亚马逊AWS官方博客
新增功能——使用Amazon SageMaker Feature Store存储、发现并共享机器学习特征
原文链接:
今天,我们很高兴公布Amazon SageMaker Feature Store。作为Amazon SageMaker中的一项新功能,Feature Store将帮助数据科学家与机器学习工程师轻松安全地存储、发现并共享训练与预测工作流中使用的被选中数据。
如同正确算法之于机器学习(ML)模型训练,经验丰富的从业者都很清楚高质量数据的重要意义。数据清洗无疑是良好的起点,包括在机器学习工作流中填充缺失值、消除异常值等。以此为基础,我们往往使用一种既常见、又相当不可思议的技术(即「特征工程」)进行数据转换。
简而言之,特征工程的目标在于转换数据并提高其表达能力,借此改善算法的学习效果。例如,大部分列式数据集都包含字符串,例如街道地址。对大多数机器学习算法而言,字符串没有任何意义,必须通过编码以数字形式表示。因此,我们可以将街道地址转换为GPS坐标,这就是一种更具表现力的位置概念学习方法。换句话说,如果数据是原油,那么特征工程就是将其转化为高辛烷值燃料的精炼过程,由此推动模型获得更高精度。
事实上,机器学习从业者往往耗费大量时间来开发特征工程代码、将其应用于初始数据集、在工程数据集上训练模型,最终评估模型的准确性。考虑到这项工作的实验性质,即使是最小的项目也需要进行多次迭代。同样的特征工程代码会一遍又一遍运行,这些重复的操作无疑既浪费时间、又浪费资源。在大型组织当中,这可能引发更严重的生产力损失,导致不同团队需要执行相同的工作,甚至因为不了解之前的工作成果而编写重复的特征工程代码。
机器学习团队还需要解决另一个难题。由于模型在工程数据集之上训练而成,因此必须对用于预测的数据执行相同的转换。在此期间,我们往往需要重写特征工程代码(有时需要使用另一种语言)、将其集成至预测工作流内,并在预测时进行这部分代码。整个过程不仅极为耗时,而且由于数据转换中极其微小的变化都可能对预测结果产生重大影响,因此往往存在严重的不一致问题。
为了解决这些问题,机器学习团队有时会建立特征库。这是一类中央存储库,团队可以在其中保存并检索可供训练及预测工作使用的工程数据。可以想见,要建立这样一套特征存储体系,我们需要大量的工程、基础设施与运营工作,这又会占用本应用于实际机器学习工作的宝贵时间。客户希望我们提供相应的解决方案,于是我们开始付诸行动。
关于Amazon SageMaker Feature Store
Amazon SageMaker Feature Store是一套完全托管的集中存储库,可安全便捷地存储并检索机器学习特征,用户无需管理任何基础设施。Feature Store是Amazon Web Services推出的Amazon SageMaker的组成部分,并可支持所有算法。它也能够与我们基于Web的机器学习开发环境Amazon SageMaker Studio相集成。
SageMaker Feature Store中存储的特征将以组为单位进行组织,并使用元数据加以标记。以此为基础,您可以快速判断哪些特征可用,以及是否适用于您的模型。各团队之间还可以轻松共享并重用这些特征,从而降低开发成本并加快创新速度。
在存储完成之后,各项特征即可在模型训练、批量转换以及低延迟实时预测等SageMaker工作流内各环节被检索与使用。以此为基础,您不仅可以避免重复工作,同时也可以建立起统一的工作流,确保各工作流使用存储在离线及在线存储库内的相同特征。
作为拜耳旗下子公司,The Climate Corporation (Climate)致力于帮助农民获得数字化创新能力。该公司气候数据与分析副总裁Daniel McCaffrey表示: “在Climate,我们坚信应当为世界各地的农民提供准确信息,帮助他们以数据为依据做出决策,最终在单位土地上获得最大回报。为了实现这一目标,我们投资构建机器学习工具等多种技术,并通过「特征」这类可量化实体(例如亩产指标)构建模型。借助Amazon SageMaker Feature Store,我们得以使用这套中央特征库加速机器学习模型的开发,轻松跨多个团队实现特征访问与重用。SageMaker Feature Store使用户能够轻松使用在线存储库实时访问特征,或使用离线存储库按计划在不同用例内运行特征,由此加快机器学习模型的开发速度。”
全球领先的高质量家庭护理服务搜索与管理平台Care.com也在使用Amazon SageMaker Feature Store。根据Care.com公司数据科学经理Clemens Tummeltshammer的介绍: “要推动从个人、家庭到整个国家的经济增长,我们必须建立起供需相匹配的健壮产业。我们对Amazon SageMaker Feature Store与Amazon SageMaker Pipelines深表赞赏,也相信它们将通过使用统一的精选数据集帮助我们在整个数据科学及开发团队中建立良好的扩展能力,由此构建起可扩展的数据准备与部署体系,进而支撑起可扩展的端到端机器学习模型管道。借助Amazon SageMaker新近公布的这项功能,我们能够加快不同应用程序中机器学习模型的开发与部署,加快实时建议交付速度、帮助客户做出更明智的决策。”
