亚马逊AWS官方博客
在 Amazon SageMaker 中使用 XGBoost 来实现商业赋能
毋庸置疑,机器学习,在商业中有着广泛的应用场景,但是通常来讲我们却只能看到只有一些高级玩家、大公司才能在他们的业务场景中真正的使用机器学习(Machine Learning,后面用ML简写)来解决业务问题。这背后是有各种各样的原因的,其中最主要的两个原因:一个在于,相比传统的业务系统,机器学习的硬件价格高,一块v100的显卡价格昂贵,中小公司难以负担;另外一个难点在于,相比传统的业务系统,机器学习对于工程师的要求不同,专注于机器学习的数据科学家需要掌握特殊的技能,相关人才在市场上炙手可热,而且对于企业来说,即便找到了数据科学家,搭建和维护用于机器学习的相关系统也并非易事。
AWS作为云计算的领导者,通过在ML方面的巨大投入,大大降低了ML的门槛。客户可以在AWS上通过EC2的P3实例非常方便的使用到最尖端的显卡,并且是按照实际使用量(小时数)来计费,无需一次性的巨大投入;一方面,Amazon SageMaker可以通过内置算法、自动调参等功能赋能我们的普通工程师,让他们更容易的来学习和使用ML;另一方面,Amazon SageMaker内置了模型的A/B test,并且可以把训练得到的模型实现高可用部署 ,这些功能只需要通过点击鼠标就可以实现,从而极大的简化了数据科学家把模型应用到生产环境的门槛。此外,Amazon SageMaker还提供了一系列的其他功能来进一步降低企业开展ML相关的费用,比如通过Managed Spot Training节省多达90%的成本。
在本篇blog中,我们会使用XGBoost算法为例,完整的展示Amazon SageMaker中一个ML工作流的全生命周期。使用到的数据是个公开的房价预测的数据集。
XGBoost是什么?
如果说把机器学习问题分成,常规机器学习(conventional machine learning)和深度学习(deep learning)的话,那么XGBoost就是在常规ML竞赛获奖最多的算法。XGBoost 的全称是 Extreme Gradient Boosting,是gradient boosting的一种开源实现。gradient boosting 把若干弱模型通过决策树的方式聚合(ensemble)在一起, 形成一个最终的模型,这个过程是一个持续的、不断迭代优化过程,每次迭代优化的方向通过计算loss function的梯度来实现,然后采取梯度下降的方式不断的降低loss function,从而得到一个最终的模型。
XGBoost最常用来解决常规ML中的分类(regression)和回归(classification)问题。回归问题,举例来说:根据一个人的年龄、职业、居住环境等个人信息推算出这个人的收入,这种推理的结果是一个连续的值(收入)的情况就是一个回归问题;分类问题,比如在欺诈检测中,根据有关交易的信息,来判断交易是不是欺诈,这里的判断是或者否就是一个二分类问题。通常这两类问题都是给出一个表格类型数据,表格中的每列数据都是跟推理的目标(属于某个分类或者推理值)有着潜在关系的数据,XGBoost特别擅长处理这类的表格数据(tabular data),并据此作出推断。对于表格数据,无非由行、列来组成,在ML中对于表格数据中的行和列,我们有很多约定俗称的称谓,在各种关于ML的文章中这些称谓会经常出现,为了便于大家理解,在这里对这些叫法做一个梳理:
