亚马逊AWS官方博客
使用 Step Functions 编排从数据库到数据仓库的数据ETL
数据仓库是信息的中央存储库。业务分析师、数据工程师、数据科学家和决策者通过商业智能 (BI) 工具、SQL 客户端和其他分析应用程序访问数据。数据和分析已然成为各大企业保持竞争力所不可或缺的部分。企业用户依靠报告、控制面板和分析工具从其数据中获得洞察力、监控企业绩效以及更明智地决策。
通常,数据定期从事务系统、关系数据库和其他来源流入数据仓库。这个流入的过程,被称作ETL(Extract-Transform-Load)。在数据爆炸的今天,开发者经常需要通过Hadoop/Spark 集群,配合一些开源组件,如sqoop, Hive, Airflow等实现对海量数据的处理和迁移。除了集群本身的维护,如虚机的配置,操作系统的升级,安全管理,存储的扩展等,还要考虑如性能监控,日志,错误处理等诸多支撑性功能的实现。
本文介绍一个通过亚马逊云Serverless(无服务器)服务提供ETL的方案。它包含了亚马逊云Step Function, Glue, Lambda等组件,实现从mysql 数据库到亚马逊云Redshift 数仓的数据迁移以及迁移后的处理功能。
架构设计

① 通过定期执行的源数据爬虫任务,读取业务数据库和数据仓库的源数据。
② 通过Glue服务的ETL Job完成从业务数据库到数据仓库的数据拉取,转化和加载。
③ 调用Lambda函数,对数仓中的数据进行进一步的加工,满足企业对数据分层等进一步处理的要求。
这其中,第2步和第3步都是通过Step Function来调度执行,实现可视化的作业管理。
环境准备
- 首先,在环境中分别创建一个mysql 实例和一个redshift 数仓实例来模拟企业的场景。这里我们设置redshift数据库为“dev”:
- 另外,需要创建s3和redshift-data的两个Endpoint 服务,用于VPC内程序的访问
- 之后,创建一个SNS topic,用于在出现问题时进行通知
- 最后,我们需要为redshift创建一个secret manager 密钥,用于安全访问redshift
在这些基础框架建设完毕后,可以分别连接到数仓和数据库中,通过https://github.com/sun-biao/step-function-etl-redshift/blob/main/sql.script 中的建表语句,分别创建两个表,table1和table2。 另外在资源中还有一个创建存储过程的语句,可以在redshift中执行,这个存储过程用来模拟企业内部数仓中的执行程序。
环境搭建
第一步: 源数据管理
一 在AWS Glue/数据库/连接 中,创建两个JDBC连接,分别指向数据库和数仓。
二 在AWS Glue/爬网程序 中点击“创建爬网程序”,分别为库和仓创建两个爬网程序
三 选中爬网程序,点击“运行爬网程序”。在真实场景中,可以设置为定期触发方式,这里我们手动执行。

四 执行完毕后,点击 AWS Glue/数据库/表 查看添加后的源数据信息。注意这里的表名会根据数据库的名称不同而不同。

第二步: 创建ETL Job
一 点击AWS Glue/ETL/作业,点击“添加作业”
二 在“配置作业属性”页面中,输入“名称”并选择一个“角色”。如果角色中为空,参照链接创建一个新的角色:https://docs.aws.amazon.com/zh_cn/glue/latest/dg/create-service-policy.html 并点击下一步
三 在“选择一个数据源”页面,选中mysql 数据库的table2,点击“下一步”
四 在“选择转换类型”页面,点击“下一步”
五 在“选择一个数据目标”页面,选中redshift数据库的table2,点击“下一步”
六 检查字段mapping后点击“保存作业并编辑脚本”。
七 在最后作业脚本页面,点击“保存”并“运行作业”。如无异常,作业会执行,数据会进入redshift

