亚马逊AWS官方博客
Amazon DocumentDB(兼容MongoDB)规模伸缩教程第一部分:读取规模伸缩
Original URL:https://aws.amazon.com/cn/blogs/database/scaling-amazon-documentdb-with-mongodb-compatibility-part-1-scaling-reads/
Amazon DocumentDB(兼容MongoDB)是一项快速、可扩展、高可用性的全托管文档数据库服务,可支持MongoDB工作负载。借助Amazon DOcumentDB,您可以直接运行与MongoDB完全相同的应用程序代码,并使用相同的驱动程序与工具。本文将向您介绍Amazon DocumentDB的现代云原生数据库架构如何帮助您以远超传统架构的方式更快、更灵活地扩展集群中的读取吞吐量。此外,本文还将提供接入Amazon DocumentDB集群并从中读取数据的相关建议。
Amazon DocumentDB云原生架构
与传统的单体式数据库不同,Amazon DocumentDB云原生架构将存储与计算分开。一个Amazon DocumentDB集群由一个分布式存储卷,与一个或者多个对该存储卷进行数据读取及写入的计算实例组成。下图所示为Amazon DOcumentDB集群,其中包含一个主实例与两个副本实例。

其中的计算实例负责处理用户请求,集群存储卷则为全体数据维护多达6个副本 (在3个可用区中各设有2个副本)以提供持久性。这套架构为读取与写入操作提供1个主实例,并可为读取操作提供最多15个读取副本,从而将每秒读取次数扩展至数百万级别。
由于Amazon DocumentDB实例不承载任何数据,因此您可以快速向集群当中添加或者删除新实例,且完全不涉及任何数据复制过程。您可以在短短几分钟内添加新的副本实例,或者调整现有实例的大小,而完全不必考虑其中的具体存储数据量。新实例通常能够在8到10分钟之内配置完成,并在正式启动后立即开始处理查询操作。Amazon DocumentDB的全托管方案还将利用这套架构实现硬件故障时的快速实例替换,其恢复速度也要远远高于传统数据库架构。
Amazon DocumentDB终端节点
Amazon DocumentDB支持三种终端结点类型:
- 集群终端结点——接入集群中的当前主实例;您可以利用主实例处理读取与写入操作。在接入集群时,我们通常建议使用此终端结点。
- 读取终端结点——跨越集群内所有可用副本的负载均衡只读连接。请不要使用读取终端结点,一般数据库驱动程序能够更好地对集群进行读取负载均衡。
- 实例终端结点——接入集群中的特定实例。适用于要求指向特定副本实例的一部分工作负载。
下图所示,为这些终端结点的对应架构: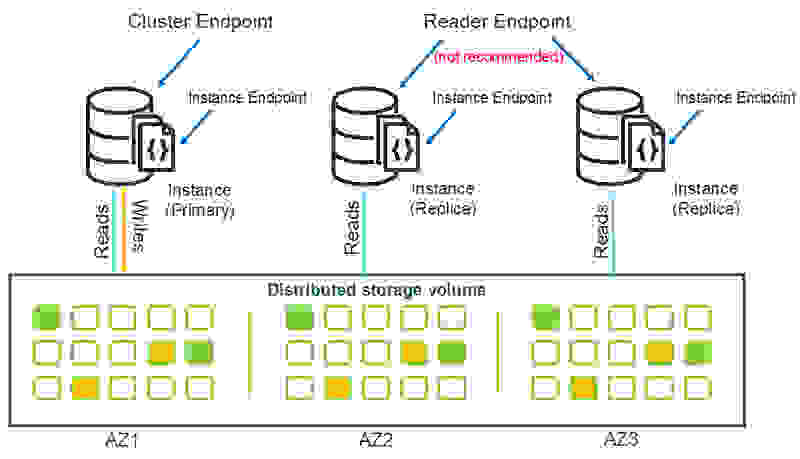
在故障转移期间,实例的角色(主实例或副本实例)可能发生变化,因此您的应用程序始终不要始终将某一特定实例终端结点假定为主实例。
相反,我们应使用集群终端结点,并将其以副本集的形式接入Amazon DocumentDB集群,以保证驱动程序能够自动发现集群中发生的拓扑变更。
作为副本集连接
Amazon DocumentDB支持模拟MongoDB副本集,意味着您的驱动程序可以自动发现集群拓扑(例如集群中包含多个实例、哪个为主实例、哪些为副本实例等)、该拓扑中正在进行的变更,并根据您的读取首选置进行读取负载分配。为了演示这项功能,本文将指引您使用Amazon EC2实例中的Python程序作为副本集接入Amazon DocumentDB集群、变更集群拓扑并通过程序的输出结果验证变更是否起效。
您只能在所处VPC之内访问Amazon DocumentDB集群。因此在本文中,请保证所使用的EC2实例与集群处于同一VPC当中。如果要从VPC之外访问集群,则需要采取其他步骤通过VPC对等、VPN或者SSH隧道等方式开启连接。关于更多详细信息,请参阅从Amazon VPC外部接入Amazon DocumentDB集群。
在本用例当中,请使用默认设置创建Amazon DocumentDB集群,包括跨多个可用区部署两个实例。关于创建集群的更多详细信息,请参阅Amazon DocumentDB入门指南。您还可以在集群所处的VPC内使用EC2实例。关于创建EC2实例的更多详细信息,请参阅Amazon EC2入门指南。
在创建并登录至您的EC2实例之后,您可以运行以下Python程序,以副本集形式接入集群并每分钟输出一次集群成员名单:
要使用副本集进行连接,脚本将使用集群终端结点,并在连接字符串中包含副本集名称rs0。如果收到连接错误,您需要检查安全组设置,确保其允许从EC2实例建立指向集群的正确连接。关于更多详细信息,请参阅对Amazon DocumentDB进行故障排查。
您可以运行自己的脚本,查看该脚本是否正常接入集群并识别出主实例及显示为SECONDARY的副本实例。具体请参考以下输出结果:
现在,您可以将其他副本添加到集群当中,并验证客户端在处于活动状态时能否自动发现这些副本。要向集群当中添加副本,请完成以下操作步骤:
- 在Amazon DocumentDB控制台上,选定您的集群。
- 在Actions下拉菜单中,选择Add instances。