- 行(row),叫做一个观察(observation),或者一个样本(sample)
- 列(column) ,也叫字段(field),属性(attribute),或者特征(feature)
在Amazon SageMaker中使用XGBoost预测房价
本篇的重点是通过一个示例,来展示在一个典型的ML工作流中,是如何使用Amazon SageMaker以及XGBoost来完成各步工作的。在这个过程中,你将会看到Amazon SageMaker是如何通过各种功能来提升ML的工作效率,并同时降低成本的。首先,我们先简述一下ML的工作流:
机器学习的生命周期

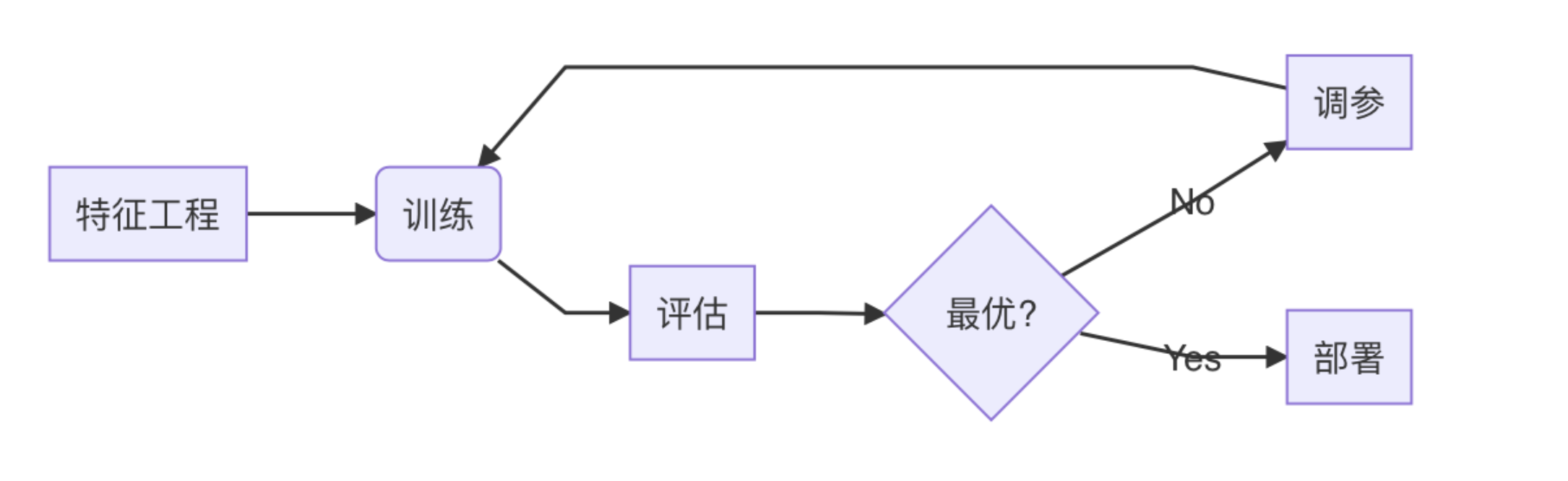
如图,一个典型的ML工作流包含从数据标注到最后部署监控,一个复杂的工作流程。从这个图里我们还可以观测到这个ML工作流中有两个迭代,中间的一个迭代发生在模型训练和evaluation之间,这个过程是用来做超参(hyperparameter)调整,避免过拟合(overfitting);另外一个迭代是当模型部署后,持续的获取新的数据,然后根据这些新的数据更新模型的过程。下面我们借助样例,一步一步分开来讲。
ETL和数据标注
ETL严格上来讲并不能算ML范畴的工作,但是由于数据是ML的必需品,同时由于当前企业IT系统复杂,各业务系统通常采用微服务的方式来搭建,导致各个版块乃至各个版块里的不同微服务都用了不同的存储方式来满足各自的业务需求,这导致的结果就是ML所需要的数据分散在各个不同的业务版块中的不同存储里。想要开展ML的工作的第一步就是要把这些散落在不同地方的数据按照ML的要求聚合起来。举例来说,我们现在要做的一个房价评估的模型,假设我们认为,房屋的海拔信息、周围的人口密度、收入结构、建筑物的年龄、移动基站的覆盖、手机用户的分配、企业类型等等信息都对这个评估有帮助。显然这些数据都是散落在不同的数据源里的,要把他们聚合,同时按照房屋来进行分组和汇总才行,这样我们最终得到的一张表格中的每一行的不同字段就包含了房屋的海拔、周边人口密度等等信息。这个就是在ML的场景下,ETL要做的事情。
但由于这里我们使用XGBoost来评估房价,这属于一种监督学习(supervised learning),所以,仅仅有上面的表格信息还是不够的,我们还缺少一个重要信息就是房屋价格的标注(label或者annotation,也有叫target)。这个房价信息的来源可以是实际的成交价,也可以是通过经验丰富的业务人员,人工标注产生的。如果我们能从系统中获取到真实的成交价信息,那么这个标注信息就可以通过上面的ETL来实现,否则,这个标注信息只能依靠有经验的人来实现,ML就是要学习这些有经验的人深藏的、潜在的经验从而实现自动化的评估房价。
