亚马逊AWS官方博客
利用Amazon SCT评估报告为 Babelfish 迁移做好准备
数据库迁移通常包括转换数据库架构并将数据从源数据库加载到目标数据库。迁移后,开发人员仍然需要更改应用程序以使用目标数据库驱动程序,并且他们经常需要重写应用程序代码才能使其全部正常工作。使用 Babelfish for Aurora PostgreSQL,您只需最少的架构更改即可从 SQL Server 迁移应用程序;Babelfish 是一款迁移加速器,可通过 TDS 协议在语义上正确执行 T-SQL,在 PostgreSQL 中原生实现。有关 Babelfish for Aurora PostgreSQL 的更多信息,请参阅使用 Babelfish for Aurora PostgreSQL。
Babelfish 不支持某些 SQL Server T-SQL 功能。因此,Amazon 提供了评估工具,用于对您的 SQL 语句进行逐行分析,并确定 Babelfish 是否不支持其中任何语句。
在这篇博文中,我们将演示如何使用 AWS Schema Conversion Tool (AWS SCT) 评估报告来提供此分析。您不需要使用 AWS SCT 进行架构转换 — BabelFish 原生理解 SQL Server T-SQL 方言。相反,AWS SCT 仅用于构建评估报告。
Babelfish 评估工具
对于 Babelfish 的评估工具,您有两种选择。一种选择是 Babelfish Compass 工具,它是 Babelfish 产品的一部分。当新版本的 Babelfish 上市时,还将推出最新版本的 Compass。相比之下,AWS SCT 将在一段时间后支持更新的 Babelfish 版本。Compass 还提供了一个功能,可以自动重写某些不受支持的 T-SQL 结构,以便 Babelfish 可以支持它们。另一种选择是内置于 AWS SCT 中的评估报告。两种工具都使用相同的基础 Babelfish 特征定义进行评估,但 Compass 通常提供更准确的结果。
对于熟悉 AWS SCT 并希望继续使用 AWS SCT 的用户,这篇博文将逐步介绍如何使用 Babelfish 的 AWS SCT 评估功能。
先决条件
- 我们在这篇博文中的用例涉及使用 AWS SCT 将 Northwind 数据库迁移到 Babelfish for Aurora PostgreSQL。 下载 DDL 并在您的 SQL Server 实例中创建此示例数据库,该数据库将用作本文的源数据库。
- 要遵循此解决方案,必须安装和配置 AWS SCT 以访问源 SQL Server 数据库。有关说明,请参阅安装 AWS SCT。
- 使用 PostgreSQL 13.6 版或更高版本创建 Babelfish 集群,然后使用 SQL Server Management Studio (SSMS) 或 sqlcmd 连接到 Babelfish 数据库,具体请参阅 Babelfish for Aurora PostgreSQL 入门。
解决方案概览
此项目配置过程包括以下主要步骤:
- 在 AWS SCT 全局设置中配置 JDBC 驱动程序。
- 创建源数据库连接和虚拟目标。
- 将源架构与 Babelfish 虚拟目标对应。
- 生成评估报告。
- 分析评估报告并查看操作项。
- 创建 Babelfish 集群。
- 创建数据库对象并加载 Babelfish 数据库。
- 验证迁移后的数据并测试其功能。
在 AWS SCT 全局设置中配置 JDBC 驱动程序
AWS SCT 需要 JDBC 驱动程序才能连接到源数据库和目标数据库。要在 AWS SCT 中配置驱动程序路径,请完成以下步骤:
- 下载并安装 JDBC 驱动程序。有关支持的驱动程序列表,请参阅安装所需的数据库驱动程序。
- 导航到 AWS SCT Settings(设置)页面上的全局设置。
- 在导航窗格中选择 Drivers(驱动程序),然后将文件路径添加到源和目标数据库引擎的 JDBC 驱动程序。在这篇博文中,我们添加了 SQL Server 驱动程序。

创建源数据库连接和虚拟目标
在 AWS SCT 版本 656 中,目标连接是可选的。此版本包括一项名为虚拟目标的新功能。虚拟目标允许无需先创建目标数据库即可运行评估。
要添加源数据库连接,请完成以下步骤:
- 启动 AWS SCT。
- 在 File(文件)菜单上,选择 New Project(新建项目)。

