亚马逊AWS官方博客
手把手教你玩转 Kubeflow on EKS(一)
本文为手把手教你玩转Kubeflow On EKS 系列文章的第一篇。
1. 前言
伴随着人工智能时代的来临,越来越多的业务场景需要我们利用 AI 技术去支持,Gartner 在2019年发布的一份关于AI的预测报告中指出,在过去的一年里,采用AI的企业数量增加了两倍,而AI成为了企业CIO们考虑的头等大事。CIO在企业内实施AI应用的过程里,必须考虑的五个要素中就有两项与Kubernetes相关:
- AI将决定基础架构的选型和决策。在企业对AI的使用正在迅速增加的背景下,到2023年,人工智能将成为驱动基础架构决策的主要工作负载之一。加快AI的落地,需要特定的基础设施资源,这些资源可以与AI以及相关基础设施技术一起同步发展。我们认为,以Kubernetes强大的编排以及对AI模型的支持能力,通过在互联网厂商以及更多客户总结的最佳实践,Kubernetes将成为企业内部AI应用首选的运行环境和平台。
- 容器和Serverless将使机器学习模型作为独立的功能提供服务,从而以更低的开销运行AI应用。Gartner直接指出了将容器作为机器学习模型的优势和趋势。
Amazon Elastic Kubernetes Service(Amazon EKS)是一项安全、可靠、可扩展的完全托管的Kubernetes服务,近期在AWS中国区域落地以来获得了用户的广泛关注。Amazon EKS可让您在 AWS 上轻松运行 Kubernetes,无需您自行支持或维护 Kubernetes 控制层面,EKS可跨多个AWS可用区来提供高可用特性,并自动将最新的安全补丁应用到您的集群控制平面,因此您可以更专注于应用程序的代码和功能,由于其安全性、可靠性和可扩展性,许多企业在 EKS上 运行任务关键型应用程序。特别在近两年,有越来越多的公司用kubernetes来运行各种各样的工作负载,尤其是机器学习领域。各种 AI 公司或者互联网公司的 AI 部门都会尝试在 Amazon EKS上运行 TensorFlow、PyTorch、MXNet 等等分布式学习的任务。使用Amazon EKS对机器学习的训练任务进行管理有如下好处:
- 有效利用资源- Amazon EKS能够跟踪不同工作节点的属性,例如存在的CPU或GPU的类型和数量,在将作业调度到节点时,Kubernetes会根据这些属性,对资源进行有效分配。
- 隐藏复杂性– 容器提供了一种独立于语言和框架的,有效打包机器学习工作负载的方式,从而屏蔽掉机器学习任务对底层技术栈的依赖。Kubernetes则提供了一个可靠的工作负载编排和管理平台,Amazon EKS通过必要的配置选项、API和工具来管理这些工作负载,从而使工程师可以通过yaml文件,即可控制这些上层ML应用
- 资源隔离 -通过Amazon EKS的命名空间的功能,可以将单个物理Kubernetes集群划分为多个虚拟集群,使单个集群可以更轻松地支持不同的团队和项目,每个名称空间都可以配置有自己的资源配额和访问控制策略,满足复杂的多租户需求,从而能更充分地利用各种底层资源
- 弹性伸缩-对于机器学习这种资源密集型工作负载,Amazon EKS最适合于根据工作负载随时自动扩展或收缩计算规模,相对于虚拟机或物理机而言,通过容器完成扩展和收缩更为平稳、快速、简单
- 存储持久化 -Amazon EKS提供了将存储连接到容器化工作负载的基本机制,持久卷PV提供了Kubernetes对有状态应用程序(包括机器学习)的基本支持。
Amazon Elastic Kubernetes Service自身强大的资源调度能力能够很好的帮助企业解决机器学习平台和资源的一致性,扩展性,移植性问题,然而部署和使用针对机器学习进行优化的Kubernetes平台,并支撑机器学习模型开发、构建、训练以及部署,却绝对不像说起来这么轻松,数据科学家有许多相同的关注点:可重复的实验(比如可重复的构建);可移植和可复制的环境(如在开发、过渡和生产环境中具有相同的设置);凭证管理;跟踪和监控生产环境中的指标;灵活的路由;轻松扩展。这为Amazon EKS上运行机器学习负载带来了很大的挑战。