如果业务系统是运行在AWS上的,则可以通过AWS提供的一些产品来完成这个ETL,这类服务包括Amazon EMR、AWS Glue等。这类工作本质上属于大数据处理,只不过这个大数据处理服务的对象是ML,怎么做这个大数据的处理不是ML本身要应对的问题,所以,我们假设这个ETL工作已经完成,ETL以及数据标注的结果已经上传到了S3上,如图:

这里有两个文件,一个是train.csv,一个是test.csv。train.csv是真正用来做训练和模型评估的数据。
数据预处理和特征工程
拿到训练数据为什么不能直接把数据输入到算法里面去做训练呢,这里大致有两种原因:
- 数据不那么完美。比如训练数据的个别行中,成交价缺失,或者成交价异常,比如单价50万/平米
- 机器本质只能处理数字,现实中的很多数据机器并不能理解它的语义含义,比如不能理解图像的二进制表示的图形化意义;对于业务系统里的一个时间戳1585711438,机器也不能理解它代表的是几月份,是星期几。然而这些时间戳背后代表的星期几、图像二进制数据背后的图形化意义,才是对ML学习和归纳训练数据最有价值的东西。
克服上面这两种问题,对于改善ML最终的推理效果是有特别重要的意义的。克服第一类问题采取的方法叫数据预处理(data preprocessing),克服第二类问题采取的方法叫做特征工程(feature engineering)。
数据探索
在做数据预处理前,我们可以先通过一些手段做一些数据探索(data exploration),这样可以让我们对数据的分布能有一个更好的理解,从而决定如何更好的来利用某一些feature来做训练。下面我们来看一下在SageMaker中如何一步一步来做:
- 点击 Create notebook instance

给notebook设置一个名字,然后选择Create a new role,给notebook绑定一个IAM Role,这个role决定了notebook能访问AWS里面的哪些资源。
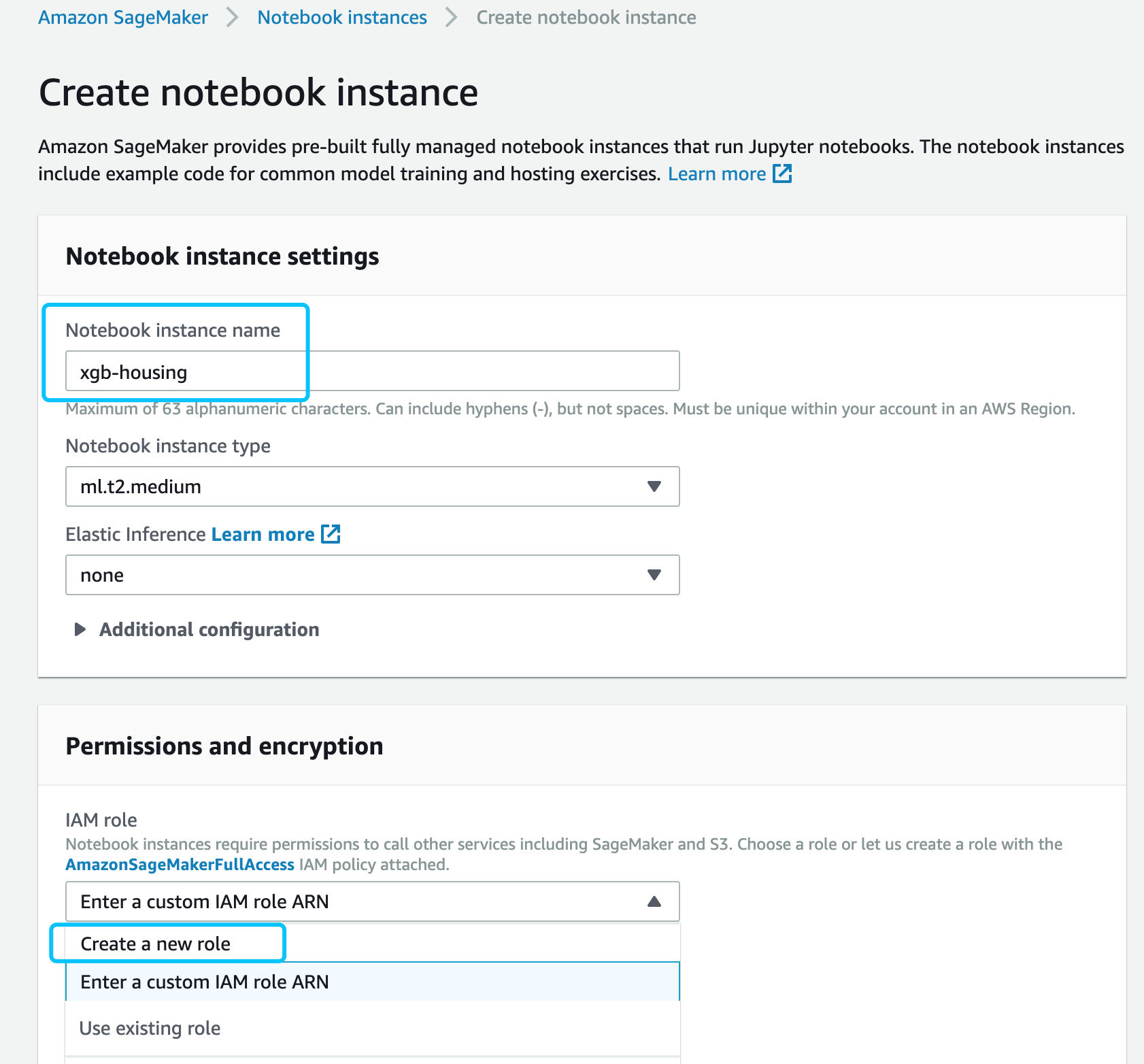
- 创建一个notebook使用的role,然后点击Create notebook instance

- 新建notebook完成后,点击Open Jupyter

- 进入notebook后,点击右上角的New,然后新建一个conda_python3的脚本

- 完成新建后就可以在notebook里面开展我们后续的一系列工作了,首先我们安装基本的库:
python
!pip install sagemaker pandas