- 为您的项目输入一个名称,在本例中为
Babelfish Assessment,该名称存储计算机本地。 - 选择 OK(确定)创建 AWS SCT 项目。

- 选择 Add source(添加源)以将新的源数据库添加到 AWS SCT 项目。
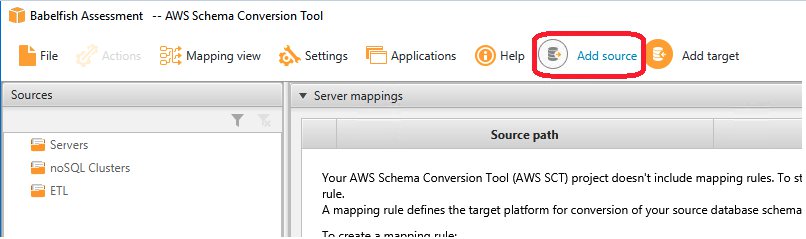
- 选择源数据库供应商(对于这篇博文,请选择 SQL Server)。

- 提供连接详情。
- 选择 Connect(连接)。
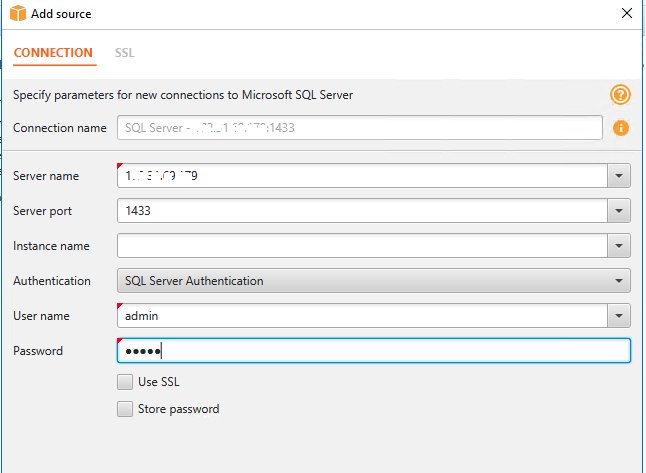
- 作为安全最佳时间,请选择 Configure SSL(配置 SSL)。
AWS SCT 使用安全套接字层 (SSL) 对线路上的数据进行加密,并使用客户端证书安全地存储数据库凭据。有关详细信息,请参阅作为源连接到 SQL Server。

- 在左窗格中选择源数据库和架构。

- 要添加虚拟目标,请在右窗格中选择 Servers(服务器),然后选择 <Babelfish (virtual)>。
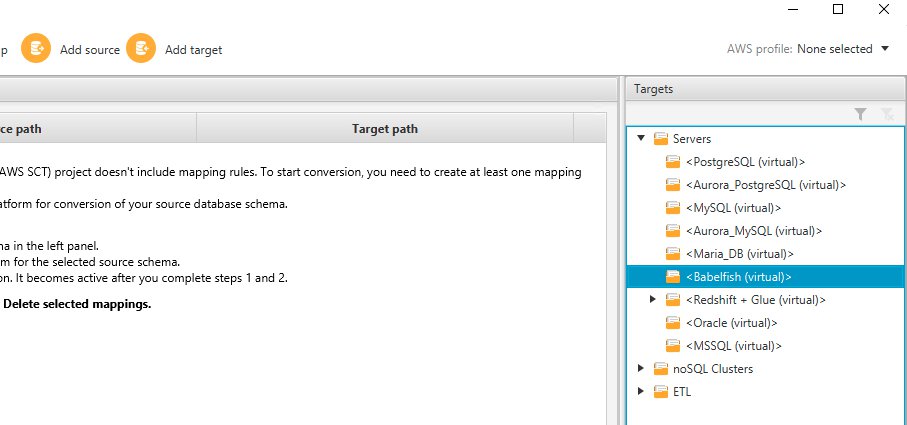
映射源和目标架构
在源树中,选择一个或多个用于映射的架构(右键单击)。选择 Create mapping(创建映射)为目标数据库平台创建映射。

创建映射后,映射视图将可用。选择服务器映射,然后选择 Main view(主视图)。

生成评估报告
创建映射后,可以生成评估报告。
- 展开 Servers(服务器)列表中的
Northwind数据库。 - 选择所需的架构。
- 选择架构(右键单击),然后选择 Create report(创建报告)。

