亚马逊AWS官方博客
Thomson Reuters 如何利用 Amazon SageMaker 加快自然语言处理解决方案的研究和开发
客户的挑战
TR 的研发团队需要快速安全地进行迭代。团队成员已经在开发问答解决方案方面拥有丰富的专业知识,无论是通过浅层算法的专用特征工程还是基于神经的无特征解决方案。他们在开发为 Westlaw Edge(法律)和 Checkpoint Edge(税务)提供支持的技术方面发挥了关键作用,这是 TR 的两款广受好评的产品。这每一个项目都需要 15 至 18 个月的大量研发工作,并且已经达到了卓越的性能水平。对于 MRC,研究团队决定用 BERT 及其几种变体对 TR 的两组数据(一组来自法律领域,另一组来自税务领域)进行试验。
法律训练语料库由成千上万个经过编辑审查的问题组成。每个问题都与简短、切中要害的文字摘要形式的几个可能答案进行了比较。这些摘要是精心策划的编辑材料,摘自数十年来的法律案例,最终形成了一套从数千万个文本摘要提取的数十万个问答 (QA) 对组成的候选问答训练集。税务语料库由 60,000 多份关于美国联邦税法的经过编辑策划的文档组成,其中包含数千个问题和成千上万的问答对。
如果没有先进的计算能力,就不可能根据这些数据集进行模型预训练和微调。购买这些计算资源通常需要大量前期投资和较长的交货周期。对于可能会或可能不会成为产品的研究思路来说,很难证明成本如此高昂的实验是合理的。
为什么选择 AWS 和 Amazon SageMaker?
TR 选择 Amazon SageMaker 作为此项目的机器学习 (ML) 服务。Amazon SageMaker 是用于大规模构建、训练、调整和部署 ML 模型的综合管理服务。TR 决定选择 Amazon SageMaker 的关键因素之一是采用随用随付记帐的托管式服务可带来好处。Amazon SageMaker 让 TR 决定要运行多少次实验,并帮助控制训练成本。更重要的是,训练作业完成后,团队不再为他们使用的 GPU 实例支付费用。与管理自己的训练资源相比,这可以节省大量成本,从而降低服务器利用率。研究团队可以根据需要启动尽可能多的实例,并让框架负责在完成长期运行的实验后关闭这些实验。这样就可以大规模实现快速原型设计。
此外,Amazon SageMaker 还具有内置功能,可以使用托管 Spot 实例,这在某些情况下可将训练成本降低 50% 以上。对于在大量专有数据集上使用像 BERT 这样的模型进行的一些大型自然语言处理 (NLP) 实验,训练时间以天甚至数周为单位进行衡量,所涉及的硬件是昂贵的 GPU。一个实验可能就要花费几千美元。借助 Amazon SageMaker 进行托管 Spot 训练,帮助 TR 将训练成本平均降低 40-50%。与自行管理的训练相比,Amazon SageMaker 还提供了一整套内置的安全功能。这为团队节省了在自行管理的机器学习 (ML) 基础架构上所需的无数小时编码时间。
在他们启动训练作业后,TR 可以在 Amazon SageMaker 控制台中轻松地监测它们。团队可以利用日志记录和硬件利用率计量工具快速了解其作业状态。例如,他们可以确保训练损失按预期发展,并查看分配的 GPU 的利用情况如何。