安装Amazon SageMaker Python SDK和panda(用于处理表格数据)。Amazon SageMaker Python SDK类似AWS SDK for Python (Boto3),不同之处在于Boto3是可以调用AWS的各种服务的,然而Amazon SageMaker Python SDK是专供在Amazon SageMaker notebook里面开展一系列的ML工作使用的,能利用Amazon SageMaker里面更丰富的一些功能,这类功能是不能直接使用Boto3来使用的。

之后,我们import一些基本的module,并把S3的数据加载到当前目录,做一个简单的数据探索:
describe的结果如图所示,我们可以看到训练数据有很多字段构成,同时可以看到每个字段的取值分布情况,比如 LotArea 这个字段我们可以看到取值范围从1300到215245,平均值10516.828082,以及25%,50%,75%的分位数(Quantile)取值,也可以借助一些matplotlib,seaborn等图形化的库来更好做这种数据探索,好的数据探索对我们后续做数据预处理、改善模型的准确度都是很有帮助的。

数据预处理
从上面的describe结果来看,里面一些feature的取值有一些不寻常的特点,比如BsmtFinSF2在75%的分位数取值是0,但是最大值是1474,对于这类情况,我们可以通过进一步的数据探索来评估这种字段的对于我们ML的意义,从而评估是否可以在训练的时候丢弃这种feature,或者说只是针对有奇异值(outlier)的样本做丢弃处理。这里对行或列的丢弃行为就属于数据预处理,除了丢弃这种操作,我们可以尝试对缺失值(missing value)做补全(imputation)。类似的这种数据预处理还包括:
- 在NLP场景中或者图像处理的情况中,如何把数据用向量来表示,比如text vectorization
- 在深度学习(Deep Learning)里,我们经常要把一个取值范围很大的feature做Feature scaling。可以根据情况选择做Standardization(数据转换成0到1 的取值)或Normalization(把数据转换成均值为0,方差为1的分布)。背后的原因是取值范围过大的数据会影响loss function的工作。
上面提到的这些imputation,vectorization,feature scaling都是要在数据预处理中完成的,对于当前的数据我们做一个简单的预处理:丢弃没有SalePrice的sample:
你可能注意到了,除了丢弃没有SalePrice的sample以外,我们还做了另外一个处理”提取训练数据中的label列,在原始数据中丢弃label列“,这是因为Amazon SageMaker的内置XGBoost算法对于输入数据有两个要求:
- 训练数据要是把label作为首列,我们这里先把label从原始数据提取了出来,后面还会再把它作为第一列拼接回训练数据中;
- 训练数据里不能有表头信息(就是诸如MSSubClass,LotFrontage这些列名)
