请在评论部分留言。
补充阅读
要了解本文介绍的解决方案之外的其他方法,请参阅如何使用 Amazon Polly 和 AWS Batch 制作有声读物。

作者简介
 Dzidas Martinaitis 是 AWS EMEA 的数据科学家。他运用机器学习和数据科学技术从市场趋势中提炼见解,从而更好地了解客户不断变化的需求,在为销售团队提供量身定制的支持时以最佳方式为他们分配资源。工作之余,他还与其他人携手创办了卢森堡数据科学聚会小组。
Dzidas Martinaitis 是 AWS EMEA 的数据科学家。他运用机器学习和数据科学技术从市场趋势中提炼见解,从而更好地了解客户不断变化的需求,在为销售团队提供量身定制的支持时以最佳方式为他们分配资源。工作之余,他还与其他人携手创办了卢森堡数据科学聚会小组。