亚马逊AWS官方博客
在 Amazon sagemaker 上微调与部署 BioBERT 模型
BioBERT是一种生物医学语言表示模型,常用于生物医学中的命名实体识别、关系提取、问答等生物医学文本挖掘任务。Nvidia NGC Catalog 是一套GPU优化的可用于人工智能,高性能计算以及数据分析软件集,包含了丰富的预训练模型,其中有 tensorflow BioBERT 预训练模型 (https://ngc.nvidia.com/catalog/resources/nvidia:biobert_for_tensorflow/quickStartGuide) Amazon SageMaker 是一项完全托管的服务,可以帮助开发人员和数据科学家快速构建、训练和部署机器学习 (ML) 模型。SageMaker 完全消除了机器学习过程中每个步骤的繁重工作,让开发高质量模型变得更加轻松。在这篇blog中,我们将探索如何让Nvidia NGC BioBERT 预训练模型在 Amazon SageMaker 上 finetune 与部署。
首先打开Amazon sagemaker 控制界面,点击【创建笔记本实例】

输入【笔记本实例名称】,选择适当的笔记本实例类型

在 IAM 角色选项上选择【创建新角色】

点击【创建笔记本实例】创建 notebook

当笔记本实例状态变成 InService 后,点击【打开 JupyterLab】
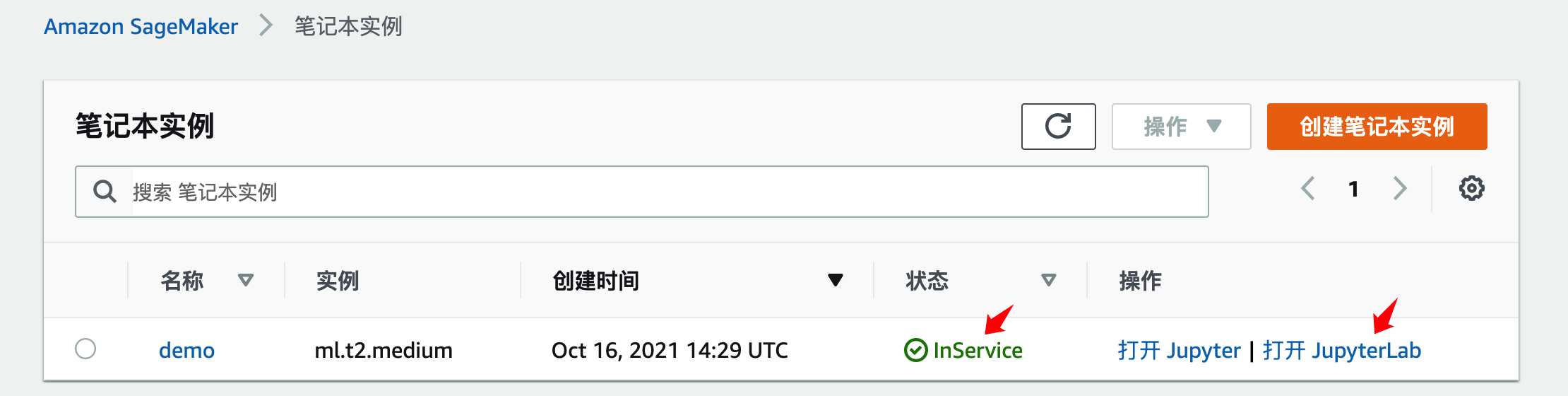
在弹出的 jupyter 页面,依次选择 File – New – Terminal,进入 Terminal 界面并从 Git 获取脚本,以下脚本来源于 https://github.com/NVIDIA/DeepLearningExamples/tree/master/TensorFlow/LanguageModeling/BERT


sh-4.2$ cd SageMaker/
sh-4.2$ git clone https://github.com/aws-samples/ngc-biobert-on-sagemaker
Git克隆完毕后,打开目录 sagemaker-Nvidia-NGC-biobert,并双击打开文件 run_ner.py