分析评估报告并查看操作项
评估报告汇总了最新版本的 Babelfish 不支持的项的架构转换详细信息。您可以使用此报告来评估 Babelfish 支持的数据库代码和存储对象,以及完成转换所需的其他内容。您可以将数据库迁移评估报告的本地副本另存为 PDF 或 CSV 文件,以便在 AWS SCT 之外查看或与他人共享。
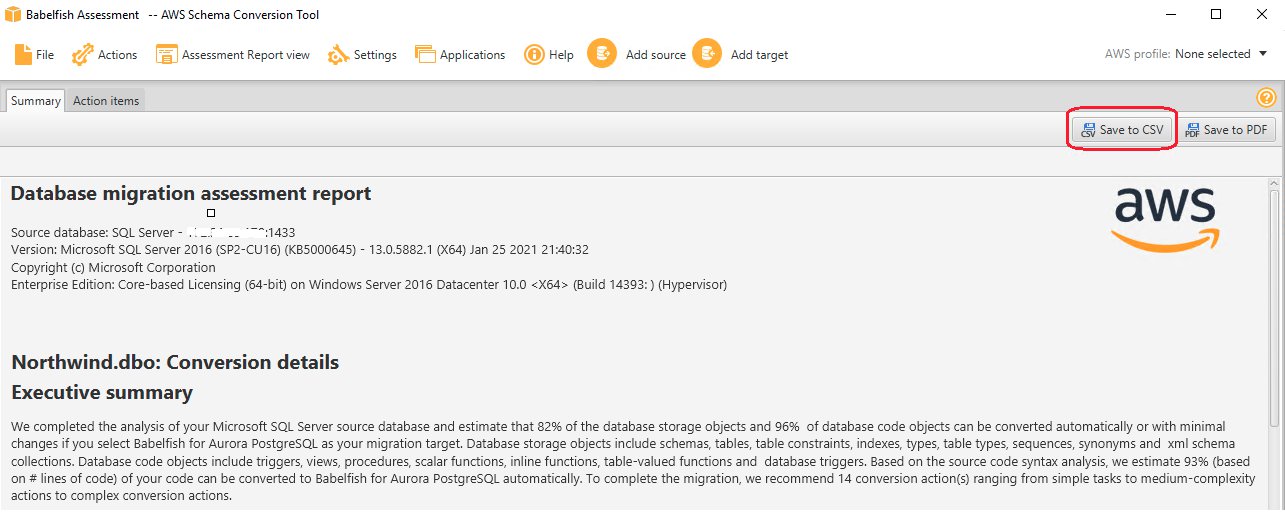
当您选择 Save to CSV(保存为 CSV)时,AWS SCT 将创建三个 CSV 文件。有关每个文件的更多信息,请参阅保存评估报告。

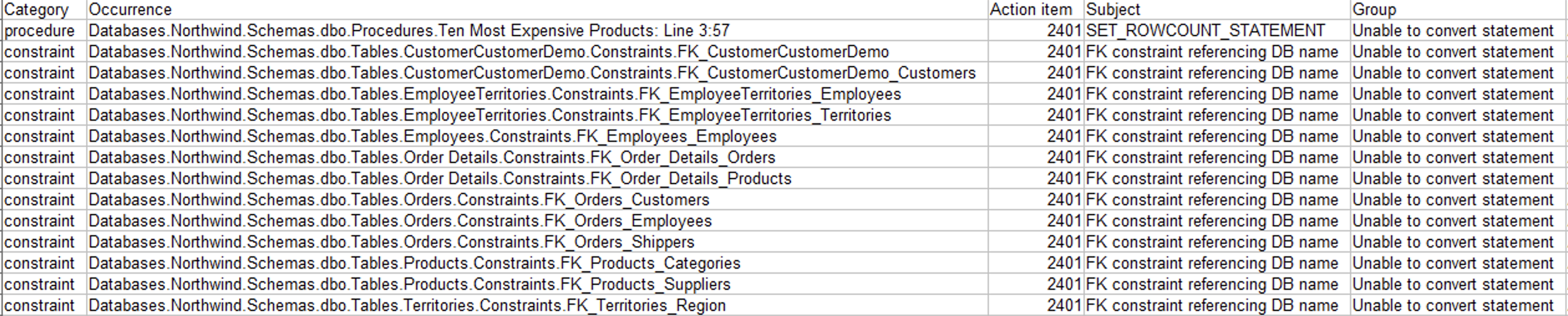
下表显示了操作项的类别。例如,AWS SCT 在架构中找到了 7 个过程,它告诉您,您可以在 Babelfish for Aurora PostgreSQL 中运行其中 6 个过程而无需进行任何代码更改,但其中 1 个确实需要更新。

