亚马逊AWS官方博客
在中国区 AWS 上使用 Amplify 开发离线应用的使用心得
AWS Amplify简介
AWS Amplify是有AWS提供并维护的一套即可组合使用也可单独使用的工具和服务,能够帮助前端 Web 和移动开发人员构建可扩展的全栈式应用程序。AWS Amplify本身可分为两个部分,第一个部分是前端的开发工具及开发库,目前支持多种前端框架(包括 JavaScript、React、Angular、Vue、Next.js)以及移动平台(包括 Android、iOS、React Native、Ionic、Flutter),能够简化前端与后端aws服务的集成,而第二个部分则是存在于AWS云上的AWS Amplify服务,用于管理和辅助部署在AWS上的后端架构。结合这两个部分的AWS Amplify可以缩短销售就绪时间,轻松实现前后端的无缝连接。
下图展示了一个标准的使用amplify进行开发的流程

关于AWS Amplify的具体介绍可以参看: https://aws.amazon.com/cn/amplify/
而支持前端或移动端的amplify库本身是GitHub 上发展速度排名第五的开源项目,下载量也已达到数百万,并且拥有着成熟的社区支持。对于前端或客户端的开发者而言,Amplify是可靠而又易用的开发工具。
AWS Amplify在中国区的使用
AWS Amplify在AWS Global的使用已经非常普遍了,但与之相对的,其在AWS中国区的使用和推广仍处在比较滞后的阶段,究其原因主要在于AWS Amplify在中国区所能提供的功能仍然不完整。在上一节中提到amplify主要由两部分组成,分别支持前端与后端,来实现前后端的无缝连接,然而在AWS中国区,实现辅助后端部署的那一部分功能并未上线(受制于AWS Cognito等一些功能缺失的限制),Amplify在中国区的使用上仅限于支持前端应用。使用Amplify的开发工具及开发库仍然能够帮助中国的开发者实现迅速集成AWS后端服务的功能,不过遗憾的是开发者没有办法直接使用Amplify的工具去部署对接前端的后端的架构,因此也造成了Amplify的易用性在中国区的大大减弱。

如上图所示,跟aws global比起来,在中国区使用amplify的开发流程里,无法直接使用amplify的功能进行后端开发,那么在中国区我们就需要一个能够便捷的替代amplify来部署以及开发后端的工具。而在这里我推荐并且在接下来的篇幅里也会使用到的工具叫做serverless framework. Serverless 是一种开源的自动部署云上资源的工具,与aws原生的AWS SAM类似,也是可以便捷的通过YAML配置文件部署无服务架构,并且serverless也原生支持aws cloudformation的template去部署资源。依托良好的社区支持,serverless可以安装多种plugin来扩展其功能,也正是因为serverless的丰富扩展及支持原生cloudformation template的特点,我在这里选择使用serverless来替代amplify来部署后端。
什么是离线应用
离线应用是指通过离线缓存技术,让资源在第一次被加载后缓存在本地,下次访问它时就直接返回本地的文件,就算没有网络连接。离线应用有以下优点:
- 在没有网络的情况下也能打开网页。
- 由于部分被缓存的资源直接从本地加载,对用户来说可以加速网页加载速度,对网站运营者来说可以减少服务器压力以及传输流量费用。
而amplify的前端开发库里包含了一个叫做amplify datastore的组件,能够集成后端的aws appsync服务原生提供离线缓存技术,为开发离线应用大大简化了开发工作量。
Amplify datastore的工作原理
作为Amplify前端开发库里的一个组件,开发者能够非常方便的建立一个存在于客户端缓存中的离线数据库用于储存应用的数据,并且在网络连接通畅的情况下,会自动将本地的缓存数据通过aws appsync服务同步到云上的数据库上去。

