亚马逊AWS官方博客
为您的 IT 挑战选择正确工具
此客座博文来自 AWS 社区精英 Markus Ostertag。作为总部位于慕尼黑的广告科技公司 Team Internet AG 的 CEO,Markus 始终坚持尝试寻找利用云计算的最佳方式,乐于使用尖端技术,频繁参与 AWS 活动进行演讲,并于 2014 年联合创立了慕尼黑 AWS 用户群,也经常参加慕尼黑 AWS 用户群演讲。
为工作选择正确的工具或服务在 IT 行业中是一项巨大的挑战——在各个行业的日常工作中亦是如此。在这篇博文中,我想要分享一些我们曾经在 Team Internet 利用 AWS 的巨大“工具箱”创建更佳解决方案和更高效解决问题的策略和实例。
使用现有资源还是创建新的资源? 一个艰难的决定
IT 工程师、架构师或开发者通常的日常工作是创建问题的解决方案或将业务流程转移到软件中。为实现这一目标,我们通常使用现有的架构或资源,并为其创建“附加组件”。
随着微服务架构日益增多,我们都了解到,对于扩展性和伸缩性而言,模块化和去耦合至关重要。这为我们带来了不同类型的软件架构。现实中,我们仍然倾向于使用现有资源,如现有(可能并未完全使用)Amazon EC2 实例的相同数据库,因为这似乎比新建材料更容易。
堆栈为“下一级微服务架构”?
我们在 Team Internet 未使用微服务架构的词汇,但倾向于讨论堆栈,为不同使用案例创建数据块。我们的方法是将微服务架构的想法与所有东西匹配,包括数据库和我们所需处理的特定问题所需的其他资源。
这不是“仅”将软件和代码划分为不同的模块。整个基础架构会独立基于不同的需求。整个基础架构的这些构成的每个部分都是我们的堆栈,在整个系统中与每个其他部分尽可能独立开来。只是与其他堆栈或基础架构部分形成松散的通信。
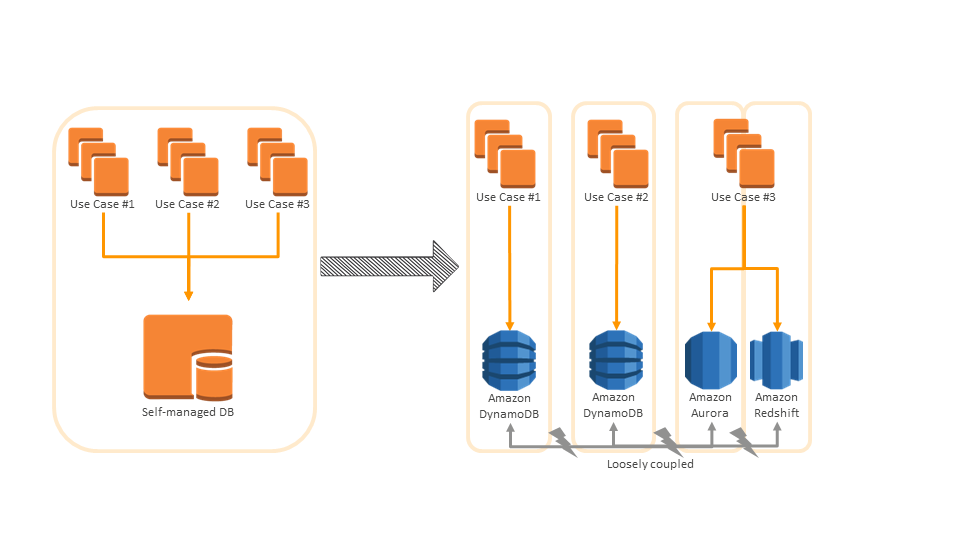
该理念体系的益处 = 独立和灵活
- 选择正确的部分。针对每个使用案例,我们可以选择对于特定挑战而言最合适的组件或服务,而无需围绕局限性开展工作。这对数据库来说确实如此,因为我们可以在整个面板中进行选择,而非尝试将需求挤压到并非为此而建的 DBMS 中。我们可以区分工作负载的不同需求,如重在写入 vs. 重在读取或架构 vs. 非架构数据。
- 任意重建。我们可以灵活重建整个堆栈,因为它们只是松散耦合的。因此,团队可以用新想法或服务创建概念验证,在生产工作负载中并行运行它们,无需妨碍或伤害生产系统。
- 降低成本。因为运行多种资源的操作开销由 AWS 负责(“无一致的繁重工作”),我们只需看一下服务定价。AWS 大多数价格方案在支持堆栈。对于数据库,您可以按吞吐量支付 (Amazon DynamoDB) 或按实例支付(Amazon RDS 等)。就吞吐量级别而言,很简单,只需在一个表格中将您的吞吐量分开到几个表格中,无需任何开销。就实例级别而言,定价是一次的,因此 r4.xlarge 是 r4.2xlarge 一半的价格。所以为什么不运行两个 r4.xlarge,将工作负载分开呢?
- 弹性设计。这个方法还有助于您的基础架构在默认情况下更可靠和更富弹性。因为不同堆栈相互独立,缩放比例更细粒度。通常会为更大系统的缩放提供更高的“安全缓冲”,失败只会发生于整个系统的一小部分(硬件、软件、打字输入等)中。
- 获得所有权。我们现在使用该方法论能看到的正面影响是在团队所有权和责任方面的积极影响。因为这些堆栈,使得查明问题和修正问题变得更容易,但每个堆栈的负责人也变得透明和清晰。
获得益处需要付出努力,为工作选择正确工具更是如此
每个方法都有缺点。在此,显而易见,创建这样的系统还需要进行额外开发和基础架构投入。
因此,我们决定始终将完美系统的目标铭记于心,拥有独立堆栈和堆栈之间的松散耦合进程。事实上,我们有时候会打破自己的规则,到处作弊。即使这样,有这个方法帮助我们创建更好的系统,至少知道到底在哪个点的时候,我们正面临着失去益处的风险。我希望文中的解释和见解能帮助您为工作选到正确的工具。