亚马逊AWS官方博客
如何利用 AWS Lambda 和 Tensorflow 部署深度学习模型
深度学习已经彻底变革了我们处理和加工真实数据的方式。深度学习的应用程序有多种类型,包括用于整理用户照片存档、推荐书籍、检测欺诈行为以及感知自动驾驶车辆周边环境的应用程序。
在这篇文章中,我们将向您逐步演示如何通过 AWS Lambda 使用自定义的训练模型,从而大规模利用简化的无服务器计算方法。在此过程中,我们将介绍一些核心 AWS 服务,您可以使用这些服务以无服务器的方式运行推理。
我们还将了解图像分类:现在已有多种表现非常出色的开源模型可供使用。通过图像分类,我们可以使用深度学习中两种最常用的网络类型:卷积神经网络和全连接神经网络 (也称为 Vanilla 神经网络)。
我们将向您演示在 AWS 中的什么位置放置训练模型,以及以何种方式打包您的代码,以便 AWS Lambda 通过推理命令执行这些代码。
在这篇博客文章中,我们将讨论以下 AWS 服务:AWS Lambda、Amazon Simple Storage Service (S3)、AWS CloudFormation、Amazon CloudWatch 和 AWS Identity and Access Management (IAM)。使用的语言和深度学习框架包括 Python 和 TensorFlow。此处介绍的流程也适用于任何其他深度学习框架,例如 MXNet、Caffe、PyTorch、CNTK 及其他框架。
整体架构
AWS 架构
从流程的角度而言,深度学习系统的开发和部署与开发和部署传统解决方案应该没有不同。
下图描述了一种可能的开发生命周期:
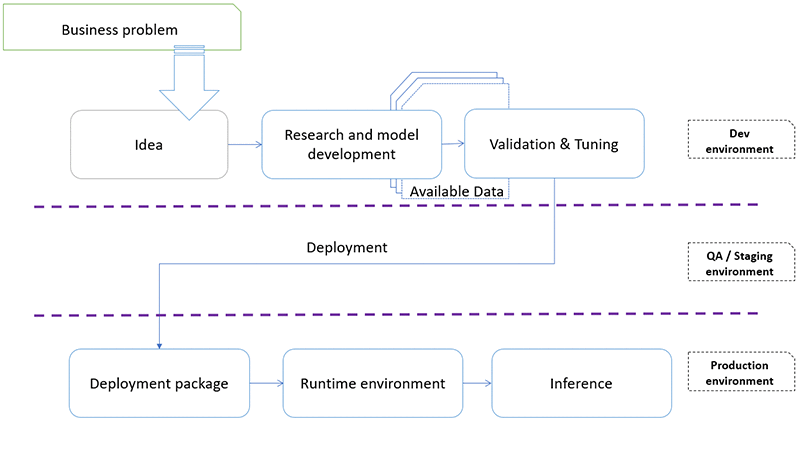
如您从图中可见,通常的软件开发流程经过多个阶段,从开发环境中的概念成形和建模,直到生产环境中的最终模型部署。在大部分情况下,开发阶段会有多次快速迭代,需要不断对环境进行更改。通常,这会影响在软件/模型开发期间所用资源的性质和质量。对于敏捷开发而言,能够快速构建/重建/停用环境至关重要。所构建软件的快速改变随之而来的应该是基础设施调整。敏捷开发和加速创新的先决条件之一是能够通过代码管理基础设施 (称为 IaC:基础设施即代码)。
软件设计管理、构建和部署的自动化是持续集成和持续交付 (CI/CD) 的一部分。虽然本文不会深入介绍精心编排的 CI/CD 管道的细节,不过,对于任何开发运营团队来说,如果希望构建可重复的流程,以实现开发/部署敏捷性和流程自动化,就应该记住这一点。
AWS 在社区中推出了众多服务和实践,可简化开发任务。一个环境,只要使用自动化代码构建,那么只需数分钟就可以轻松地采用和复制,例如,可以根据开发环境所用的模板构建暂存和生产系统。
此外,AWS 使用多种计算机科学和软件工程概念,通过流式处理、批处理、队列处理、监控和报警、实时事件驱动的系统、无服务器计算等完全托管的服务,显著简化了复杂解决方案的设计。在本文中,我们将探讨用于深度学习的无服务器计算环境,它可以帮助您避免服务器预配置和管理等繁重任务。这些任务使用 AWS 服务完成,使得数据科学家和软件开发人员避免了不必要的复杂性,例如确保有足够的计算容量、确保系统故障时的重试等。
在本文中,我们重点介绍模拟生产系统的类似于暂存的环境。
基于 Amazon S3 的使用案例
