背景
文本分类(Text Classification) 属于自然语言处理领域,是指计算机将载有信息的一篇文本映射到预先给定的某一类别或某几类别主题的过程。然而在现实问题中,经常会遇到数据样本的类别不平衡 (class imbalance) 现象,严重影响了文本分类的最终结果。所谓样本不均衡指的是给定数据集中有的类别数据多,有的数据类别少,且数据占比多的数据类别样本与占比小的数据类别样本两者之间达到较大的比例。
BlazingText 是 AWS SageMaker 的一个内置算法,提供了 Word2vec 和文本分类算法的高度优化的实现。本文使用了 Sagemaker BlazingText 实现了文本多分类。在样本不均衡问题上,使用了回译和 EDA 两个方法对少类别样本进行了过采样处理,其中回译方法调用了 AWS Translate 服务进行了翻译再翻译,而 EDA 方法主要使用同义词替换、随机插入、随机交换、随机删除对文本数据进行处理。 本文也使用了AWS SageMaker 的自动超参数优化来为 BlazingText 的文本分类算法找到最优超参数。
本文使用基于 DBpedia 的公开数据集处理生成的含有14个类别的不均衡文本数据,并进行了不做任何样本不均衡处理的 Baseline 实验和包含回译和 EDA 两个方法的过采样实验。
在这个案例中,使用的数据集是根据文章的标题和摘要进行作者的多分类。然而,本文提出的文本分类方法适用于任何样本不均衡的文本分类场景,比如:
- 垃圾邮件分类,实际数据中只有少部分邮件是垃圾邮件;
- 根据诊断报告疾病预测,真实的临床数据中也只有少部分数据真的患有某种疾病;
- 新闻分类,对网站的大量新闻进行分类判断是属于经济的,还是文化的等,但是不同网站类别偏差较大,比如娱乐网站娱乐新闻偏多,但是也会有其他类别的新闻。
方案架构图

环境准备
进入 AWS SageMaker Console 创建一个笔记本实例,填写笔记本名为 UnbalancedTextMulticlassification,并选择实例类型,本案例选择 ml.c5.xlarge,此外,还需要为笔记本准备一个 IAM role,由于本案例需要调用 S3 以及 Translate,因此需要给该 IAM role 赋予 S3FullAccess 和 TranslateFullAccess 两个权限。

笔记本创建完成后,点击 Open JupyterLab 进入Jupyter 编辑界面。
下载并生成不均衡数据集
首先下载 DBpedia 的原始数据集,一共有14个类别,对每个类别就进行随机取样,最后生成一个不均衡的包含14个类别的数据集。
import pandas as pd
!wget https://github.com/saurabh3949/Text-Classification-Datasets/raw/master/dbpedia_csv.tar.gz
!tar -xzvf dbpedia_csv.tar.gz
origin_df = pd.read_csv('dbpedia_csv/train.csv')
grouped = origin_df.groupby('label')
new_df = grouped.get_group(1)
# 对每个label随机取样,以lable2为例
group2 = grouped.get_group(2)
new_group2 = group2.sample(n=38000)
new_df = new_df.append(new_group2)
# 保存处理后的不均衡数据集
new_df.to_csv("original_dataset/dataset.csv", index=0)
数据集分析
查看数据集的基本内容以及数据集大小。
step1_df = pd.read_csv('original_dataset/dataset.csv')
print("行数:" + str(step1_df.shape[0]))
step1_df.head()
可以看到处理后的数据集共包含188020行数据,共有三列数据,第一列为类别,第二列对文章标题,第三列为文章摘要。

查看数据集的类别分布情况,包括每个类别的数量,并画好分布图。
import matplotlib.pyplot as plt
count_classes = pd.value_counts(step1_df['label'], sort = True)
print(count_classes)
count_classes = step1_df.label.value_counts()
count_classes.plot(kind = 'bar')
plt.title("label distribution")
plt.xlabel("Class")
plt.ylabel("Frequency");
从结果中可以看到目前的数据集14个类别分布及其不均衡,数量最多的类别有40000个,而数量最少的类别只有20个。
数据预处理
数据预处理包含:1.去掉空行;2.大小写统一;3.分词;4.转化为BlazingText的数据集格式
首先创建从整数索引到类标签的字典映射,其次创建从整数索引到以“label”开头的类标签的字典映射
index_to_label = {}
with open("original_dataset/classes.txt") as f:
for i,label in enumerate(f.readlines()):
index_to_label[str(i+1)] = label.strip()
print(index_to_label)
index_to_label_final = {}
for key in index_to_label:
index_to_label_final[key] = "__label__" + str(index_to_label[key])
print(index_to_label_final)
输出结果如下所示。