而Kubeflow的出现很好解决了在kubernetes上运行机器学习负载面临的挑战,Kubeflow是一个为 Kubernetes 构建的可组合,便携式,可扩展的标准的云原生机器学习平台。kubeflow于2017年12月在KubeCon美国大会上宣布开源,并在过去两年中迎来了远超预期的迅猛发展。特别是Kubeflow的首个主要版本1.0版本的正式发布,kubeflow1.0版本是一个里程碑,能够全面支撑起用户在机器学习开发、构建、训练与部署这个完整的使用过程。kubeflow的目标是让Kubernetes做它擅长的事情,Kubeflow致力于让Kubernetes上进行的机器学习任务组件化、可移植、可扩展,让机器学习(ML)模型的规模化和部署到生产尽可能简单,例如:
,它的优势具体体现在以下几个方面:
- 在不同的基础设施上进行简单、可重复、可移植的部署(例如,在本地进行试验,然后迁移到本地集群或云上)
- 部署和管理松耦合的微服务,实现了Cloud Native ML的云原生,即本地训练好的模型,可以一键上云,使得本地开发和云开发在一个环境中,效率大大提高,机器学习(ML)工程师和数据科学家可以轻松地利用aws云资产(Amazon EKS)来处理ML工作负载
- 简化了在 Kubernetes 上面运行机器学习任务的流程, 实现了一套完整可用的自动化流水线
- 可扩展性好,能满足内部业务的定制化需求,自动调配计算资源,按需缩放
在强大的贡献者社区的支持下, 企业可以在任何符合Kubernetes的群集上使用Kubeflow,Kubeflow提供了一种在Kubernetes上运行机器学习工作负载的简单、可移植和可伸缩的方法,使机器学习(ML)工作流在Kubernetes上的部署变得简单、可移植和可伸缩。Kubeflow可以帮助企业在软件开发和机器学习之间的通用基础架构上实现标准化,并在机器学习生命周期的每个步骤中利用开源数据科学和云原生生态系统。
在kubeflow1.0版本中,一组核心应用组件已经能够稳定运行,包括Katib(超参数优化),KFServing(模型服务),Fairing(SDK),Kubeflow管道,kfctl(控制平面),清单配置,TF-Operator和PyTorch-operator(模型训练),能够高效支持企业在Kubernetes上的模型开发、构建、训练以及部署。Kubeflow的1.0版本将全面支撑起用户的开发、构建、训练与部署这个完整的使用过程。
Kubeflow 1.0正式毕业的应用组件包括:
- Kubeflow的UI,即集中仪表板
- Jupyter notebook控制器与Web应用
- 用于分布式训练的Tensorflow Operator(TFJob)以及PyTorch Operator
- 用于部署以及升级的kfctl
- 用于多用户管理的配置文件控制器与UI

如图所示,Kubeflow 1.0允许用户使用Jupyter来开发模型,使用Fairing之类的Kubeflow工具(Kubeflow的python SDK)来构建容器,并创建Kubernetes资源来训练他们的模型,定义复杂的ML工作流的管道用于跟踪数据集,作业和模型的元数据,katib用于超参数调整,最后使用KFServing,在Knative来创建并部署服务器进行推理。
在本系列文章中,您将学习到:
- 实现在Amazon EKS中国区部署和创建Kubeflow,在Kubeflow中创建并使用Jupter笔记本,在笔记本中使用TensorFlow运行一个单节点培训和推理。
- 实现从创建托管的Jupyter笔记本,用kubeflow fairing远程构建模型训练镜像,用TFJob 实现分布式训练用于图像分类的MNIST机器学习模型,用TensorFlow Serving一键式模型部署以及应用界面集成进行在线预测的一个端到端机器学习的完整过程。
- 实现通过Kubeflow pipeline集成Amazon Sagemaker实现端到端的机器学习过程,包括如何在kubeflow notebook笔记本中安装Pipeline SDK,构建和编译Kubeflow Pipeline,调用SageMaker超参数优化组件进行超参数优化,训练模型和创建模型,并在Amazon SageMaker中批量推理和部署模型端点。
2.在Amazon EKS中国区安装和部署Kubeflow
1)先决条件
首先,您需要设置 Amazon Elastic Kubernetes Service (Amazon EKS) 集群。在本演示中,我们将使用 eksctl 来启动集群。本文需要的软件环境有 aws cli , eksctl ,kubectl,e aws-iam-authenticator以及eks对应操作的IAM权限。具体安装步骤请参考2020_EKS_Launch_Workshop/步骤1-准备实验环境。安装完必备工具之后,启动 Amazon EKS 集群。在本例中,我们会将集群部署到 cn-northwest-1(即 AWS 中国宁夏区域)中。
本文选择了缺省的kfctl配置文件,以简化kubeflow安装。但是,我们建议在企业生产环境中安装Cognito配置并添加身份验证和SSL(通过ACM),有关启用Cognito所需的其他步骤,请参阅Kubeflow documentation文档。
2)设置环境变量
执行以下命令来设置环境变量,设置Kubeflow应用程序目录
3)使用eksctl创建EKS集群
由于Kubeflow需要较多的计算节点资源来部署,通过执行以下操作创建一个4个工作节点EKS集群,创建过程大约需要十几分钟,请耐心等待。
获取EKS工作节点role,配置环境变量用于后续使用
4)安装kubeflow
下载kfctl工具用于kubeflow部署和升级
替换kfctl_aws.yaml中的region和role为当前的创建eks的region和node节点使用的role
检查kfctl_aws.yaml是否正确替换
kfclt 本质上是使用了 kustomize 来安装,kustomize的设计目的是给kubernetes的用户提供一种可以重复使用同一套配置的声明式应用管理,可以通过kfctl build生成kubeflow kustomize配置文件
由于网络问题,海外gcr.io, quay.io的镜像可能无法下载,需要通过修改镜像的方式安装,把镜像url替换成aws国内镜像站点url:
运行kfctl apply开始在EKS上安装和部署kubeflow
kfctl apply -V -f ${CONFIG_FILE}
安装Kubeflow及其工具集可能需要数分钟。有一些的pod最初可能会出现Error或CrashLoopBackOff状态。需要一些时间,它们会自动修复,并进入运行状态。
5)配置kubeflow dashboard
Kubeflow dashboard通过在istio中的ingress gateway将服务暴露给外部使用,运行下列命令检查ingress gateway状态
6)验证kubeflow是否成功部署
运行下面的命令检查状态,如果过一段时间后仍不正常,请通过查看日志进行故障排除。
kubeflow提供多租户支持,用户无法在Kubeflow的默认名称空间中创建笔记本。
第一次访问kubeflow时,可以使用一个匿名命名空间。如果您想要创建不同的jupter用户空间,您可以创建配置文件,然后运行kubectl apply -f Profile .yaml。kubeflow配置文件控制器将创建新的名称空间和服务帐户,允许在该名称空间中创建笔记本。
7)访问Kubeflow用户界面
从本地网络浏览器输入http://127.0.0.1:8080/,您就可以进入到Kubeflow UI界面,Kubeflow dashboard默认为无身份验证。点击dashboard中 Start Setup,设置namespace 的值为 eksworkshop