- 在Instance identifier部分,输入实例名称。
- 在Instance class部分,输入适当的类型。本文使用默认选项r5.large。
- 在Promotion tier部分,直接使用默认的No preference选项。
- 选择Create。



新添加的副本实例通常会在10分钟以内可用。参考以下输出结果,程序已经自动发现新的副本实例:
从该用例可以看出,当我们对实例进行横向(添加或移除读取副本)或纵向(上调或下调实例大小)规模伸缩时,MongoDB驱动程序会自动从集群拓扑中检测到相应变更,无需进行任何额外操作。
读取首选项
在以副本集的形式接入Amazon DocumentDB时,我们可以在连接字符串中指定读取首选项,借此设置应用程序在遍历集群实例时如何处理来自应用程序的读取请求。
我们可以从以下五种读取首选项中做出选择:
- primary——指定
primary读取首选项,可保证所有读取操作都被路由至集群的主实例处。如果主实例不可用,则读取操作将失败。 - primaryPreferred——在正常操作下,指定
primaryPreferred读取首选项将把读取操作路由至主实例。如果主实例发生故障转移,则客户端会将请求路由至副本实例。 - secondary——指定
secondary读取首选项,可确保读取操作只被路由至副本实例处,而永远不会指向主实例。如果集群中不存在副本实例,则读取请求失败。 - secondaryPreferred——指定
secondaryPreferred读取首选项,将确保读取请求在有一个或者多个副本实例处于可用时被路由至只读副本处。如果集群中没有可用的副本实例,则读取请求将被路由至主实例。 - nearest——指定
nearest读取首选项时,读取请求的路由路径将仅根据客户端与Amazon DocumentDB集群中所有实例间的延迟结果决定。
若需了解更多详细信息,请参阅Amazon DocumentDB读取首选项。
之前的代码示例中使用的是readPreference=secondaryPreferred,意味着在以副本集形式接入Amazon DocumentDB时,优先使用指定secondaryPreferred读取首选项。关于更多最佳实践详细信息,请参阅Amazon DocumentDB最佳实践。
在使用secondaryPreferred读取首选项的情况下,客户端会自动将读取查询路由至您的副本实例,并将查询结果写入至主实例。这能更好地利用集群资源,允许主实例单纯处理大量写入操作。如果集群中不存在只读副本(例如单节点集群,或者集群中的唯一只读副本出现故障),那么在使用secondaryPreferred读取首选项的情况下,客户端会自动将读取流量路由至主实例。
从Amazon DocumentDB副本中读取到的数据遵循最终一致性。在某些情况下,应用程序需要实现写入操作后的读取一致性,只有Amazon DocumentDB主实例才能实现这样的要求。在此类用例中,可以在应用程序中创建两个客户端连接池:一个用于需要写入操作后一致性(readPreference=primary)的写入与读取操作,另一个用于需要最终一致(readPreference=secondaryPreferred)的读取操作。或者,您也可以在特定集合内覆盖掉原有读取首选项。关于更多详细信息,请参阅多连接池机制。
总结
本文阐述了Amazon DocumentDB采用的独特架构如何帮助用户将读取流量路由至副本实例,借此扩展集群吞吐量。要充分发挥这一优势,应使用MongoDB驱动程序中的内置功能以副本集形式接入集群,并设置适当的读取首选项。