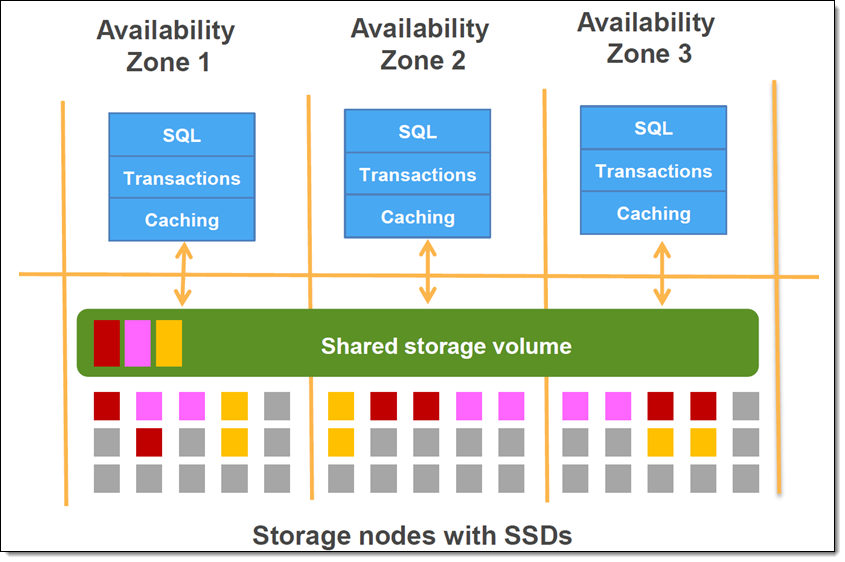
Amazon Aurora 是一种旨在全面发挥云中联网、处理和存储资源丰富的优势的关系数据库。Aurora 在用户可见层面保持了与 MySQL 和 PostgreSQL 的兼容,同时又在底层使用先进的特制分布式存储系统。您的数据跨三个不同的 AWS 可用区分布在数百个存储节点上,每个可用区两个副本,存储节点采用高速 SSD 存储设备。以下是这一结构的原理图(摘取自 Amazon Aurora 入门):
新增并行查询功能
在我们推出 Aurora 时,我们在计划中还按时要采用与数据库堆栈的其他层相同的扩展设计原则。今天,我想向大家介绍以下我们在该道路上的下一步计划。
在上图所描绘的存储层中,每个节点还包含大量的处理能力。现在,Aurora 能够提取您的分析查询(通常为处理一张大表中全部或相当大一部分内容的查询),然后跨数百个甚至数千个存储节点并行运行这些查询,充分利用这一处理能力,将速度提高两个量级。由于这种新模式减少了对网络、CPU 和缓冲池资源的争夺,您可以在一张表同时混合运行分析查询和事务查询,同时保持这两类查询的高吞吐量。
实例类别决定了在给定时间可以激活的并行查询数量:
- db.r*.large – 1 个并发并行查询会话
- db.r*.xlarge – 2 个并发并行查询会话
- db.r*.2xlarge – 4 个并发并行查询会话
- db.r*.4xlarge – 8 个并发并行查询会话
- db.r*.8xlarge – 16 个并发并行查询会话
- db.r4.16xlarge – 16 个并发并行查询会话
您可以使用 aurora_pq 参数来启用和禁用全局和会话级别的并行查询。
并行查询可增长超过 200 种单表断言和哈希连接的性能。Aurora 查询优化器会根据表的大小和内存中已有的表数据量自动决定是否使用并行查询功能;您还可以使用 aurora_pq_force 会话变量来覆盖优化器以满足测试的需要。
并行查询的操作
您需要创建一个新的集群才能使用并行查询功能。您可以全新创建,也可以通过还原快照的方式创建。
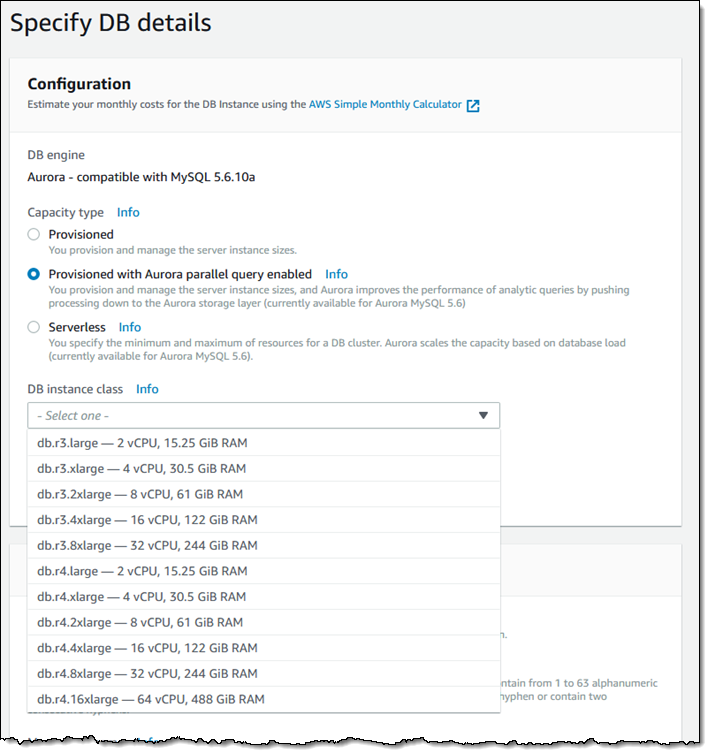
为了创建一个支持并行查询的集群,我只需将 Provisioned with Aurora parallel query enabled 选择为 Capacity type:
我使用 CLI 还原了一个 100 GB 的快照进行测试,然后探索来自 TPC-H 基准测试的一条查询。基本查询如下:
SELECT
l_orderkey,
SUM(l_extendedprice * (1-l_discount)) AS revenue,
o_orderdate,
o_shippriority
FROM customer, orders, lineitem
WHERE
c_mktsegment='AUTOMOBILE'
AND c_custkey = o_custkey
AND l_orderkey = o_orderkey
AND o_orderdate < date '1995-03-13'
AND l_shipdate > date '1995-03-13'
GROUP BY
l_orderkey,
o_orderdate,
o_shippriority
ORDER BY
revenue DESC,
o_orderdate LIMIT 15;
EXPLAIN 命令会显示查询方案,包括并行查询的使用:
+----+-------------+----------+------+-------------------------------+------+---------+------+-----------+--------------------------------------------------------------------------------------------------------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+----------+------+-------------------------------+------+---------+------+-----------+--------------------------------------------------------------------------------------------------------------------------------+
| 1 | SIMPLE | customer | ALL | PRIMARY | NULL | NULL | NULL | 14354602 | Using where; Using temporary; Using filesort |
| 1 | SIMPLE | orders | ALL | PRIMARY,o_custkey,o_orderdate | NULL | NULL | NULL | 154545408 | Using where; Using join buffer (Hash Join Outer table orders); Using parallel query (4 columns, 1 filters, 1 exprs; 0 extra) |