八 在redshift中可以通过“编辑器”对table2进行查询
九 重复上面1-8,创建一个新的作业,选择table1作为源和目标。这样我们就有了两个作业,分别对应table1和table2
第三步: 创建lambda程序
一 在AWS Lambda中选择“创建函数”
二 函数名为callredshift, “运行时”选择python3.8。
三 点击“高级设置”,在“VPC”中选择redshift 所在VPC, 安全组选择可以访问Redshift的安全组
四在“配置/常规配置”中,将超时时间设置为25秒。
五 在“配置/权限”中,为当前角色附加 “AdministratorAccess”策略
六 将下列代码粘贴到lambda_function.py中
import json
import boto3
import time
client = boto3.client('redshift-data')
def lambda_handler(event, context):
print('start.....')
try:
response = client.execute_statement(
ClusterIdentifier='redshift-cluster-1',
Database='dev',
SecretArn=‘<redshit的Secret Manager ARN>',
Sql='call test_sp1(1000000)',
# Sql='select count(*) from table1',
StatementName='get result'
)
except Exception as e:
subject = "Error:" + ":" + str(e)
print(subject)
raise
query_id = response["Id"]
done = False
while not done:
time.sleep(1)
status = status_check(client, query_id)
if status in ("STARTED", "FAILED", "FINISHED"):
print("status is: {}".format(status))
break
print(response)
desc = client.describe_statement(Id=response["Id"])
result = client.get_statement_result(Id=response["Id"])
print(result)
return str(result)
def status_check(client, query_id):
desc = client.describe_statement(Id=query_id)
status = desc["Status"]
if status == "FAILED":
raise Exception('SQL query failed:' + query_id + ": " + desc["Error"])
return status.strip('"')
七 保存后点击“Test”,创建一个“测试事件”后,再次点击”Test“,查看输出结果
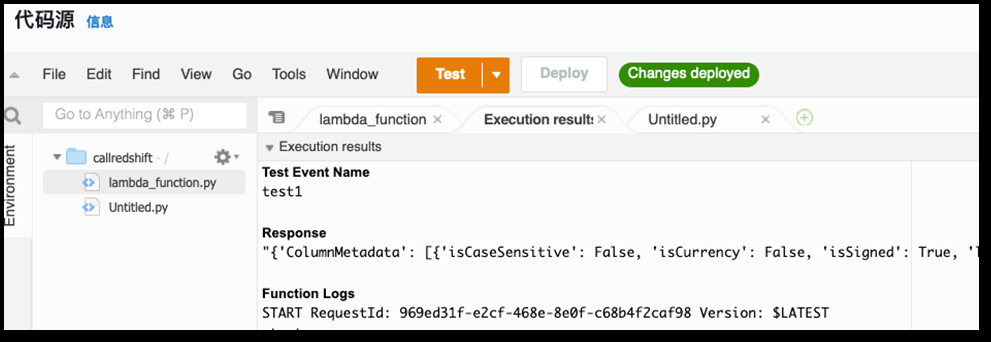
第四步: 创建Step Functions 状态机
一 选择“Step Functions/状态机”,点击“创建状态机”
二 使用默认选项,在下面定义中,删除原Json文件,拷贝如下内容:
三 保存后,修改当前状态机的权限为管理员,执行该状态机并查看状态。
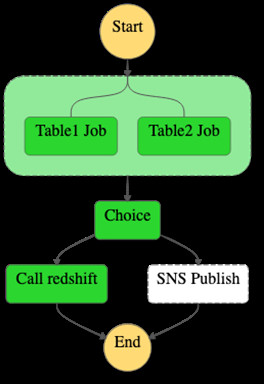
四 点击“图表检查器”中最后一步“Call redshift”,查看右侧步骤输出,确认redshift中的程序被正确调用。

总结
一 整个流程中没有除了数据仓库,没有使用任何需要维护的计算资源,实现了“零运维”。
二 Step Functions状态机的每次执行,都提供了完备的流程日志,每个步骤都有详细的输入输出信息,方便调试。
三 依照Step Functions提供逻辑处理功能,通过判断,循环等可以实现客户复杂的逻辑。
四 Step Functions提供强大的服务整合能力,通过整合其它服务,提供诸如报警,数据,计算等等功能。
参考链接
- https://docs.aws.amazon.com/zh_cn/AmazonRDS/latest/UserGuide/CHAP_GettingStarted.CreatingConnecting.MySQL.html
- https://docs.aws.amazon.com/zh_cn/redshift/latest/gsg/rs-gsg-sample-data-load-create-cluster.html
- https://docs.aws.amazon.com/zh_cn/vpc/latest/privatelink/vpce-interface.html#create-interface-endpoint
- https://docs.aws.amazon.com/zh_cn/sns/latest/dg/sns-getting-started.html
- https://docs.aws.amazon.com/zh_cn/secretsmanager/latest/userguide/tutorials_basic.html