对数据集进行分词、去空行、统一大小写,并且转换为 Sagemaker BlazingText 接受的格式。
def tokenize(series):
for index, value in series.items():
series[index] = nltk.word_tokenize(value.lower())
return series
def preprocess(step1_df):
step1_df = step1_df.dropna(axis=0)
step2_df = pd.DataFrame()
step2_df['label'] = step1_df['label']
step2_df['label'] = step2_df['label'].map(str).map(index_to_label_final)
step2_df['sentence'] = step1_df["title"].map(str) +","+ step1_df["abstract"].map(str)
step2_df['sentence'] = tokenize(step2_df['sentence'])
return step2_df
step2_df = preprocess(step1_df)
step2_df.head(10)
# 预处理后的数据集作为baseline实验的数据集
step2_df.to_csv("baseline_dataset/dataset_baseline.csv", sep=" ", header=0, index=0)
数据预处理的结果如下图所示。

本环节数据预处理之后的数据集即可作为 Baseline 实验的数据集。
处理样本不均衡
样本不平衡的解决思路一般有两种:
- 从数据层面缓解不平衡的状况::一,欠采样,去除数量过多的样例。二,过采样,扩充数量较少的样例
- 阈值移动,就是对阈值进行调整。直接基于原始数据训练,进行预测时,用样例的真实观测几率来修正阈值。
由于本文使用的是 SageMaker 的内置算法,无法修改算法本身,因此考虑从数据层面解决样本不均衡问题。由于本次数据集中某些类别数量过少,因此采用过采样的方法。而在过采样方法中,又选择了回译和 EDA 两种方法。
过采样倍数计算方法
由于过采样需要对原数据进行扩充,而过采样处理后的数据又需要和原数据保持一定规律,本文提出了一种数据增强倍数的取值n的计算方法:
- 原始数据各个类别呈递减状态,即使经过上采样处理后的数据也要保持原始数据的一定规律
- 假设最大类别的数量为a,类别种类为b,最小类别增强后的数量保持在a/3和a/2之间
- 过采样后的数据为等差递减数列,公差在 (a-a/3)/b 到 (a-a/2)/b 之间,取一个整数为c
- 增强后数据分布:y(x) = a – c(x-1)
- n = math.floor ( y(x) / x类别的当前值)
import math
'''
计算n值
'''
def calcu_n(name):
num = get_num_from_name(name)
current_num = group.label.value_counts().iloc[0]
expected_num = 40000-2000*(num-1)
n = math.floor(expected_num/current_num)
return n
过采样方法一:回译
所谓回译即对原句子进行一次翻译,再翻译回原来的语言,比如英文句子翻译成中文,再翻译回英文,就可以得到一个新的语义一致的句子。本文采用 AWS Translate 实现回译,由于目前 Translate 支持55种语言,因此一层回译最多可以有54个结果,但是某些情况下回译结果会和原句子一样,因此需要增加去重工作,实测去重后一般一个句子也可以达到扩充为20-40倍之间。
import random
import boto3
translate_client = boto3.client('translate')
# AWS Translate除了english(en)之外还支持54种语言
available_lang = ["af","sq","am","ar","az","bn","bs","bg","zh","zh-TW","hr","cs","da","fa-AF","nl","et","fi","fr","fr-CA","ka","de","el","ha","he",
"hi","hu","id","ja","ko","lv","ms","no","fa","ps","pl","pt","ro","ru","sr","sk","sl","so","es","es-MX","sw","sv","tl","ta","th","tr","uk","ur","vi"]
'''
回译函数
'''
def back_translate(text, sourceLanguageCode, targetLanguageCode):
response1 = translate_client.translate_text(
Text = text,
SourceLanguageCode = sourceLanguageCode,
TargetLanguageCode = targetLanguageCode
)
translation_text = response1['TranslatedText']
response2 = translate_client.translate_text(
Text = text,
SourceLanguageCode = targetLanguageCode,
TargetLanguageCode = sourceLanguageCode
)
return response2['TranslatedText']
'''
对54次回译结果去重,并从set结果中选择n个包含原句子的句子
'''
def get_translation_set(text, n):
translation_set = set()
translation_set.add(text)
for language in available_lang:
result = back_translate(text, "en", language)
translation_set.add(result)
translation_set.remove(text)
if n-1 <= len(translation_set):
translation_set = set(random.sample(translation_set, n-1))
translation_set.add(text)
return translation_set
'''
得到对应label的回译list
return: [[label,sent1],[label,sent2]...]
'''
def get_label_translation_list(label, sentences, n):
result = []
for text in sentences:
translation_set = get_translation_set(text, n)
for tanslation in translation_set:
result.append([label,tanslation])
return result
过采样处理二:EDA
EDA 是常用的文本扩充方法,主要包含四种处理手段:同义词替换、随机插入、随机交换、随机删除。本文直接使用一个开源的 EDA 工具进行文本扩充。
from shutil import copyfile
# 下载 eda 工具
!git clone https://github.com/jasonwei20/eda_nlp.git
# 因为每个 group 都要进行不同级别的 EDA 处理,这里简单得把每个 group 单独保存为了一个文件
eda_grouped = back_translate_df.groupby('label')
for name, group in eda_grouped:
every_group_df = pd.DataFrame(group)
filename = "data_groups/group" + name + ".csv"