Amazon SageMaker 让 TR 可以轻松访问先进的底层 GPU 基础架构,而无需配置自己的基础架构或承担管理一组服务器、其安全状况和修补级别的负担。随着以后可以使用更快、更便宜的 GPU 实例,TR 可以通过简单的配置更改来使用新类型,从而使用这些实例来降低成本和训练时间。在这个项目中,团队能够根据其特定需求轻松地对 P2、P3 和 G4 系列的实例进行实验。AWS 还为 TR 提供了丰富的机器学习 (ML) 服务、经济高效的定价选项、精细的安全控制和技术支持。
解决方案概览
客户在推动社会向前发展的复杂领域(法律、税务、合规、政府和媒体)运营,并且随着法规和技术颠覆每个行业,客户面临着日益复杂的问题。TR 帮助他们重塑工作方式。TR 希望使用 MRC 提供比以前依赖手动特征工程的模型更好的自然语言搜索。
TR 研究团队正在开发的基于 Bert 的 MRC 模型在压缩数据超过几十 GB 的文本数据集上运行。TR 首选的深度学习框架是 TensorFlow 和 PyTorch。该团队使用 GPU 实例进行耗时的神经网络训练作业,运行时间从几十分钟到几天不等。
MRC 团队已经试验了 BERT 的许多变体。最初从具有 12 层堆叠式变换编码器、12 个注意力头和 1 亿个参数的基本模型开始,直至具有 24 层、16 个头和 3 亿个参数的大型模型。最大容量为 32 GB RAM 的 V100 GPU 在训练最大的型号变体方面发挥了重要作用。该团队将问答问题归结为二进制分类任务。每个问答对都由一组主题专家 (SME) 进行评分,分配四个不同的等级之一:A、C、D 和 F,其中 A 表示完美答案,F 表示完全错误的错误答案。每个问答对的评分等级都会转换为数字,取各个评分者的平均值,然后进行二进制化。
由于每个问答系统都是针对特定领域的,因此研究小组使用迁移学习和领域适应技术,在不同子领域(例如,法律不是单一领域)实现这种能力。TR 使用 Amazon SageMaker 对其 BERT 模型进行语言模型的预训练和微调。与可用的本地硬件相比,Amazon SageMaker P3 实例将微调作业的训练时间从数小时缩短至不到 1 小时。针对特定领域语料库的 BERT 预训练从预估的几周缩短至只需几天。如果没有 Amazon SageMaker 大幅节省的时间和成本,TR 研究团队可能无法完成此项目所需的大量实验。借助 Amazon SageMaker,他们取得了突破,推动其应用程序作出了关键改进,让用户能够更快、更准确地进行搜索。
对于推理,TR 使用 Amazon SageMaker 批量转换函数对大量测试样本进行模型评分。当模型性能测试令人满意时,Amazon SageMaker 托管主机实现了实时推理。TR 正在利用研发工作的成果并将其转移到生产环境中,他们希望在生产中使用 Amazon SageMaker 终端节点每天处理高度专业化的专业领域的数百万个请求。
安全、轻松、持续地访问大量专有数据
保护 TR 的知识产权对于企业的长期成功非常重要。因此,TR 在云中的安全性和工作方式方面制定了明确且不断发展的标准,必须遵循这些标准来保护其资产。