以下示例显示了操作项的摘要。
在我们的案例中,AWS SCT 完成了对我们的 SQL Server 源数据库的分析,并估计 82% 的数据库存储对象和 96% 的数据库代码对象通过 Babelfish for Aurora PostgreSQL 兼容。数据库存储对象包括架构、表、表约束、索引、类型等。数据库代码对象包括触发器、视图、过程、标量函数、内联函数、表值函数和数据库触发器。根据源代码语法分析,AWS SCT 估计,我们 93% 的代码(基于代码行数)可以自动转换为 Babelfish for Aurora PostgreSQL。要完成迁移,请处理其余的转换操作,从简单任务到中等复杂操作再到复杂的转换操作。


在本例中,选择数据库代码对象中具有复杂操作的对象,这将显示相应的操作项。AWS SCT 通过添加带有红色背景的感叹号来指示具有复杂操作的对象。
在以下示例中,当前版本的 Babelfish for Aurora PostgreSQL 不支持 SET ROWCOUNT 语句。

选择问题,它将在底部窗格中显示相应问题的 SQL。

在本例中,我们将删除 SET ROWCOUNT 语句并更新 SQL。您可以用相同的方式验证其余的观测值,然后使用更新后的 DDL 填充 Babelfish 数据库。
您可以使用 AWS SCT 就地编辑数据库代码对象,如以下屏幕截图所示。但是,您无法使用 AWS SCT 编辑数据库存储对象。完成与数据库代码对象相关的操作项后,分阶段保存 SQL 文件,然后使用任何 SQL 编辑器处理数据库存储对象操作项。

将转换后的架构保存到文件中
您可以将转换后的架构作为 SQL 脚本保存到文本文件中。通过这种方法,您可以修改从 AWS SCT 生成的 SQL 脚本,以处理与数据库存储对象相关的项。然后,您可以在 Babelfish 数据库上运行更新后的脚本。
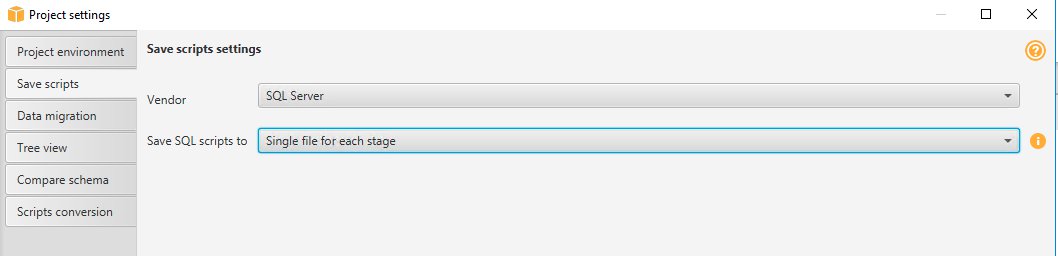
要选择 SQL 脚本的格式,请完成以下步骤:
- 在 Settings(设置)菜单上,选择 Project settings(项目设置)。
- 选择 Save scripts(保存脚本)。
- 对于 Vendor(供应商),选择 SQL Server。
- 对于 Save SQL scripts to(将 SQL 脚本保存到),选择 Single file per stage(每个阶段一个文件)。
- 选择 OK(确定)保存设置。
- 要将转换后的代码保存到 SQL 脚本,请在目标树上选择所需的架构(右键单击),然后选择 Save as SQL(另存为 SQL)。