如上图所示,当开发者创建一个amplify datastore的实例以后,可以直接通过调用DataStore API的方式将数据做增删改查的操作,而amplify datastore的实例内置的Storage Engine又会通过Storage Adapter将增删改查的操作转化为缓存数据库的操作语句,目前storage adapter默认支持SQLite和indexedDB,不过因为datastore是开源项目的一部分,开发者也可以根据自己的意愿更换storage adapter来支持其他形式的轻量级数据库(例如NoSQL的NeDB等),而amplify datastore里面预装的是Indexdb。storage engine的另外一个功能便是内置的Sync Engine,这个sync engine能够双向同步客户端与后端数据库之间的增删改。并且这个sync engine还会将由于网络原因无法及时同步的增删改放在队列中,直到网络连接通畅时再及时同步。
Sync Engine还有一个auto merge的功能,因为离线数据有可能会出现与后端数据库不匹配的状况(脏数据),那么Sync Engine支持通过设置的不同规则来自动merge不匹配数据,详情可参考:https://docs.amplify.aws/lib/datastore/how-it-works/q/platform/js/#conflict-resolution
Amplify开发离线应用的架构
在AWS上开发离线应用的架构相对简单,前端使用amplify组件配合前端框架,而后端则使用aws appsync来提供GraphQL的接口,将数据打入到aws dynamodb当中。
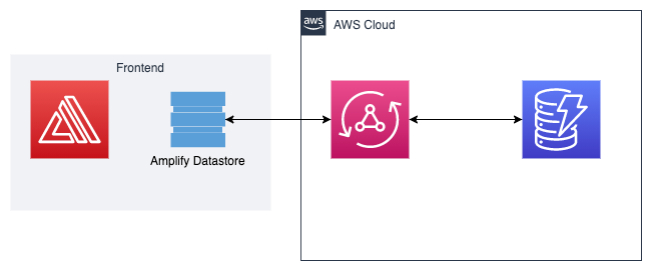
Appsync作为一种提供GraphQL的服务,相比传统的RESTful API,能够极大的提高索引效率,以更少的requests来获取多层级的数据,并且GraphQL支持subscription动作,能够使server端以主动推送的方式,将更新的数据更加及时的推送给前端应用。
而aws dynamodb作为aws自研的一种云原生的NoSQL数据库能够以低延迟,高并发的优势满足现代前端应用对响应时间及可靠性的高要求。
开发环境搭建
整个架构的开发会依赖于以下几个软件工具包:
- AWS CLI,这是aws提供的一种命令行工具,能够便捷的调用aws的服务api
- NodeJS,用于本地测试前端应用
- VUE以及VUE CLI,一种简单的前端JS架构,在这个演示里将用VUE进行前端的开发
- Serverless,之前介绍过的部署后端的工具
- Amplify CLI,辅助前端应用使用amplify库的命令行工具 (注意在安装过程中,无需执行amplify configure指令,会在后续步骤中根据AWS profile进行设置)
首先建立一个项目dir,并且创建本地git,用于版本控制:
然后我们可以开始使用vue cli来创建一个前端开发框架:
由于vue cli会自动安装很多依赖库,所以先提前将node_modules写入.gitignore能够防止git去track过多的安装依赖包。
然后我们使用serverless再创建一个后端的boilerplate:
在这里我们使用sls(serverless)指令create来创建一个boilerplate,虽然我们使用了aws-python3 作为-t 选项,但是实际上我们可以使用任意的aws template,因为我们并不会部署Python3的aws lambda function。最后一条指令是给我们本地的serverless项目安装一个叫做serverless-appsync-plugin的扩展,这个扩展在后面也会极大的简化我们部署后端appsync时所需的代码。整个过程如下图:

目前我们已经基本创建完了项目基本的框架,我们现在的项目dir应该如下图所示:

为方便后面git去正确的track repo,推荐将最外层的.gitignore使用以下定义:
前端应用的开发
初始化amplify项目
在这个演示里,我会使用vue来搭建一个简单的web前端,这个前端会是一个简单的Todo-list页面。首先我们回到frontend的dir,然后用amplify cli来初始化这个项目:
cd frontend
amplify init
在进入到amplify init界面以后根据自己的环境选择相应的选项:
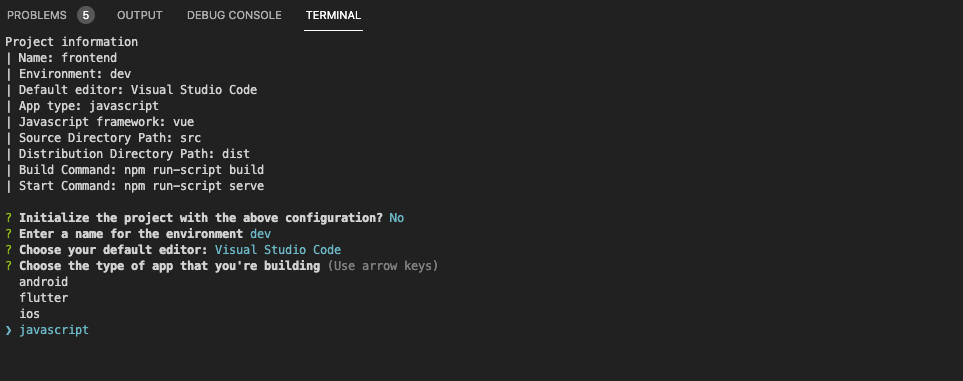
在这里我们需要选择javascript作为前端开发类型,其他的接受默认配置即可,不过在选择authentication method的时候(如下图),最好选择profile

然后amplify cli 会自动读取当前环境里面的不同 profile,这些 profile 来自于aws cli的配置,具体aws cli配置profile的方法可以参考:https://docs.amazonaws.cn/en_us/cli/latest/userguide/cli-configure-profiles.html,而这个profile请务必确保有cloudformation, s3以及iam的权限,因为在后面的命令中,将会部署部分资源。
选择自己对应的 profile 即可,然后 amplify cli 会使用对应 profile 的权限去使用 cloudformation 去部署一些 amplify 相关的资源
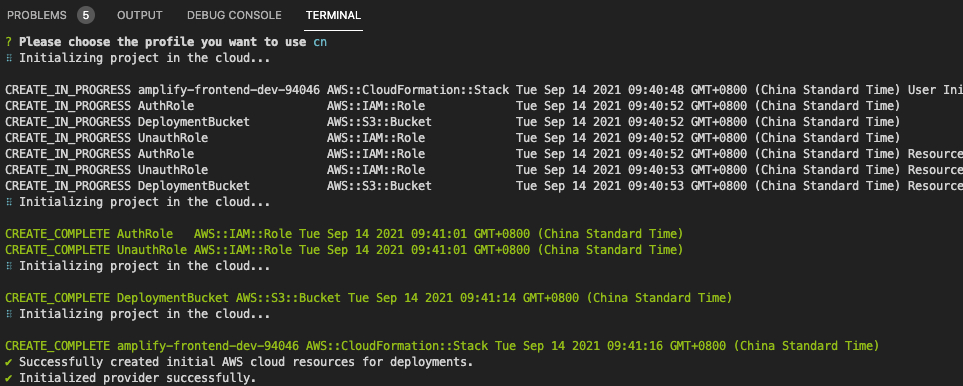
实际上这里amplify cli自动部署的资源我们后面并不会用上,因为刚刚这一步在后端所部署的资源实际上是为aws amplify服务部署后端准备的,但是由于我之前提到的一些原因,我们并无法使用amplify push的指令去部署后端,所以那些部署的资源不会用上,用户可以自己去cloudformation的控制台找到相关的stack并将这些资源删去。
那么既然我们不会用上,又为什么要执行这一步呢?我们这个时候如果查看一下当前frontend的dir,会发现有一个新的命名为amplify的dir出现(如下图所示)
这个amplify里面实际上会包含一些之后会用到的部署后端的cloudformation代码,我们虽然无法直接使用amplify cli中的amplify push指令去部署后端,但是amplify cli本身的基本原理实际上就是产生cloudformation的部署代码,然后利用cloudformation去部署的,而在之后我们将使用到的后端部署工具 — serverless将复用这里自动产生的部分代码来部署相应的后端。
接下来我们需要安装aws amplify库到我们的前端依赖库(node_modules)内
npm install amplify
如果习惯使用yarn,也可以使用一下命令
yarn add aws-amplify
配置前端Amplify实例
接下来我们进入到frontend/src/main.js文件,将原来的内容替换成以下代码:

这样我们就完成了amplify实例的基本配置,这里的‘./aws-exports’是一个由amplify cli自动产生的文件,里面将用来储存前端链接后端的时需要用到的连接配置,在之后的操作中我们会在部署后端时反复修改这个文件。
利用amplify自动生成连接后端代码
amplify cli其实包含了很多辅助代码开发的指令,虽然在中国区受到一些限制,但是大部分的指令仍然能够正常使用。在我目前的测试中amplify configure以及amplify push这两个指令由于需要后端aws amplify服务的支持而无法在中国区使用,不过其他的指令暂时并未发现问题。接下来我们将会使用amplify add api的指令来自动生成一些代码:

在这里我们需要生成的是GraphQL,而API name可以任意定义,而authorization type我们在这里使用API key,其他内容按照上图,在advanced settings里面,我们选择Yes, I want to make some additional changes.
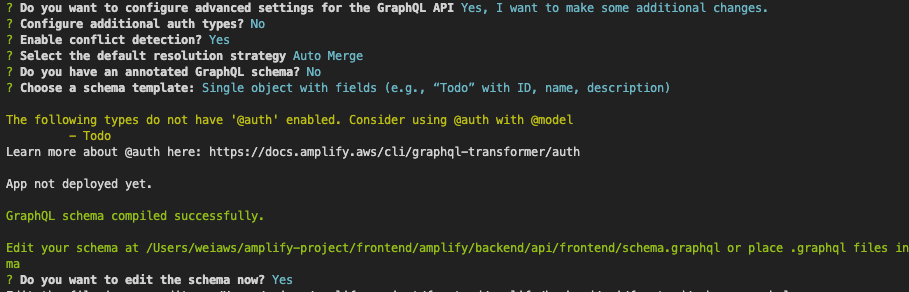 之后请选择上图中所示的选项。在完成之后,如果我们这时查看frontend/amplify/backend/api/frontend/build的目录,就会发现自动产生了一些cloudformation部署代码,而这些代码将在后面利用serverless部署后端时起到至关重要的作用。
之后请选择上图中所示的选项。在完成之后,如果我们这时查看frontend/amplify/backend/api/frontend/build的目录,就会发现自动产生了一些cloudformation部署代码,而这些代码将在后面利用serverless部署后端时起到至关重要的作用。
我们需要用到的下一条指令是
,请确保在frontend目录下执行这个指令。

使用上图所示的选项,amplify cli将会自动产生一个./src/graphql的目录,如果熟悉graphql,会在里面发现其实这个目录下包含了graphql的标准执行语句。在有了graphql的执行语句以后,我们需要真正的能够让javascript执行的model,来让javascript直到怎样去执行这些graphql的语句,而这个model的代码生成我们也可以用amplify cli来代劳,直接执行amplify codegen models,如下图所示。

