亚马逊AWS官方博客
将 Apache Airflow 部署到云端
参加技术会议的乐趣之一就是找到知微见著的感觉。例如Apache Airflow 这个项目引起我的关注就是从 AWS re: Invent 大会上不经意间的收获。在我的印象里,大约自2015 年开始的 re:Invent大会,但凡提到机器学习/数据处理平台的架构总会看到那个 Apache Airflow 的图标 ,例如:
- 2017年re:Invent ,Ivy Tech介绍的数据平台架构

- 2018年re:Invent ,Innogy 分享的机器学习与分析平台的架构

- 2019年re:Invent ,Hertz介绍的数据平台架构


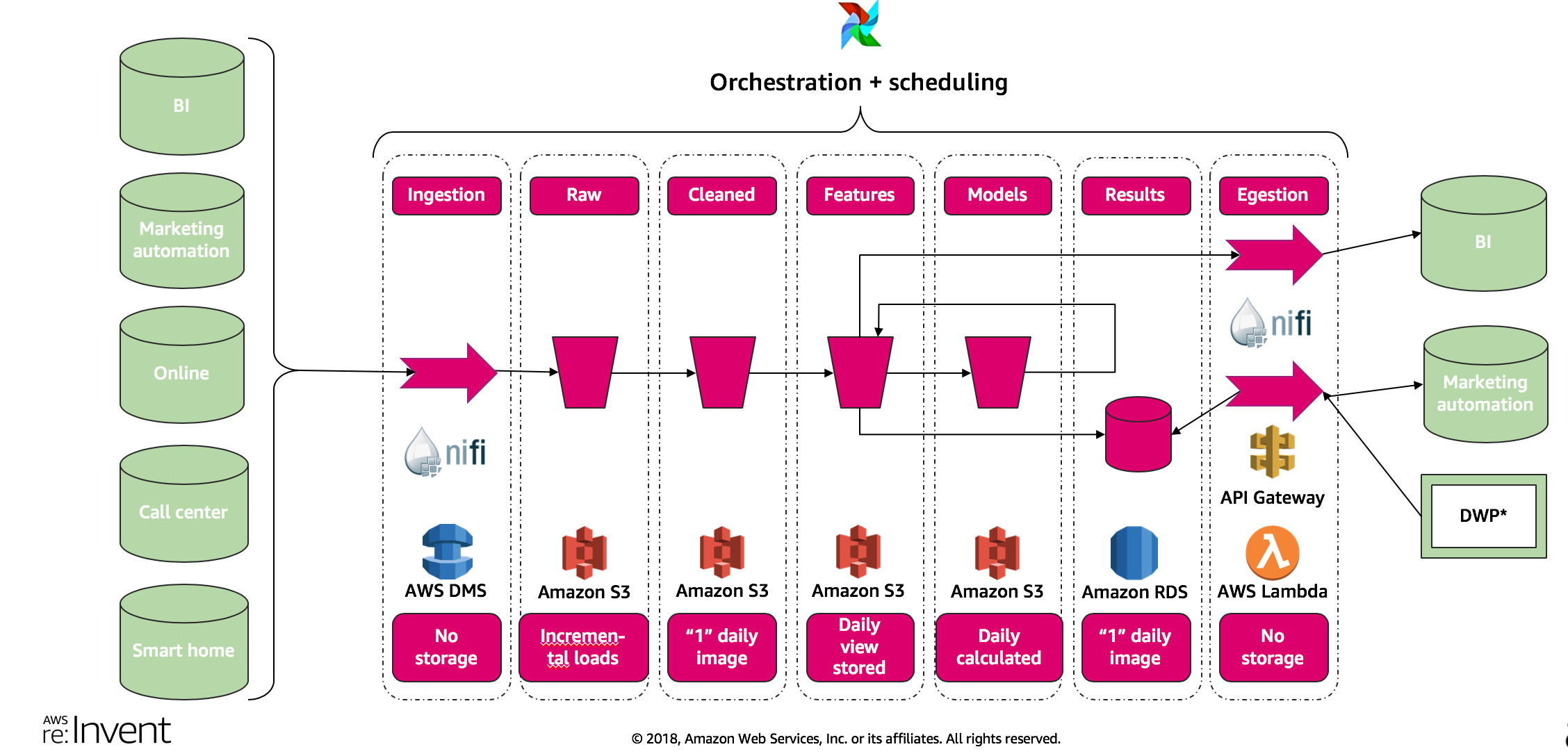

如果我们足够细心就会发现包含有 Apache Airflow 的架构分享还远不仅限于此。这就不免让我心生好奇,这个 Apache Airflow 究竟是何物?部署在云端究竟用哪种方法?
Apache Airflow 究竟是个什么项目?
Apache Airflow 是一项由 Airbnb 在 2014 年 推出的开源项目,其目的是为了管理日益复杂的数据管理工具、脚本和分析工具,提供一个构建批处理工作流的方案。从功能来看,这是一种可扩展的分布式工作流调度系统,允许将工作流建模为有向无环图(DAGs),通过这种方式简化数据管道中各个处理步骤的创建、编排和监控。在现实中,Airflow 的案例已经又了很多。除了在在开篇提到的那些案例,在它的Github 项目Repo 中罗列了346个正式确认的Airflow用户。另外,在它的官网上也有一些案例,例如 –