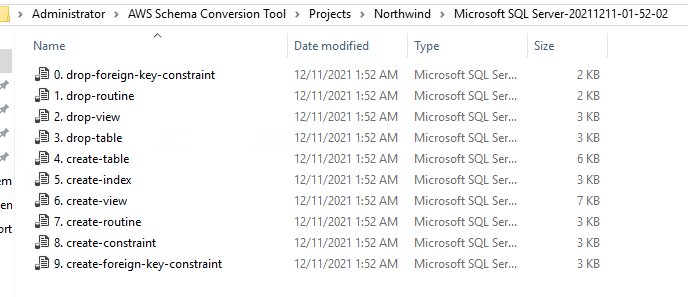
- 选择用于保存 SQL 文件的目录。在本例中,我们将它们保存在
C:\Users\Administrator\AWS Schema Conversion Tool\Projects\Northwind\Microsoft SQL Server-20211211-01-52-02中。
创建数据库对象并加载 Babelfish 数据库
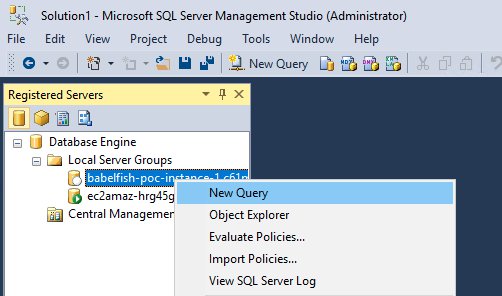
在以下示例中,我们在 SSMS 中使用注册服务器以简化使用。有关详细信息,请参阅创建新的注册服务器 (SQL Server Management Studio)。

将新创建的 Babelfish 端点添加到注册服务器后,右键单击 Babelfish 端点并选择 New Query(新建查询)。
我们使用以下命令创建名为 Northwind 的新数据库,因为从 AWS SCT 保存的 SQL 文件没有 create database 命令:
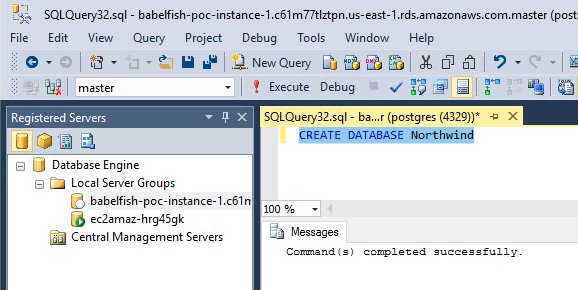
因为它是空数据库,所以我们忽略了从 AWS SCT 生成的 drop-* SQL 文件,并从 create table 脚本开始。在新查询中打开 create-table.sql 文件,确保连接到您的 Babelfish 端点并运行此脚本。

现在,这些表已在启用 BabelFish 的数据库中创建。让我们为这些表创建主键。打开 create-constraint.sql 文件并针对 Babelfish 端点运行。