下面,我们一起了解如何上手使用Feature Store。
使用Amazon SageMaker Feature Store存储及检索特征
在数据之上运行特征工程代码之后,您可以将工程处理后的特征按组的形式组织并存储在SageMaker Feature Store当中。特征组属于记录的集合,类似于表中的行。每条记录都拥有唯一标识符,并保存原始数据源内某一数据实例的工程特征值。作为可选项,您还可以选择使用自己的Amazon密钥管理服务(KMS)密钥对静态数据进行加密。各特征组分别使用唯一的密钥。
您可以随意定义各个特征组。例如,您可以为每种数据源(CSV文件、数据库表等等)创建一个组,也可以方便地使用唯一列作为记录标识符(主键、客户ID、事务ID等)。
在完成分组之后,即可各个组重复以下操作步骤:
1. 创建特征定义,并在记录中保存每项特征的名称与类型(Fractional, Integral或者String)。 2. 使用create_feature_group()API创建各个特征组: 3. sm_feature_store.create_feature_group( 4. # 特征组的名称 5. FeatureGroupName=my_feature_group_name, 6. # 用作记录标识符的列名称 7. RecordIdentifierName=record_identifier_name, 8. # 作为特征时间戳的列行为名称 9. EventTimeFeatureName = event_time_feature_name, 10. # 特征名称与类型清单 11. FeatureDefinitions=my_feature_definitions, 12. # 离线特征存储库的S3位置 13. OfflineStoreConfig=offline_store_config, 14. # 可选项,启用在线特征存储库 15. OnlineStoreConfig=online_store_config, 16. # 一个IAM角色 17. RoleArn=role )
18. 在各个特征组内,使用put_record()API存储包含特征名称/特征值对的集合记录: 19. sm_feature_store.put_record( 20. FeatureGroupName=feature_group_name, 21. Record=record, 22. EventTime=event_time )
为了加快数据摄取速度,您可以创建多个线程以实现操作并行化。
到这里,Amazon SageMaker Feature Store即可提供各项特征。以离线存储库为基础,您可以使用Amazon Athena, AWS Glue或者Amazon EMR等服务构建供训练使用的数据集:在S3中获取相应的JSON对象、选择必要的特征,而后以机器学习算法需要的格式将其保存在S3当中。之后的工作即可全部交给SageMaker,就这么简单!
除此之外,您也可以使用get_record() API访问在线存储库内存储的各具体记录,并传递组名称与待访问记录的唯一标识符,如下所示:
record = sm_feature_store.get_record(
FeatureGroupName=my_feature_group_name,
RecordIdentifierValue={"IntegralValue": 5962}
)
Amazon SageMaker Feature Store专为实时推理场景下的高效访问需求与设计,对于15 KB的载荷,可以95% 的概率将预测中的延迟控制在10毫秒以内。凭借这种能力,大家可以在预测过程中查询工程特征,并将上游应用程序发送的原始特征替换为模型训练时曾经使用的具体特征。通过这种方式,我们可以消除特征不一致问题,帮助大家将精力集中在最佳模型的构建当中。
最后,SageMaker Feature Store当中包含特征创建时间戳,因此大家可以根据特定时间点检索特征状态。
如果将Amazon SageMaker Feature Store与SageMaker Studio相集成,我们可以看到两个特征组。
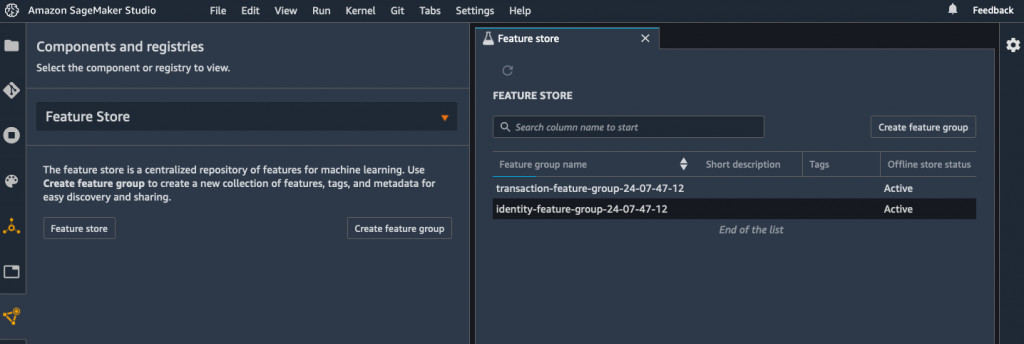
右键点击“Open feature group detail”,即可打开身份特征identity feature group。

这里可以看到特征定义。

最后,我们可以为离线存储库生成查询,并将其添加至Amazon SageMaker Data Wrangler工作流,借此在训练之前加载特征。

如何快速上手Amazon SageMaker Feature Store
如大家所见,SageMaker Feature Store极大降低了在各训练与预测工作流之间存储、检索及共享特征的门槛。
现在,您已经可以在提供Amazon SageMaker服务的各个Amazon Web Services区域中使用这项服务,具体成本取决于特征读取/写入量以及所存储的数据总量。
您可以参考示例notebooks立即体验,我们也期待听取您关于使用体验的感受。欢迎大家通过Amazon Web Services客户支持渠道以及Amazon SageMaker论坛与我们交流。