在此使用案例中,我们将模拟对存储在 Amazon Simple Storage Service (S3) 存储桶中的图像进行处理的过程。用于存放对象的 S3 存储桶具有通知功能,可向其余 AWS 云生态系统通知有关对象 PUT 事件的信息。在大多数情况下会使用 Amazon Simple Notification Service (SNS) 通知机制,或者自动触发 AWS Lambda 函数中的用户代码。为了简化起见,我们将使用在出现 S3 对象 PUT 事件时触发的 Lambda 函数。您可能已经注意到了,我们面对的是一些非常复杂的概念,而实际工作中科学家/开发人员很少涉及到这些。
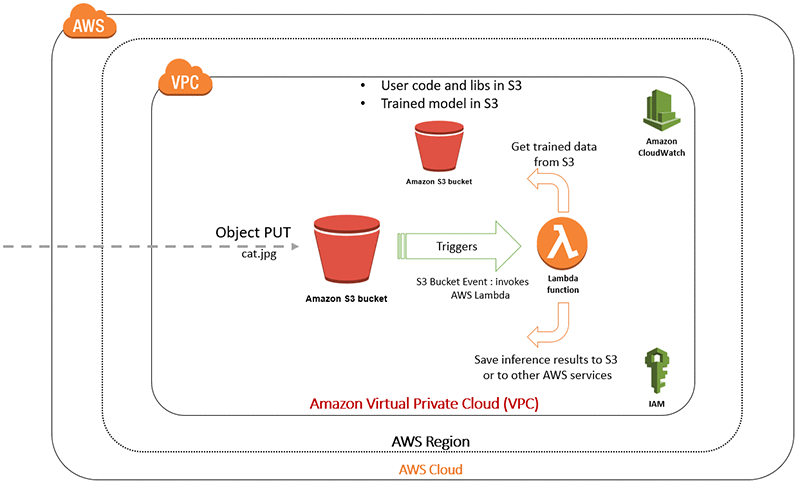
我们的训练机器学习模型是使用 Python TensorFlow 开发的,位于 S3 存储桶中。在模拟中,我们会将一张猫的图片上传到任意启用了存储桶事件通知的存储桶中。我们的 Lambda 函数将订阅这些 S3 存储桶通知事件。
在本文中,所有云基础设施均使用 AWS CloudFormation 构建,它提供了快速灵活的接口来创建和启动 AWS 服务。作为另一种设计和启动 AWS 资源的方法,此过程也可以使用 AWS 管理控制台或者使用 AWS 命令行界面 (AWS CLI) 手动完成。
深度学习代码
现在,有一种简单高效的方法可用来快速开发基于 AI 的系统,这就是利用现有模型并根据您的使用案例进行微调,尤其是要利用已公开发布的先进模型。
我们接下来部署一个强大的 Inception-v3 模型,该模型经过预训练,用于图像分类。
Inception-v3 架构

此处显示的 Inception-v3 架构使用颜色指示层类型。对您而言,了解模型的各个部分并不重要。不过,重要的是需要认识到这是一个真正的深度网络,从头开始训练所需的时间和资源数量 (数据和计算) 令人望而生畏。
我们利用 TensorFlow 图像识别教程下载经过预训练的 Inception-v3 模型。
首先,创建 Python 2.7 virtualenv 或 Anaconda 环境,并安装适用于 CPU 的 TensorFlow (我们完全不需要 GPU)。
然后下载 classify_image.py (地址为 https://github.com/tensorflow/models/tree/master/tutorials/image/imagenet),并在您的 shell 中执行它:
这将下载经过预训练的 Inception-v3 模型并在示例图像 (熊猫) 上运行它,这将验证实施是否正确。
此过程创建类似于下面的目录结构:
现在,您需要获取此模型文件及所有必需的已编译 Python 程序包,并创建 AWS Lambda 可执行的包。为了简化这些步骤,我们提供了所有必需的二进制文件,方便您使用。您可以按照以下步骤,在数分钟内启动并运行演示。
作为演示包的一部分,我们提供了一个很大的模型文件。由于文件相当大 (超过 90 MB),我们需要在 AWS Lambda 从 Amazon S3 执行推理期间加载它。查看提供的推理代码 (classify_image.py),您会发现我们将模型下载放在了处理程序函数之外。我们这样做是为了充分利用 AWS Lambda 的容器重用。任何在处理程序方法之外执行的代码,在容器创建时只会调用一次,并保留在内存中供对相同 Lambda 容器的所有调用使用,使得后续对 Lambda 的调用更快。
AWS Lambda 预热操作是您在首次生产运行之前主动启动 AWS Lambda。这可帮助您避免 AWS Lambda“冷启动”的潜在问题,这是指在每次执行“冷”Lambda 实例化时都需要从 S3 加载大模型。在 AWS Lambda 正常运行之后,保持它的热状态可以带来好处,这样可确保下次推理运行时可以快速响应。只要每隔数分钟激活 AWS Lambda 一次 (即使是使用某种类型的 ping 通知完成激活),它都会在 Lambda 需要运行推理任务时保持热状态。