这是会发现frontend/src目录下又多了一个models的目录,查看这个models目录下的index.js文件,就会发现这个models会export一个Todo的对象,而这个Todo对象含有所有可执行的graphql的语句。
然后我们再进入到frontend/src/App.vue文件,将内容替换为以下代码:
在以上代码里可以看到Datastore的几个常用的method,在从aws-amplify包中引入Datastore之后,我使用到了四个method,首先就是Datastore.save()以及Datastore.query(),这两个method就是对应的对datastore的增和查的两种操作,详细资料可以参看:https://docs.amplify.aws/lib/datastore/data-access/q/platform/js/
其实Datastore还有很多其他的操作,在这里由于篇幅原因就不做详细介绍,如果感兴趣,可以对照文档增加相应的功能。
另外一个看起来较为复杂的method就是在最后subscribe()里面用到的Datastore.observe().subscribe(),这个method就是用来实时同步本地数据及云上数据库的,详细介绍可参看:https://docs.amplify.aws/lib/datastore/real-time/q/platform/js/
最后还有一个比较简单的method,Datastore.clear(),这个是用来一键清除本地cache的所有数据内容的。
至此我们基本上完成了前端的代码编写。
使用serverless开发后端架构
使用serverless appsync plugin
Serverless依靠着活跃的开源社区有很多有趣方便的扩展plugins,而针对在云上部署appsync,也有方便易用的plugin,关于这个plugin的详细信息可以查看https://github.com/sid88in/serverless-appsync-plugin
这个plugin可以通过简化的yaml配置来实现部署复杂schema结构的appsync api,首先我们回到项目的根目录,然后cd到backend的目录下,将这个目录下的serverless.yaml文件替换成以下内容(请将profile对应的名称改为自己aws cli配置的profile):
在以上的serverless的配置文件里,我们可以看到主要部署三种资源,一个是appsync的api,一个是作为数据源的dynamodb,还有一个是用于记录version的另外一个dynamodb (Delta Table),由于我们需要使用到auto merge的功能来处理客户端本地数据库与云上数据库的conflict,所以我们需要用到这个Delta Table来储存数据版本,详细关于这一点的介绍可以参考:https://docs.aws.amazon.com/appsync/latest/devguide/conflict-detection-and-sync.html
移植amplify产生的后端代码
接下来我们需要开始移植一些之前在前端用amplify产生的一些后端部署代码,主要有两个,一个是graphql的schema文件,还有一个是对应的resolver文件,如下图所示,首先我们需要在backend目录下创建一个mapping-templates目录,将 frontend/amplify/backend/api/frontend/build/resolvers/目录下的所有内容全部移到backend/mapping-templates的目录下,然后将 frontend/amplify/backend/api/frontend/build/schema.graphql 拷贝为 backend/schema.graphql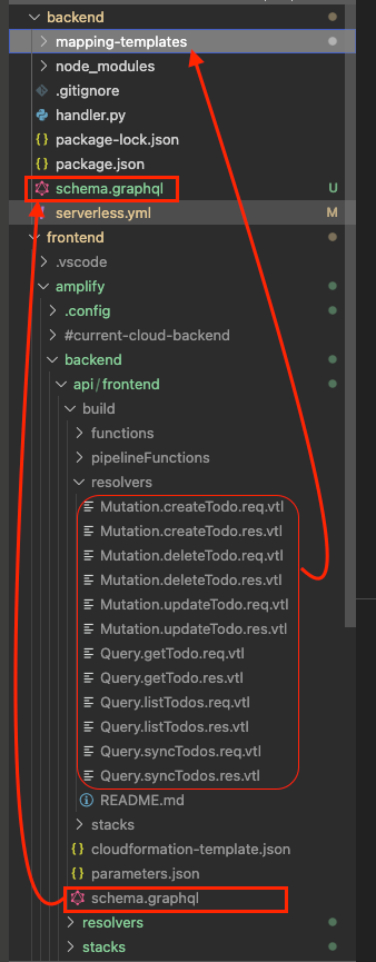
至此我们的后端部署代码就完成了,现在我们可以在 backend/目录下执行 sls deploy 指令,appsync api, dynamodb 等后端资源就会自动部署到我们 profile 对应的 account 上,此时只需等待指令执行完成,如果一切顺利,我们会得到以下结果:

此时我们需要记下上图中highlight出来的部分,一个是 api key,还有一个是 endpoint url。将这两个值记下来备用。
修改前端 aws-exports.js 文件来链接对应的后端
回到前端目录,我们现在需要去更改 frontend/src/aws-exports.js 文件
将文件更改为以下内容,注意将标注出来的<API ENDPOINT URL>以及<API KEY>替换为之前记录下来的那两个值:
当我们完成这个值的替换以后,就意味着此时我们的前端就能够使用 api key 来直接向我们刚刚部署的后端appsync api 发送请求了。
测试离线应用— Todo list
我们可以现在启动我们的 todo list 的网页应用,只需在frontend/目录下执行npm run serve即可
现在我们用浏览器(推荐使用Chrome)用普通(New Window)和隐私(New Incognito Window)分别打开http://localhost:8080,通过使用两种不同的Window我们可以确保两个浏览器窗口不共享缓存。
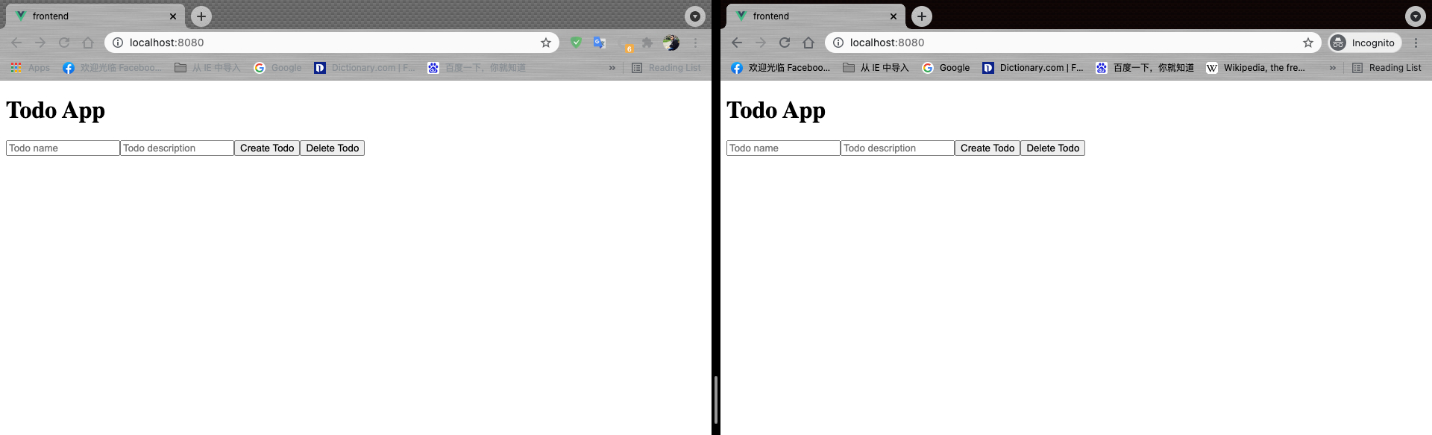
我们如果在其中一个窗口里面的开始输入一些随机的值会发现另外一个窗口也会同步出现这些值,如下所示
此时是在有网环境下实现的多客户端与云上数据同步,接下来我们会断掉其中一个客户端的网络连接,然后再看效果,而浏览器中是可以通过浏览器控制台来断掉网络的。首先打开浏览器控制台(可以右键点击浏览器内任意一处,然后点击inspect或‘查看’来打开浏览器控制台),然后选择网络(Network),点击下图中红色方框标注的选项,然后选择离线(offline)

在通过以上方法将其中一个 window 隔绝网络连接以后,我们可以继续输入一些值到 Todo list 里面去,此时会发现另外一个窗口不再同步,毕竟在网络隔绝以后,客户端的新数据无法上传上云,自然导致另外一个客户端也无法从云上获取新数据,但是在我们将网络的选项从‘Offline’再次变回 ‘No throttling’ 以后,会看见新的数据又再次同步到了所有的客户端:
最后我们再查看一下后端的数据库 dynamodb,我们可以进入到对应账号的 dynamodb 的控制台,选择一个叫做 ‘TestTableAppsyncDeployment’ 的表,查看其内容,会看见以下截屏

这个表内存的数据便是来自于刚才前端的输入。
总结
以上的演示展示了使用amplify开发离线应用的一些基本功能,虽然坦白来说与aws global比起来aws cn确实无法直接使用amplify来部署后端,但通过一些其他的工具再加上复用一些amplify cli自动产生的一些后端部署代码,我们仍然能够较为轻松的实现在中国区使用amplify开发前后端。
Amplify本身就是一个非常优秀的开源前端库,能够高效的帮助前端开发者实现与后端AWS云上架构的无缝连接,而在本篇文章里介绍了amplify 另外一个纯前端的组件,datastore,这个组件默认会自带一个IndexedDB直接在客户端的缓存中储存数据(如下所示),通过这只能够客户端缓存,并与云上通过GraphQL进行数据同步的方式可以极大的优化前端应用的性能,降低延迟,并且增强可靠性。

本文实际只是非常概括的展示了少数几个datastore的功能,不过最重要的设计逻辑已经完整的展现出来了,后续期待会有更多相关的探索来利用这种设计逻辑实现离线应用的开发。
引用
- https://docs.amplify.aws/lib/datastore/how-it-works/q/platform/js/#model-data-locally
- https://aws.amazon.com/cn/amplify/
- https://webpack.wuhaolin.cn/3%E5%AE%9E%E6%88%98/3-14%E6%9E%84%E5%BB%BA%E7%A6%BB%E7%BA%BF%E5%BA%94%E7%94%A8.html
- https://docs.aws.amazon.com/appsync/latest/devguide/conflict-detection-and-sync.html