every_group_df.to_csv(filename, sep="\t", header=0, index=0)
# 对每一组文件进行eda处理
groups = back_translate_df.groupby('label')
for name, group in groups:
num = get_num_from_name(name)
n2 = calcu_n2(name)
filename = "group" + name + ".csv"
if n2 > 0:
!python eda_nlp/code/augment.py --input=data_groups/$filename --num_aug=$n2 --alpha=0.1
else:
copyfile("data_groups/" + filename, "data_groups/" + "eda_" + filename)
print("copied file: " + filename)
合并 EDA 处理后的各个问价,作为过采样实验的数据集。
import os
step3_df = pd.DataFrame(columns=['label', 'sentence'])
for root,dirs,files in os.walk(r"data_groups"):
for file in files:
#获取文件路径
file_path = os.path.join(root,file)
if "eda" in file_path:
print(file_path)
file_df = pd.read_csv(file_path, sep="\t", header=0, names=['label', 'sentence'])
step3_df = step3_df.append(file_df)
过采样结果
以下三个图分别是原始数据集、经过回译处理后的数据集、经过 EDA 处理后的数据集。可以看到经过两个过采样处理后,小样本数据数量已经增加,并且所有类别的分布和原始数据集保持一致的规律,不会破坏业务规律。
模型训练
准备和上传数据
首先划分训练集和测试集,在这里训练集和测试集的比如为
import numpy as np
from sklearn.model_selection import train_test_split
baseline_train, baseline_test = train_test_split(step2_df, test_size=0.15)
baseline_train.to_csv("baseline_dataset/baseline_train.csv", sep=" ", header=0, index=0)
baseline_test.to_csv("baseline_dataset/baseline_test.csv", sep=" ", header=0, index=0)
上传训练集和测试集到S3并设置数据通道
train_channel = prefix + '/baseline' + '/train'
validation_channel = prefix + '/baseline' + '/validation'
sess.upload_data(path='baseline_dataset/baseline_train.csv', bucket=bucket, key_prefix=train_channel)
sess.upload_data(path='baseline_dataset/baseline_test.csv', bucket=bucket, key_prefix=validation_channel)
s3_train_data = 's3://{}/{}'.format(bucket, train_channel)
s3_validation_data = 's3://{}/{}'.format(bucket, validation_channel)
train_data = sagemaker.session.s3_input(s3_train_data, distribution='FullyReplicated',
content_type='text/plain', s3_data_type='S3Prefix')
validation_data = sagemaker.session.s3_input(s3_validation_data, distribution='FullyReplicated',
content_type='text/plain', s3_data_type='S3Prefix')
data_channels = {'train': train_data, 'validation': validation_data}
设置超参数优化作业
本文使用了 SageMaker 的自动超参数优化进行训练,内置算法 BlazingText 的超参数可以参考官方文档,在 SageMaker 中选择训练实例有两种方式,local 和 remote,本案例使用的是 remote 方式,即另外开启了一台 ml.c4.4xlarge 进行远程训练。
container = sagemaker.amazon.amazon_estimator.get_image_uri(region_name, "blazingtext", "latest")
baseline_hyperparameter_model = sagemaker.estimator.Estimator(container,
role,
train_instance_count=1,
train_instance_type='ml.c4.4xlarge',
train_volume_size = 30,
train_max_run = 360000,
input_mode= 'File',
output_path=s3_output_location,
sagemaker_session=sess)
对模型设置静态超参数,mode 选择 supervised 代表本文使用的是 BlazingText 的文本分类算法。
baseline_hyperparameter_model.set_hyperparameters(
mode="supervised",
epochs=10,
min_count=2,
early_stopping=True,
patience=4,
min_epochs=5)
设置动态超参数范围,本案例选择了 learning_rate(用于参数更新的步长大小), vector_dim(嵌入层的维度), word_ngrams(使用的单词n-gram特征的数量) 三个超参数。同时制定了超参数优化的目标是准确率,最后开启一个tuner job,制定超参优化的训练作业数以及每次并行训练的作业数。
from sagemaker.tuner import IntegerParameter, CategoricalParameter, ContinuousParameter, HyperparameterTuner
hyperparameter_ranges = {'learning_rate': ContinuousParameter(0.03, 0.06),
'vector_dim': IntegerParameter(100, 200),
'word_ngrams': IntegerParameter(1, 3)}
objective_metric_name = 'validation:accuracy'
tuner = HyperparameterTuner(baseline_hyperparameter_model,
objective_metric_name,
hyperparameter_ranges,
objective_type='Maximize',
max_jobs=9,
max_parallel_jobs=3)
启动超参数优化模型训练
设置好超参数优化作业后就可以调用 tuner.fit 开启训练。
tuner.fit(inputs=data_channels, job_name="hyperparameter-baseline-job", logs=True)
可以在 SageMaker Console 中查看超参数优化作业的情况,显示正在训练中。