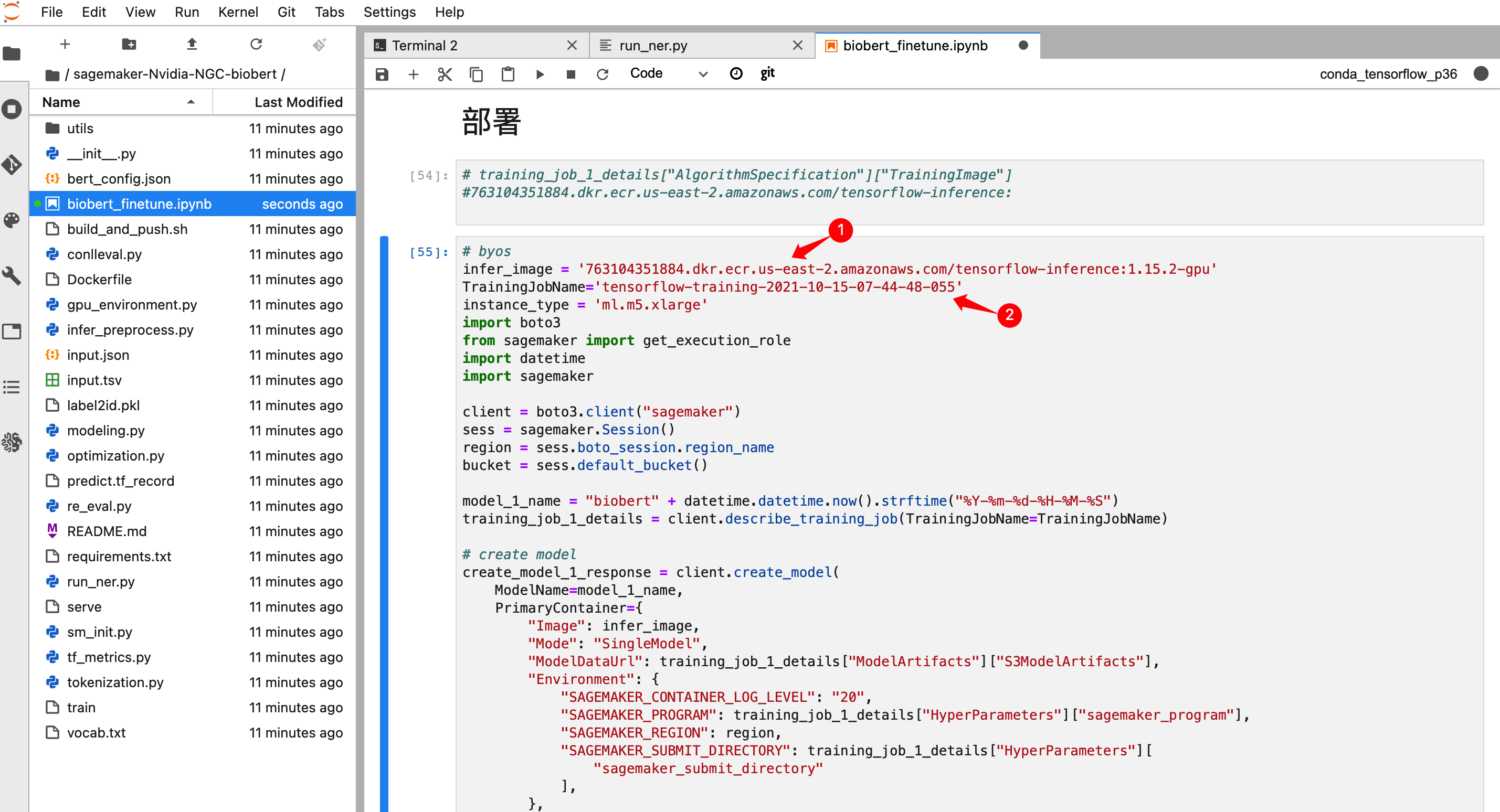
可以看到,该文件使用tf.flags进行传参,参数有task_name,data_dir,output_dir,bert_config_file,do_train,do_eval,do_predict 等。训练支持horovod 进行分布式训练。找到biobert_finetune.ipynb,双击打开,并在右上角选择 conda_tensorflow_p36

在第一行,我们验证了conda 环境下有对应的 tensorflow 框架。随后以 json 格式定义超参。

在上面脚本中,我们启用了了 MPI 分布框架,定义run_ner.py为entry_point,并指定了对应的运行环境与实例配置。注意:在执行estimator.fit() 操作时,需要指定对应的数据位置。原数据位于 https://d13loqfldp8rtf.cloudfront.net/data.zip 我们可以在 jupyter 终端中调用 wget https://d13loqfldp8rtf.cloudfront.net/data.zip,解压后上传到该 region 所在的 S3 存储桶,然后替换上图中的S3路径 s3://sagemaker-us-east-2-310850127430/biobertner/ 数据在S3 路径下的目录结构如下图所示:

触发 estimator.fit() 之后,我们可以在控制台获得训练的任务名称。

待训练完成之后,我们需要将脚步中的 TrainingJobName 修改成上图中的任务名称。如果你不是在 us-east-2上训练,同时还需要将us-east-2 修改成对应的region。例如东京 region 是 ap-northeast-1
这一步会输出 EndpointConfigArn

接下来我们生成模型,推理 endpoint 配置与封装 endpoint。
这里需要将 endpoint_config_1_name 修改成上一步获得的EndpointConfigArn

在生成模型调用 client.create_model 接口时,我们会调用之前 TrainingJob 的 metadata 获取在S3上的训练结果。具体关于上述 api 接口需要录入的参数,详见https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/sagemaker.html

在输出InService后,在 SageMaker 主控制台Inference 下会看到对应endpoint信息。

接下来运行 Infer下的代码,调用 boto3 sagemaker-runtime 类可以显示推理结果。

在这个过程中,我们对于 NVIDIA/DeepLearningExamples 这一 github repository 下的代码改动量非常小,只需要对于源码中 data_dir,output_dir等路径变量进行修正,并补充工程化过程中的逻辑和配置代码即可。
本文讲解了如何使用 Amazon SageMaker 运行基于 Nvidia NGC 的 biobert finetune 与模型部署,最终暴露出来 api 调用接口来供终端用户使用。同时,本文展示了如何把一个基于已有的 tensorflow,horovod 框架的分布式项目快速运行到 Amazon SageMaker 上,并利用亚马逊的机器学习平台快速实现本地机器学习工程化,加速机器学习项目的架构优化与落地。