点击 Finish 浏览kubeflow dashboard

8)创建和使用jupter notebook
Jupyter笔记本通常用于数据清洗和转换、数值模拟、统计建模、数据可视化、机器学习等。利用Kubeflow,每位数据科学家乃至数据团队都将拥有自己的命名空间,在其中轻松运行工作负载。命名空间提供强大的安全保障与资源隔离机制。利用Kubernetes资源配额功能,平台管理员能够轻松限制个人或者团队用户的资源消耗上限,以保证资源调度的公平性。使用Kubeflow 1.0,开发人员可以使用编程笔记本平台Jupyter和Kubeflow工具(例如Kubeflow的Python软件开发工具包)来开发模型,构建容器并创建Kubernetes资源来训练那些模型,在Kubeflow dashboard中通过点击 Create a new Notebook server可以轻松创建一个jupyter笔记本的实例:
 选择您在上一个部步骤中创建的 namespace :
选择您在上一个部步骤中创建的 namespace : 为创建的jupter笔记本指定一个名称:
为创建的jupter笔记本指定一个名称:
 kubeflow提供了tensorflow和pytorch的默认镜像,选择tensorflow默认的Image如下:
kubeflow提供了tensorflow和pytorch的默认镜像,选择tensorflow默认的Image如下:

aws已经默认提供如下的docker镜像:
为创建的jupter笔记本设置内存和cpu资源 ,设置CPU值为 1.0,Memory为1G

滚动到底部,接受所有其他默认设置,然后单击LAUNCH,等待jupter笔记本启动,启动成功后,点击CONNECT
 在jupter笔记本界面里点击 New, 选择 Python3,创建一个新的Python 3环境的 Jupyter笔记本
在jupter笔记本界面里点击 New, 选择 Python3,创建一个新的Python 3环境的 Jupyter笔记本