| 1 | SIMPLE | lineitem | ALL | PRIMARY,l_shipdate | NULL | NULL | NULL | 606119300 | Using where; Using join buffer (Hash Join Outer table lineitem); Using parallel query (4 columns, 1 filters, 1 exprs; 0 extra) |
+----+-------------+----------+------+-------------------------------+------+---------+------+-----------+--------------------------------------------------------------------------------------------------------------------------------+
3 rows in set (0.01 sec)
Extras 列的相关部分如下:
Using parallel query (4 columns, 1 filters, 1 exprs; 0 extra)
使用并行查询时,查询运行的时间不到 2 分钟:
+------------+-------------+-------------+----------------+
| l_orderkey | revenue | o_orderdate | o_shippriority |
+------------+-------------+-------------+----------------+
| 92511430 | 514726.4896 | 1995-03-06 | 0 |
| 593851010 | 475390.6058 | 1994-12-21 | 0 |
| 188390981 | 458617.4703 | 1995-03-11 | 0 |
| 241099140 | 457910.6038 | 1995-03-12 | 0 |
| 520521156 | 457157.6905 | 1995-03-07 | 0 |
| 160196293 | 456996.1155 | 1995-02-13 | 0 |
| 324814597 | 456802.9011 | 1995-03-12 | 0 |
| 81011334 | 455300.0146 | 1995-03-07 | 0 |
| 88281862 | 454961.1142 | 1995-03-03 | 0 |
| 28840519 | 454748.2485 | 1995-03-08 | 0 |
| 113920609 | 453897.2223 | 1995-02-06 | 0 |
| 377389669 | 453438.2989 | 1995-03-07 | 0 |
| 367200517 | 453067.7130 | 1995-02-26 | 0 |
| 232404000 | 452010.6506 | 1995-03-08 | 0 |
| 16384100 | 450935.1906 | 1995-03-02 | 0 |
+------------+-------------+-------------+----------------+
15 rows in set (1 min 53.36 sec)
我可以禁用会话的并行查询(我可以使用 RDS 自定义集群参数组以使其长期生效):
set SESSION aurora_pq=OFF;
禁用并行查询后查询的运行速度会显著下降:
+------------+-------------+-------------+----------------+
| l_orderkey | o_orderdate | revenue | o_shippriority |
+------------+-------------+-------------+----------------+
| 92511430 | 1995-03-06 | 514726.4896 | 0 |
...
| 16384100 | 1995-03-02 | 450935.1906 | 0 |
+------------+-------------+-------------+----------------+
15 rows in set (1 hour 25 min 51.89 sec)
这是在一个 db.r4.2xlarge 实例上运行的结果;其他实例型号、数据集、访问模式和查询的性能都会不同。此外,我还可以覆盖查询优化器,坚持使用并行查询进行测试:
set SESSION aurora_pq_force=ON;
注意事项
在开始探索 Amazon Aurora 并行查询时需要注意以下几个方面:
引擎支持 — 我们正在推出对 MySQL 5.6 的支持,并在研究对 MySQL 5.7 和 PostgreSQL 的支持。
表格式 — 表的行格式必须为 COMPACT;不支持分区表。
数据类型 — 不支持 TEXT、BLOB 和 GEOMETRY 数据类型。
DDL — 表不能有任何待处理的快速在线 DDL 操作。
费用 — 您使用并行查询功能不会发生任何额外的费用。但由于它会直接访问存储,因此您的 IO 费用可能会上升。
立即尝试
这项新功能现已推出,您可以立即开始使用!
本篇作者