这给 TR 的科学家提出了一些关键问题。他们如何创建安全且符合 TR 标准的 Amazon SageMaker 笔记本实例(或启动训练作业)? 科学家如何在 Amazon SageMaker 内安全地访问 TR 的数据? TR 需要确保科学家只需付出很少的代价就能一致、安全地做到这一点。
进入安全内容工作区。SCW 是 TR 的研发团队开发的基于 Web 的工具,可以回答这些问题。下图显示了之前所述的 TR 研究工作背景下的 SCW。
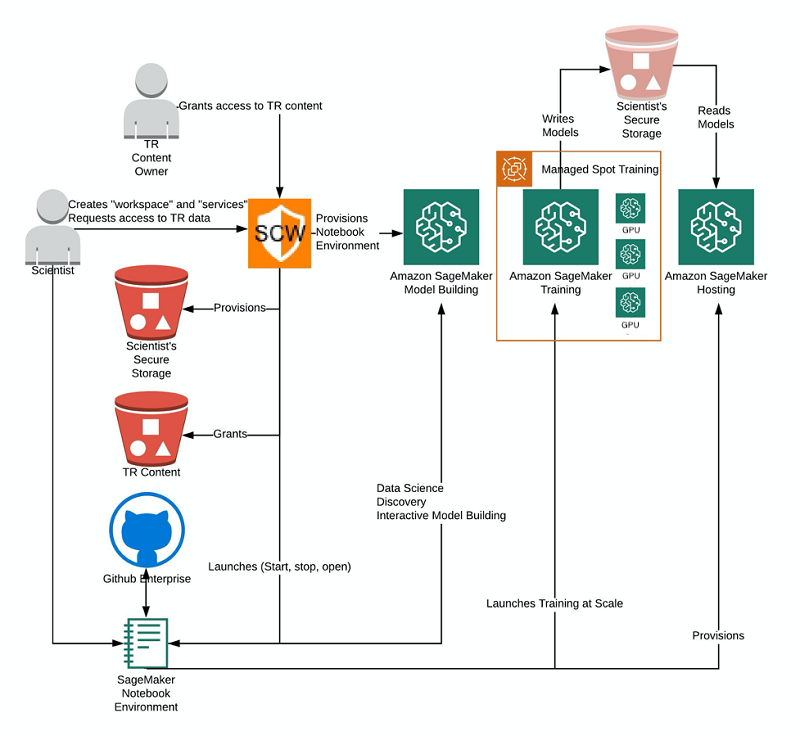
SCW 支持对 TR 的数据进行安全和受控的访问。它还以符合 TR 标准的方式配置服务,例如使用 Amazon SageMaker 来配置。在 SCW 的帮助下,科学家们知道他们会遵守安全协议,可以放心地在云中工作。SCW 让他们可以专注于自己擅长的领域,即用人工智能 (AI) 解决难题。
结论
Thomson Reuters 全身心致力于研究和开发先进的 AI 能力,以帮助客户开展工作。MRC 的研究是这些活动中的最新成果。初步结果表明,TR 的产品线有广泛的应用,尤其是在自然语言问答方面。过去的解决方案涉及广泛的特征工程和复杂的系统,但这项新研究表明,我们可以实现更简单的机器学习 (ML) 解决方案。整个科学界在这个领域都非常活跃,TR 为成为其中的一员而感到自豪。
如果没有 GPU 提供的强大计算能力以及按需扩展的能力,这项研究是不可能实现的。Amazon SageMaker 功能套件为 TR 提供了构建、训练和托管用于测试的模型所需的原始能力和必要的框架。TR 构建了 SCW 来支持基于云的研发,例如 MRC。SCW 在云中建立科学家的工作环境,并确保符合 TR 的所有安全标准和建议。它使用像 Amazon SageMaker 这样的工具来保证 TR 的数据安全。
展望未来,TR 研究团队正在考虑使用 Amazon SageMaker 和 SCW,基于这些强大的深度学习架构,引入更广泛的 AI/ML 功能。此类高级功能的示例包括即时答案生成、长文本摘要以及完全交互式和对话式问答。这些功能将实现全面的辅助 AI 系统,引导用户找到满足其所有信息需求的最佳解决方案。
关于作者

Mark Roy 是机器学习专家解决方案架构师,可在客户大规模采用架构完善的机器学习解决方案的过程中为他们提供帮助。在业余时间,Mark 喜欢玩、当教练和打篮球。

Qingwei Li 是 Amazon Web Services 的机器学习专家。在他中断了导师的研究补助金账户并且未能兑现他承诺的诺贝尔奖之后,他获得了运筹学博士学位。目前,他帮助金融服务和保险行业的客户在 AWS 上构建机器学习解决方案。业余时间,他喜欢阅读和教学。

John Duprey 是 Thomson Reuters AI 和认知计算中心 (C3) 的高级工程总监。John 和工程团队与科学家和产品技术团队合作,为 Thomson Reuters 客户极具挑战性的问题开发基于 AI 的解决方案。

Filippo Pompili 是 Thomson Reuters AI 和认知计算中心 (C3) 的 NLP 高级研究科学家。Filippo 拥有机器阅读理解、信息检索和神经语言建模方面的专业知识。他积极致力于将先进的机器学习发现引入 Thomson Reuters 先进的产品中。