9)训练模型
将实例代码粘贴到notebook中. 这段Python样例代码会使用TensorFlow基于MNIST数据集训练模型,点击Run运行训练代码。
运行后会创建一个新的代码单元格,在这个新单元格中输入main(),然后单击Run
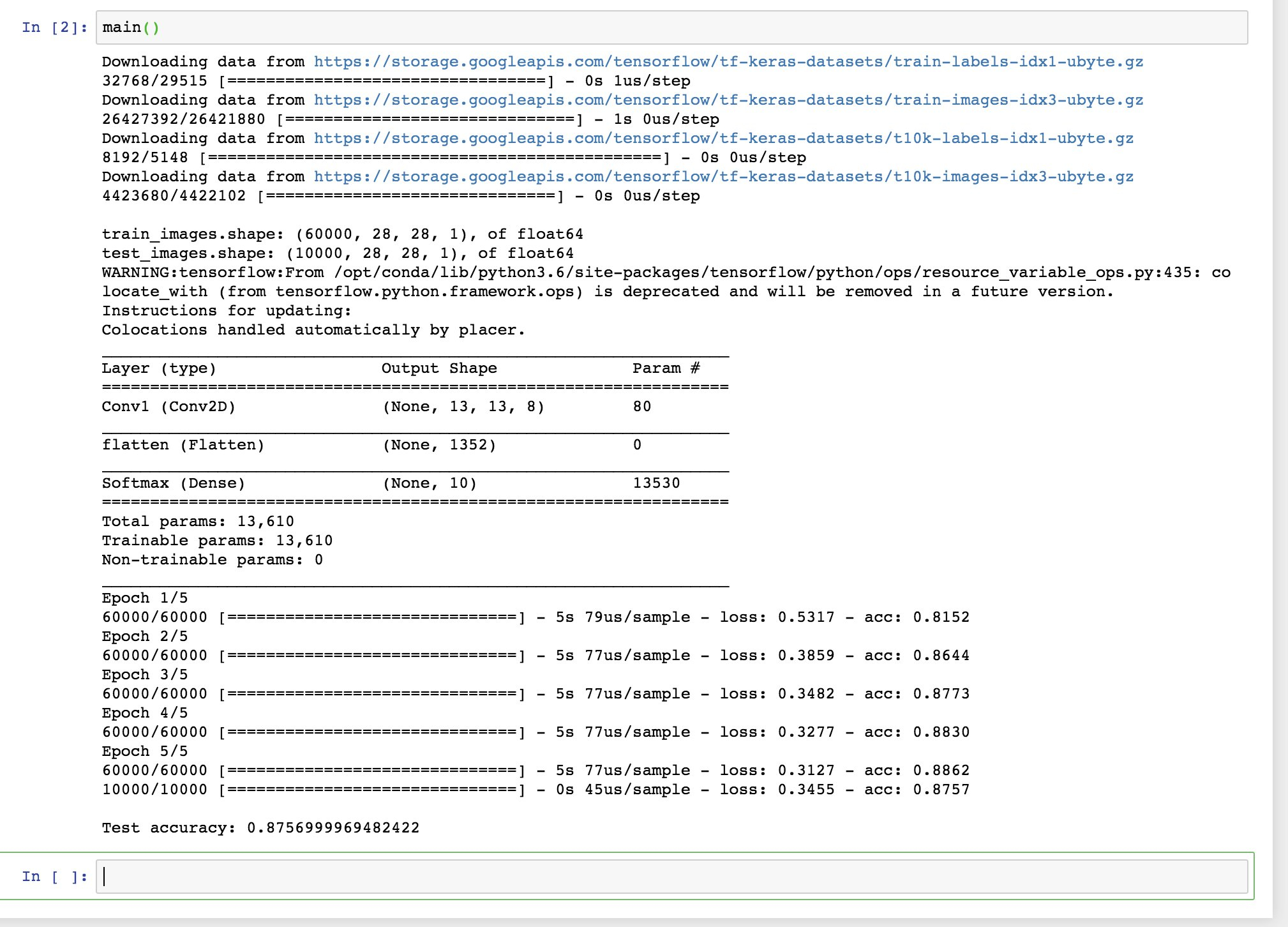
上面是输出结果,输出的前几行显示下载了mnist数据集,下载的训练数据集是60000个图像,测试数据集为10000个图像,并给出了用于训练的超参数,五次Epoch的输出,最后在训练完成后输出了模型的损失值和准确率(Accuracy)。
3.小结
Amazon EKS是一个完全托管的Kubernetes服务,该服务自身强大的资源调度能力能够很好的帮助企业解决机器学习平台和资源的一致性,扩展性,移植性问题,而Kubeflow 是在 Kubernetes 上运行 TensorFlow、JupyterHub、Seldon 和 PyTorch 等框架的一种很好的方式,Kubeflow很好解决了在kubernetes上运行机器学习负载面临的挑战,全面支撑起用户在机器学习开发、构建、训练与部署这个完整的使用过程。在本文中实现了在Amazon EKS中国区部署和创建Kubeflow 1.0,在Kubeflow中创建并使用Jupter笔记本,并在笔记本中使用TensorFlow在Kubeflow中运行一个简单的模型训练。
4. 资料参考
https://eksworkshop.com/tags/opn401/
https://www.kubeflow.org/docs/
https://github.com/kubeflow/pipelines/tree/master/components/aws/sagemaker
https://medium.com/Kubeflow/Kubeflow-1-0-cloud-native-ml-for-everyone-a3950202751
https://cloud.google.com/blog/products/ai-machine-learning/getting-started-kubeflow-pipelines