训练完成后,可以在 Console 中看到 Sagemaker 9 次训练结果中选出的效果最好的一次训练,以及输出该训练作业的超参数。

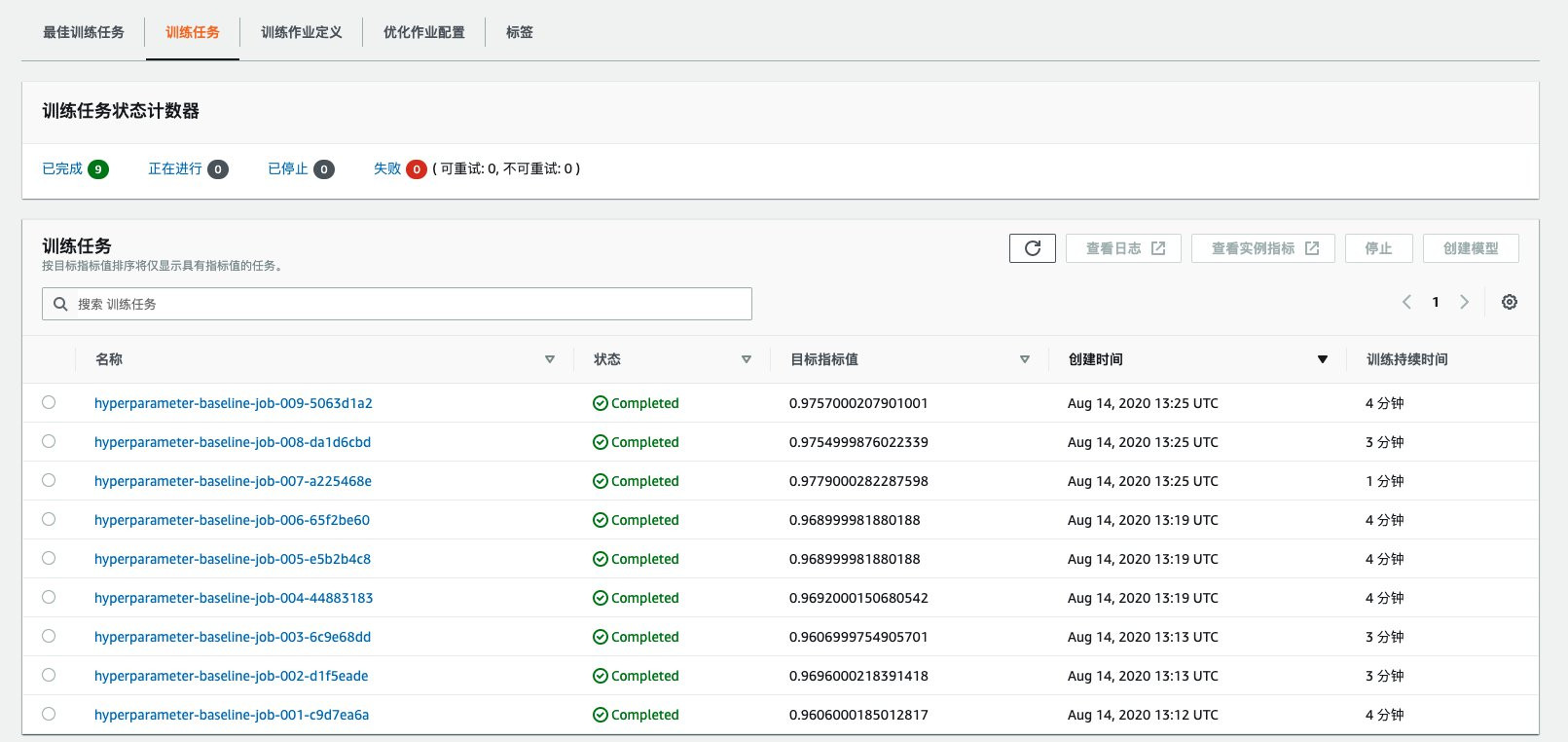
如果想查看每次训练作业的训练情况,可以在训练任务里查看,可以看到训练时间以及输出指标。