另外,为了后面模型训练过程中验证模型的合理性我们还要对原始训练数据做一个拆分。把原始的训练数据拆分成training set和validation set,之所以要这样做,是为了在后续训练过程的调参迭代中不断的优化超参。超参优化的目标就是要使得在training set上训练得到的模型能够在validation set上有着良好的表现,从而确定最终训练要使用的超参组合。
你也许还听说,除了要拆分出上面那两份以外,还要在拆分出第三份test set。之所以要有test set,是因为随着你不断的做超参优化,会导致你不断的把validation set中的潜在的信息泄露给算法,从而导致模型对validation set形成过拟合,如果出现了这种情况,导致的后果是虽然模型在validation set上的表现非常好,然而一旦是用真实数据做预测效果却很差。为了避免这种情况的发生,就需要引入test set,然后在整个迭代的训练过程中,算法完全不会看到test set里面的数据,最后当超参确定后,再用test set做一次测试。当我们尝试使用多种算法来解决同一个ML问题的时候,使用test set做最后的一次测试可以帮我们决定最后到底用哪个算法作为最终的解决方案。由于我们这里并不需要在多种算法中做出选择,我们这里不划分test set,只划分出training set和validation set。sklearn提供了很多用来做数据拆分的工具,我们这里直接调用它的一个函数来实现这个拆分:
特征工程
特征工程的引入是为了让我们的算法更好的理解特征而引入的。使用什么样的手段来做特征工程,跟我们选择什么样的算法也有一定关系,由于这里我们采用的是XGBoost算法,我们知道对属性做 one-hot encoding 是有助于算法学习的。你或许会对 one-hot encoding 这个词感到陌生,简单来说,对于一个取值范围可枚举,并且取值是非数值型的属性来说,当我们把它转换成机器可以识别的编码的时候可以考虑使用数字编码的方式来表示。但问题在于通过这种方式,不同的枚举值之间有隐形的大小关系,这种暗含的关系会影响模型的准确性,所以我们表示有n个枚举值的属性时,使用n个二进制位来表示,当需要表示其中任意一个枚举值m的时候,仅仅使第m个二进制位是1,其他的n-m个二进制位都是0。由于n个二进制位只有一个不是0,所以我们把这种转换方式叫做one-hot encoding。采用one-hot encoding来对可枚举的属性编码时,如果属性的取值个数过多,会导致产生过多的数据,在这里我们选择只对取值个数少于10的属性来做one-hot encoding,具体如下:
这一部分,我们对数据预处理和特征工程做了一个介绍,同时对示例数据做了简单的处理。在这个过程中我们顺带的介绍了数据探索,训练数据集拆分等概念。在实际操作中,数据探索、数据预处理、特征工程这类工作都是最需要发挥数据科学家智慧的过程。要解决的问题不同,要使用的算法不同,都会影响到这类工作采取的具体方法。同时,这类工作也是整个ML工作流中最花时间的部分,数据科学家要在notebook中使用各种方法来完成训练前的处理,各种方法会运用也会不拘一格,在预处理、特种工程之间也没有明显的界限,也有人把这些工作统统称为数据预处理。作为这些预处理后的下一步就是要把他们送进算法里面来训练了。