现在,我们需要将代码和所有必需的程序包压缩在一起。通常,您必须在 Amazon Linux EC2 实例上编译所有必需的程序包,然后才能将其用于 AWS Lambda。(这部分内容在 http://docs.aws.amazon.com/lambda/latest/dg/lambda-python-how-to-create-deployment-package.html 中已有介绍。)不过,在这篇博客文章中,我们提供了已编译的文件以及完整的 deeplearning-bundle.zip 文件,其中包含之前介绍的所有代码以及必需程序包,可以直接用于 AWS Lambda。
使用 AWS Lambda 进行部署
下面是您开始操作的几个主要步骤:
- 下载 DeepLearningAndAI-Bundle.zip。
- 解压缩并将文件复制到 Amazon S3 存储桶。我们将它命名为 dl-model-bucket。此文件夹将包含您运行本演示所需的全部内容,例如:
- classify_image.py
- classify_image_graph_def.pb
- deeplearning-bundle.zip
- DeepLearning_Serverless_CF.json
- cat-pexels-photo-126407.jpeg (无版税图像,用于测试目的)
- dog-pexels-photo-59523.jpeg (无版税图像,用于测试目的)
- 运行 CloudFormation 脚本以在 AWS 中创建所有必需的资源,包括您的测试 S3 存储桶;我们将它命名为 deeplearning-test-bucket (如果此存储桶名称已被占用,您需要使用其他名称)。下面提供了分步说明。
- 将图像上传到您的测试存储桶。
- 转到您的 Lambda 推理函数的 Amazon Cloud Watch 日志,并验证推理结果。
下面是运行 CloudFormation 脚本的分步指南:
- 转至 AWS CloudFormation 控制台并选择“创建新堆栈”按钮。
- 在“指定 Amazon S3 模板 URL”部分,提供指向 CloudFormation 脚本 (json) 的链接。选择“下一步”。
- 输入必需值:CloudFormation 堆栈名称、测试存储桶名称 (您将要识别的图像上传到其中的存储桶,我们将它命名为 deeplearning-test-bucket) 以及存放模型和代码的存储桶。

- 选择“下一步”。跳过“选项”页面。转到“审核”页面。在页面的底部,您应进行确认。选择“创建”按钮。您应看到 CREATE_IN_PROGRESS 状态,并且稍后将看到 CREATE_COMPLETE 状态。

此时,CloudFormation 脚本已生成了整个解决方案,包括 AWS Identity and Access Management (IAM) 角色、深度学习推理 Lambda 函数,以及在对象放入到测试存储桶中时 S3 存储桶触发 Lambda 函数的权限。
查看 AWS Lambda 服务,您会看到新的 DeepLearning_Lambda 函数。AWS CloudFormation 已经完全配置了所有必需参数,并添加了在推理期间使用的必需环境变量。
新的测试存储桶应已创建。要测试我们的深度学习推理功能,请上传图像到之前创建的 S3 存储桶:deeplearning-test-bucket。