从实现的角度,Airflow 为开发者提供了使用 Python 语言创建 DAGs (有向无环图) 的可能性。这有助于创建可相互连接和依赖的任务集,用以实现各种工作流的目标。部署成功之后,Airflow 集群可以被重用,以实现自动化的工作流。适用的领域包括了机器学习、数据分析/处理以及各类需要流程化的场景。在这个项目的文档中,对其的设计原则有过这样的一个总结 –
- 动态:Airflow管道是作为代码配置的(Python),允许动态管道生成。 这允许编写动态实例化管道的代码
- 可扩展:轻松定义自己的运算符(operators),执行器(executors)和扩展库,使其适合于环境的抽象级别
- 优雅:Airflow管道简洁明了。 使用功能强大的Jinja模板引擎,将脚本参数化内置到Airflow的核心中
- 可伸缩:Airflow具有模块化架构,并使用消息队列来协调任意数量的Worker。 Airflow可扩展到无穷大

来源:https://airflow.apache.org/index.html
Airflow 体系架构概述
Apache Airflow可以被看作是一个分布式系统。其每个节点都可能执行任何任务。除非显式的配置,否则任务和节点之间不具有关联性。Apache Airflow是“半数据感知”(semi-data aware )的。 这意味着,它不通过管道传播任何数据。但是良好的定义机制,可以使用XComs通过工作流来传播元数据。Airflow记录了已执行任务的状态,报告故障,必要时重试,并允许安排整个管道或其部分以通过回填来执行。
说明:XComs是“交叉通信”(cross-communication)的缩写,是指允许任务交换消息,从而允许更细微的形式的控制和共享状态。XCom主要由键、值和时间戳定义,但也跟踪创建XCom的任务/ DAG等属性。
Airflow由多个部分组成。 并非必须部署所有这些工具(例如,对于Flower和Webserver 可不做部署)。但是在设置和调试系统时,它们都会派上了用场。这些组成部分有以下几种 –
| Flower 与Webserver | 用于监测和与Airflow集群交互的用户前端 |
| Scheduler | 连续轮询DAG并安排任务。 监视执行 |
| Workers | 从队列执行任务,并报告回队列 |
| Shared Filesystem | 在所有群集节点之间同步DAG |
| Queue | 可靠地调度计划任务和任务结果 |
| Metadb | 存储执行历史记录,工作流和其他元数据 |
Executor (执行器)是Airflow 中一个重要的概念。在Airflow中执行器(Executor)是运行任务实例的机制。一旦一个DAG被定义,为了在DAG中执行和完成单个或一组“任务”,需要执行以下操作:
- 在元数据数据库(例如:PostgreSQL)中记录一个DAG中所有的任务以及它们在后台的相应状态(排队、调度、运行、成功、失败等)
- 调度器从元数据库读取数据,检查每个任务的状态,并决定需要完成什么(以及按照什么顺序执行)。这就是执行器的传统作用
- 执行器与调度器密切合作,以确定哪些资源在排队时将实际完成这些任务
Airflow支持多种执行器。当前使用由配置文件的核心部分中的executor选项决定。
执行器之间的差别在于他们拥有资源,以及它们如何选择利用这些资源来分配工作(或者根本不分配工作)。这里有六种常见的执行器 –
| Sequential Executor | 顺序逐个地启动任务 |
| Local Executor | 在本地并行启动任务 |
| Celery Executor | Celery是执行程序首选种类型。实际上,它被用于在多个节点上并行分布处理 |
| Dask Executor | 这种执行器允许Airflow在Python集群Dask中启动不同的任务 |
| Kubernetes Executor | 这种执行器允许Airflow在Kubernetes集群中创建或分组任务。 (注意:该功能要求Airflow最小的版本为1.10) |
| Debug Executor | DebugExecutor设计为调试工具,可以从IDE中使用 |
关于Airflow的应用,我们可以通过这个基本的Airflow管道定义的来了解一下 –
apache-airflow PyPI包只安装启动所需的基本内容。可以根据环境中有用的内容来安装其它的工具包。例如,如果需要连接到Amazon S3,那么就需要通过pip install apache-airflow[s3] 完成扩展包的安装。其它的扩展包还包括了对druid、hdfs、mysql、redis等的支持。
Airflow Web 服务器运行后,可在浏览器中访问 localhost:8080 并通过主页激活示例的 DAG。 Airflow的大多数配置都保存在airflow.cfg文件中。 除此之外,还可以配置
到 LDAP目录的连接、smtp 邮件的配置、Web 服务器的配置、不同 Operator 的配等置。
Airflow 运行在 AWS 之上
Airflow的workers可以基于Celery、Dask Distributed、Apache Mesos或Kubernetes来进行部署。其中Celery是比较常见的选择,因为这是启动和运行Airflow的最直接方法。当然,如果希望使用现代化的容器集群来进行部署也是很好的选择。AWS上的两种可用群集类型是AWS ECS或Kubernetes。其中,Kubernetes集群可以使用AWS托管的Kubernetes服务AWS EKS。此外,很多实践证明AWS ECS使得Airflow部署和管理变得更加容易,而Amazon RDS和Amazon ElastiCache 提供了ProstgreSQL和Redis实例的管理。EFS提供了一个可以在所有的Airflow节点之间共享的公共块存储,从而避免了在集群节点之间需要更复杂的DAGs同步。需要强调的是,这些方法的取舍要取决于我们具体的需求。