模型部署
模型训练完成后可以直接调用 deploy 方法进行部署,部署完成后会得到一个 endpoint 进行调用。
sampling_classifier = tuner.deploy(initial_instance_count = 1,instance_type = 'ml.m4.xlarge')
在多分类的模型中,需要对每一个类别输出模型指标,本文使用 sklearn 的 classification_report 进行验证集指标的输出。
from sklearn.metrics import classification_report
import json
sentenses = sampling_test['sentence'].tolist()
payload = {"instances" : sentenses}
response = sampling_classifier.predict(json.dumps(payload))
predictions = json.loads(response)
predict_label = []
for one in predictions:
predict_label.append(one['label'][0])
real_label = sampling_test['label'].tolist()
print(classification_report(real_label, predict_label))
两次实验的输出如下所示,上图为Baseline实验即没有经过过采样处理的输出,下图为经过过采样处理的实验输出,可以看到,虽然 Baseline 实验的平均准确率和召回率指标都在0.8以上,但观察到每一个指标,发现有两个指标的准确率为0,其他指标之间的差异也较大。而经过过采样处理后的实验,不仅每个类别的准确率召回率等指标都得到了提升,而且各个类别之间的指标差距并没有很大,总体来看平均准确率和召回率都达到了 0.99。


总结
本文利用 AWS SageMaker BlazingText 提出了一种针对不均衡样本的文本多分类方法,并且以 DBpedia 开源数据集(对文章进行作者多分类)为例训练并部署了一个模型。
针对样本不均衡问题,本文从数据层面进行考虑,提出了两种过采样方法:1).回译,利用 AWS Translate 对原始句子进行翻译成另一种语言,再翻译回原语言,一层回译最多可以增强 54 倍;2).EDA,使用同义词替换、随机插入、随机交换、随机删除四种手段对文本数据进行增强。同时,本文也针对数据增强的倍数 n 提出了一种自动化计算方法,将类别数量从多到少进行降序后,假设增强后的类别保持等差数列,可以计算出每一个类别需要增强的倍数。
在算法选择上,本文选择的是 AWS SageMaker 的内置算法 BlazingText,直接利用 BlazingText 的监督模式就可以监督实现文本多分类并且保证高准确率。针对文本多分类的超参数优化,文本使用了 SageMaker 的自动超参优化功能,只需要简单指定超参的范围,即可开启自动的并行超参优化作业。另外,本文的文本多分类模型,从数据处理、过采样处理、模型训练到模型部署,都是在 AWS SageMaker 中完成,整个过程实现了端到端的一体化开发,并且可以非常简单实现训练和部署操作,无需关心底层的资源调配逻辑。
最后,本文针对文章作者多分类数据集进行了两个对比实验,一个是原始数据的 Baseline 实验,另一个是过采样处理后的实验,并且使用 BlazingText 进行多分类,从实验结果中可以得到结论,BlazingText 对于文本分类的效果是非常好的,而本文提出的过采样方法可以明显提高一些数量极少的类别的准确率,同时也可以保持原有数据的一定规律。而 SageMaker 的自动超参优化功能也大大地增强了人工调参的效率。
源代码
本文源代码请查:https://github.com/nwcd-samples/sagemaker-unbalanced-text-multiclassification
参考
本文使用数据集:https://wiki.dbpedia.org/services-resources/dbpedia-data-set-2014#2
Sagemaker Blazingtext doc:https://docs.aws.amazon.com/zh_cn/sagemaker/latest/dg/blazingtext.html
Sagemaker 自动超参优化:https://docs.aws.amazon.com/zh_cn/sagemaker/latest/dg/automatic-model-tuning.html
Sagemaker examples github:https://github.com/awslabs/amazon-sagemaker-examples
boto3 sdk: https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/index.html
sagemaker sdk: https://sagemaker.readthedocs.io/en/stable/
pandas:https://pandas.pydata.org/pandas-docs/stable/reference/index.html
sklearn:https://scikit-learn.org/stable/index.html
NLP EDA:https://github.com/jasonwei20/eda_nlp
本篇作者