创建表和主键约束后,让我们开始使用 SSIS 加载数据。成功加载数据后,您将运行 AWS SCT 生成的其余 SQL 文件。
运行 AWS SCT 生成的其余 SQL 文件
我们已经运行了 create-table.sql 和 create-constraint.sql 脚本(由 AWS SCT 生成)以在启用 BabelFish 的数据库中创建表和约束。让我们使用连接到 Babelfish 端点的 SSMS 查询编辑器运行其余的脚本。运行以下脚本以创建其余的数据库对象:
create-index.sqlcreate-view.sqlcreate-routine.sqlcreate-foreign-key-constraint.sql
验证迁移后的数据并测试其功能
运行 DDL 和 DML 之后,让我们确认在 TDS 和 PostgreSQL 端点之间是否可以看到相同的结果:
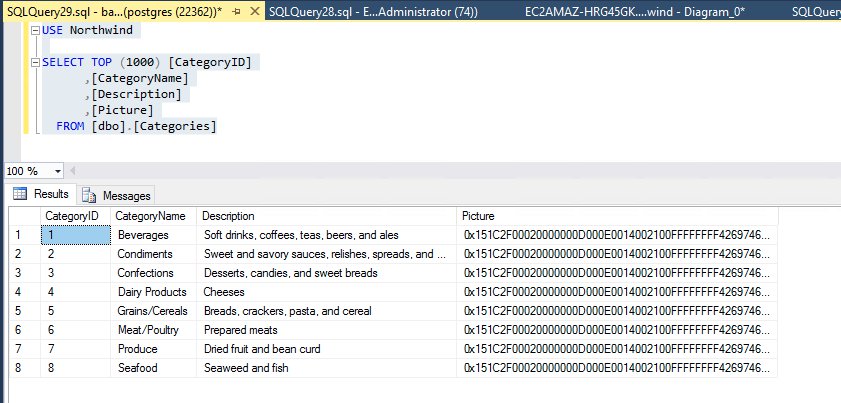
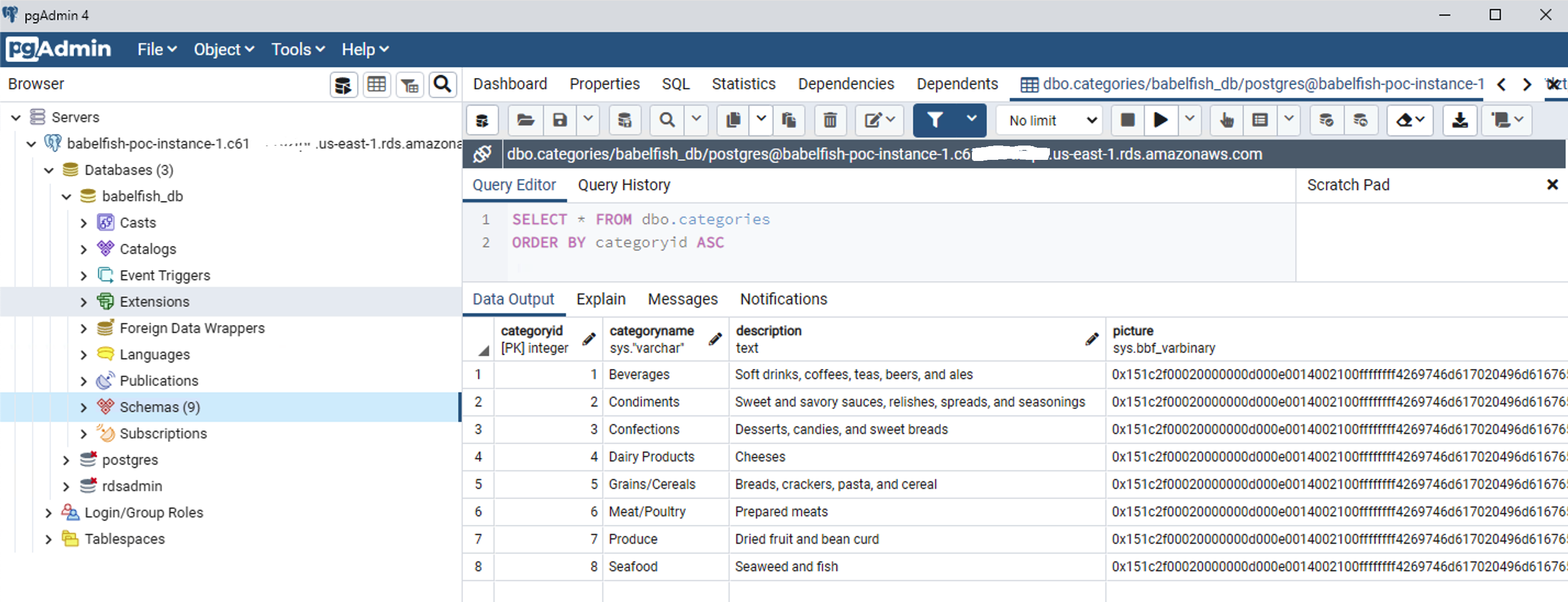
我们使用 pgAdmin 对 PostgreSQL 端点运行相同的查询。
小结
在这篇博文中,我们介绍了利用 AWS SCT 将 SQL Server 应用程序迁移到 Babelfish for Aurora PostgreSQL 所涉及的步骤。AWS SCT 评估报告可帮助您了解复杂程度和完成迁移所需的必要组件,以做出明智的决策。由于 Northwind 演示应用程序中的大多数 SQL 功能都受到 Babelfish 的支持,因此您可以毫不费力地将此应用程序迁移到 PostgreSQL 上的 Babelfish。
如果您有任何问题、意见或建议,请在评论部分发表评论。
关于作者
 Ramesh Kumar Venkatraman 是 AWS 的解决方案架构师,对容器和数据库充满热情。他与 AWS 客户合作设计、部署和管理其 AWS 工作负载和架构。业余时间,他喜欢和两个孩子一起玩,并且喜欢板球运动。
Ramesh Kumar Venkatraman 是 AWS 的解决方案架构师,对容器和数据库充满热情。他与 AWS 客户合作设计、部署和管理其 AWS 工作负载和架构。业余时间,他喜欢和两个孩子一起玩,并且喜欢板球运动。