获取推理结果
要执行您已编写的代码,只需将任何图像上传到 CloudFormation 脚本创建的 Amazon S3 存储桶。此操作将触发我们的推理 Lambda 函数。
下面是将测试图像上传到测试存储桶的示例。
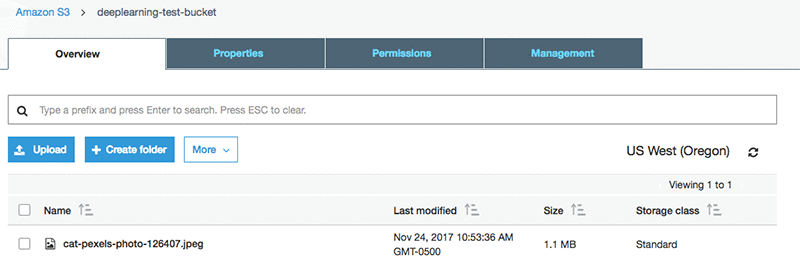
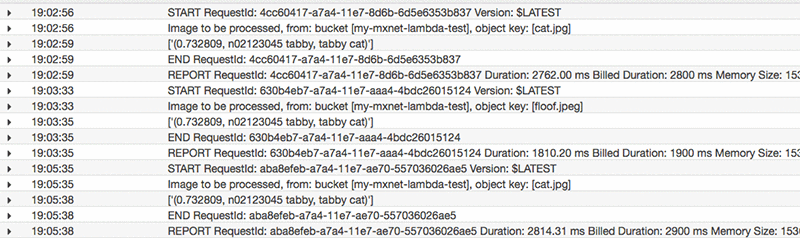
此时,S3 存储桶已经触发了我们的推理 Lambda 函数。在这篇博客文章中,我们将转到 CloudWatch Logs 以查看推理结果。在控制台中的 AWS Lambda 服务屏幕上,选择“监控”,然后选择“查看日志”。请注意,当您实际处理推理结果时,这些结果应该存储在我们的某个持久性存储中,例如 Amazon DynamoDB 或 Amazon Elasticsearch Service,在其中您可以轻松地索引图像和关联的标签。

在此日志中,您将看到模型加载在 Lambda 容器构造期间完成。在接下来的调用中,只要容器仍保持“热”状态,就只进行推理 (模型已在内存中),这样可减少整体运行时间。以下屏幕截图显示了后续的 Lambda 函数执行。
无服务器环境中的深度学习提示
无服务器环境的使用带来了许多机会,可以简化开发和生产代码的部署。打包代码及其依赖项的步骤因运行时环境而异,因此需要熟悉这些内容,避免在首次部署期间出现问题。Python 是非常流行的语言,可供数据科学家用来构建机器学习模型。要在 AWS Lambda 上运行期间实现最佳性能,依赖于旧 C 和 Fortran 的 Python 库应该使用 Amazon Linux Amazon 系统映像 (AMI) (随后可以导出其生成的文件) 在 Amazon Elastic Compute Cloud (EC2) 上构建和安装。在这篇博客文章中,我们已经完成了这个步骤。您可以随意利用这些库来构建最终的部署程序包。此外,在网上很容易找到预编译的 Lambda 包,例如在 https://github.com/ryfeus/lambda-packs 中。
模型训练通常需要密集的计算工作,在专用硬件上使用大量 GPU 资源。幸好,推理相比训练所需的计算量要小得多,可以使用 CPU 并利用 Lambda 无服务器计算模型。如果您确实需要 GPU 进行推理,可以考虑使用容器服务,例如 Amazon ECS 或 Kubernetes,这可以让您更好地控制您的推理环境。有关详细信息,请参阅这篇文章:https://aws.amazon.com/blogs/ai/deploy-deep-learning-models-on-amazon-ecs/。
随着您的项目越来越多地迁移到无服务器架构,很快您就会学习到这一计算方法带来的机会和挑战:
- 无服务器可以显著地简化计算基础设施的使用,避免管理 VPC、子网、安全性、构建和部署 Amazon EC2 服务器的复杂性等等。
- AWS 会为您处理容量。
- 经济高效 – 您只需在使用计算资源时付费,计费以 100 毫秒为增量。
- 异常处理 – AWS 会处理重试,并将出现问题的数据/消息存储在 Amazon SQS/Amazon SNS 中供以后处理。
- 在 Amazon CloudWatch Logs 中收集和存储所有日志。
- 可以使用 AWS X-Ray 工具监视性能。
如果您计划处理较大的文件/对象,请确保使用输入流方法,而不是在内存中加载全部内容。在工作中,我们通常会使用 AWS Lambda 函数,利用传统文件/对象流式处理方法来处理非常大的文件 (甚至超过 20 GB)。为了改进网络 I/O,请确保使用压缩,因为在多数情况下这会显著减少文件/对象大小 (特别是 CSV 和 JSON 编码)。