“基础架构即代码”是云计算的重要原则之一。对于Airflow的部署而言,完整的基础设施堆栈可以分为4个层次。堆栈的不同的层次在逻辑上是分开的,开发和维护变得更加容易。正如在这张示意图看到的那样,Airflow Service可以有多个实例,因此我们可以将其部署在多个环境中,例如(DEV/TEST/UAT)。这样做的好出是可以在DAG作业上定义完全托管的CI/CD管道。
网络层
网络层是部署的基础部分。不仅因为这是我们能够接触到的基础设施的最底层,还因为我们在这里需要完成整个架构最重要的安全特性。这里最主要的就是VPC,Airflow将在其中独立运行。这个VPC具有2个专用子网和2个公用子网,它们分布在2个可用区当中。具有docker映像的EC2实例将仅部署在私有子网中,因此我们可以避免直接从“外部”进行访问该实例。但是为了不完全隔离服务并实现Internet访问,我们将在公共子网中使用NAT网关。此外,我们将使用公共子网中的一个堡垒主机从公司网络访问该主机提供的服务。堡垒主机未在此层中表示出来。

存储层
在网络层之上就可以部署存储层。存储层伴随Airflow设置的不同而有所不同。尽管很多人都推荐Airflow后端的存储层使用PostgreSQL或者MySQL,而Celery用于后端的存储层则是Redis。AWS RDS 提供了托管的Postgres 以及MySQL服务; Amazon ElastiCache 则提供了托管的Redis 服务。考虑到简化部署以及减少管理的的投入,托管的服务无疑是最好的选择。此外,对数据库进行多可用区(MultiAZ)的部署,可以提供更高级别的存储层的可用性。
集群层
集群层将处理我们需要的基本配置和必要的组件,以便在该层之上运行服务。首先,此层包含堡垒主机,以后可以用作跳转主机来访问端口8080(Airflow 默认端口)和5555(Celery默认端口)。集群对象很容易创建,但自动缩放则是整个基础设施堆栈中最棘手的部分。值得一提的是,实例本身就有具备缩放规则,并且还有一个服务级别的扩展。两者均受AWS CloudWatch Alarms的控制。与此相对应,我们仅需要定义实例级别的扩展策略,服务级别的扩展策略将在“Airflow服务”级别上定义。通过不断监视CPU和内存值,并且随着对系统性能变化的反应,EC2主机的数量相应增加/减少。
在这个架构中,还还可以加入一个参与者,那就是AWS EFS。这是AWS的基于NFSv4协议的网络文件服务。我们将使用此服务在AWS上建立一个通用的共享存储,可用于在其中复制DAG定义文件。
服务层
最顶层的“服务层”将用于部署Airflow服务。正如在上文介绍的那样,可以部署多个服务的实例。在这一层上需要一个应用程序负载平衡器,它将为我们提供对该群集的公共访问点。AWS的Elastic Load Balancing 将被用来扮演这个角色。我们必须配置四个不同的定义:Flow服务(Celery)、Worker、Scheduler以及WebServer。在此TaskDefinition中资源我们指定环境变量,docker cpu、内存资源、日志记录配置等。对于每个任务,基本上使用相同的docker映像,但是对于每个Airflow服务,可以定义不同的初始化脚本。我们不要忘记服务级别扩展策略,它不会依赖实例级别的监测数据,而是检查服务级别的监测结果。因此, Worker容器上的高负载可能会触发一个Worker容器的启动。
结语
坦率的说,在AWS部署Airflow并不是一件简单的事情,需要考虑到很多的细节,尤其是要设计好扩展策略,以及与AWS 服务的整合。也许,最理想的解决方案可能是一个AWS上的Airflow 托管服务。
关于Airflow相信很多人都是用中的百味体会。如果愿意分享与我,可以通过这个邮箱进行联系,lianghon@amazon.com, 谢谢!