虽然本博客文章使用 Inception-v3 模型 (最大内存用量约为 400 MiB),不过也提供了较低内存的选项,例如 MobileNets 和 SqueezeNet。如果您希望探索其他模型或者面临计算/内存/精度约束情况,可以在 Canziani 等中找到针对不同模型的很好的分析。这种分析其实就是本文侧重于 Inception-v3 的原因。我们相信这在精度、计算要求和内存使用方面提供了很好的折衷。
调试 Lambda 函数不同于在传统基于本地主机/笔记本电脑进行开发时的调试。相反,我们建议您先创建本地主机代码 (这应易于调试),最后再将其提升到 Lambda 函数中。从笔记本电脑环境切换到 AWS Lambda 只需很少的更改,例如:
- 替换使用的本地文件引用 – 例如,将它们替换为 S3 对象。
- 读取环境变量 – 这些变量可以抽象化以具有相同逻辑。
- 输出到控制台 – 您仍可以使用输出函数,不过它们会重定向到 CloudWatch Logs,几秒钟以后就可以看到日志。
- 调试 – 调试程序不能用于 AWS Lambda,但是如前所述,只有当它在主机环境中正确运行时,才能使用所有这些工具在主机上进行开发和部署结果。
- 运行时设备 – 启用 AWS X-Ray 服务以深入了解运行时数据,以便确定问题和寻求优化机会。
在您将您的代码和依赖项打包到单个 ZIP 文件中之后,部署到 AWS Lambda 会比较繁琐。利用 CI/CD 工具,例如这篇博客文章开头提到的工具,可以简化这个步骤,并且更重要的是可实现完全自动化。任何时候,只要检测到代码更改,CI/CD 管道将根据您的配置,自动生成结果并将结果快速部署到请求的环境。此外,AWS Lambda 支持版本控制和别名使用,这让您能够快速在 Lambda 函数的不同变体之间切换。当您在不同环境 (例如研究、开发、暂存和生产) 中工作时,这会非常有用。在发布某个版本后,它是不可变的,这可以避免不小心更改了您的代码。
结论
简而言之,这篇文章介绍了在无服务器环境中,使用 AWS Lambda 通过您的自定义训练模型进行大规模深度学习。
补充阅读
- 使用 AWS Lambda 和 MXNet 无缝进行大规模预测
- 经过更新的 AWS Deep Learning AMI:新版本 TensorFlow、Apache MXNet、Keras 和 PyTorch
作者简介
 Boris Ivanovic 荣获斯坦福大学计算机科学硕士学位,专长于人工智能。2017 年夏天,他获得了 Prime Air SDE 实习机会,研究通过无人驾驶飞行器在 30 分钟或更短时间内安全地将包裹送达客户。
Boris Ivanovic 荣获斯坦福大学计算机科学硕士学位,专长于人工智能。2017 年夏天,他获得了 Prime Air SDE 实习机会,研究通过无人驾驶飞行器在 30 分钟或更短时间内安全地将包裹送达客户。
 Zoran Ivanovic 是加拿大 AWS 专业服务的大数据首席顾问。在领导了 Amazon 最大的大数据团队之一 5 年时间后,他被调动到 AWS,利用自己的经验,帮助有兴趣在云中利用 AWS 服务构建关键业务系统的大型企业客户。
Zoran Ivanovic 是加拿大 AWS 专业服务的大数据首席顾问。在领导了 Amazon 最大的大数据团队之一 5 年时间后,他被调动到 AWS,利用自己的经验,帮助有兴趣在云中利用 AWS 服务构建关键业务系统的大型企业客户。