构建模型与训练
构建模型对深度学习来说是一个比较复杂的过程,因为你需要像搭积木一样的来去搭建一个多层的网络,每层的网络又有不同的目的,比如距离输入侧较近的层要承担很多类似特征工程的工作。但是对于我们现在要使用的XGBoost这个传统的ML算法来说,这个模型可以理解成就是算法本身,是一个开箱即用的东西。我们只要打开箱子直接用就行了,怎么用呢?我们要做的就是按照要求,设置输入数据的格式,然后给算法配置参数就可以了。上面我们对XGBoost的输入格式做过说明,下面我们先按照格式要求把数据准备好:
数据准备好了,下一步就是配置各种参数然后训练。这里是使用了 Amazon SageMaker Python SDK 来完成训练的,这个SDK里的 Estimator 这个概念值得说明一下,Estimator 是SDK中对任何训练的一种抽象。在Amazon SageMaker中你可以使用三类算法来完成训练任务,包括:
- Amazon SageMaker自带算法,比如这里用的XGBoost,还有比如Object2Vec等
- 公开的一些第三方ML Framework,比如TensorFlow MXNet等
- 自带算法
但是不管你使用哪一种算法来训练,在SDK中都是通过 estimator.fit 的调用来完成训练。不同之处在于超参的设置,输入数据的格式等等。
模型评估与调参
评估模型的第一步是要先确立评估的标准——evaluation metric,在这里我们使用XGBoost解决回归问题,选择mae来作为评估标准,在上面我们调用fit启动训练任务的时候,已经通过hyperparameters设置了这个评估标准。在训练过程中,我们就可以一直看到这个评估指标的输出情况:

可以看到,经过20轮的训练,mae在training set上是7241.31,在validation set上是20050.7。我们在一开始的机器学习的生命周期中就已经提到过,训练评估调参是个迭代循环的过程(如下图所示)。
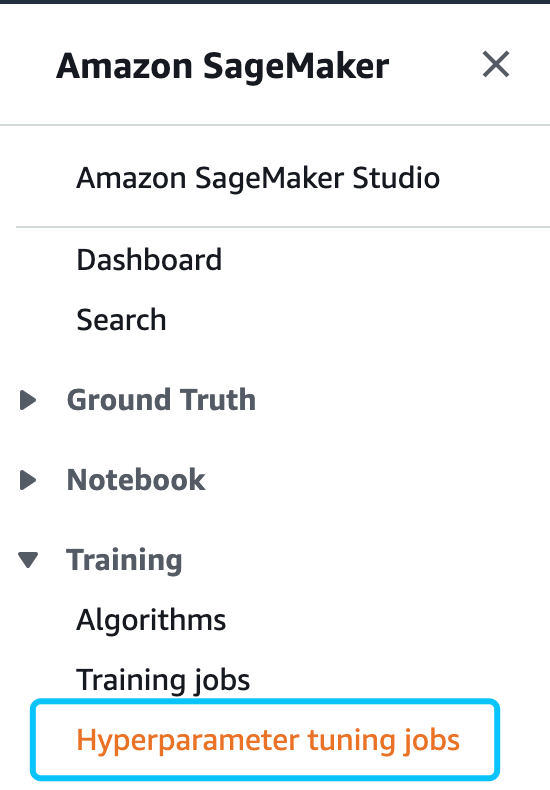
该不断循环过程的目的是得到一个最佳的超参配比,使得评估指标在validation set上的效果最优。这里的评估指标就是mae,数值越小越优。然而,不同算法有不同的超参可以选择,数量很多, 而且对于一个新的问题,如何设置超参通常是一个要依赖实践经验的事情,如果没有很好的经验可以参考,这通常会是一个费时耗力的事情。Amazon SageMaker提供了一个很方便的功能可以帮我们来实现自动化的调参,找到最佳的超参配比来使得指标最优。在console中找到“Hyperparameter tuning jobs”然后点击“Create hyperparameter tuning jobs”开始创建自动化调参任务。
第一步:新建一个名字叫xgb-housing-tuning的调参job
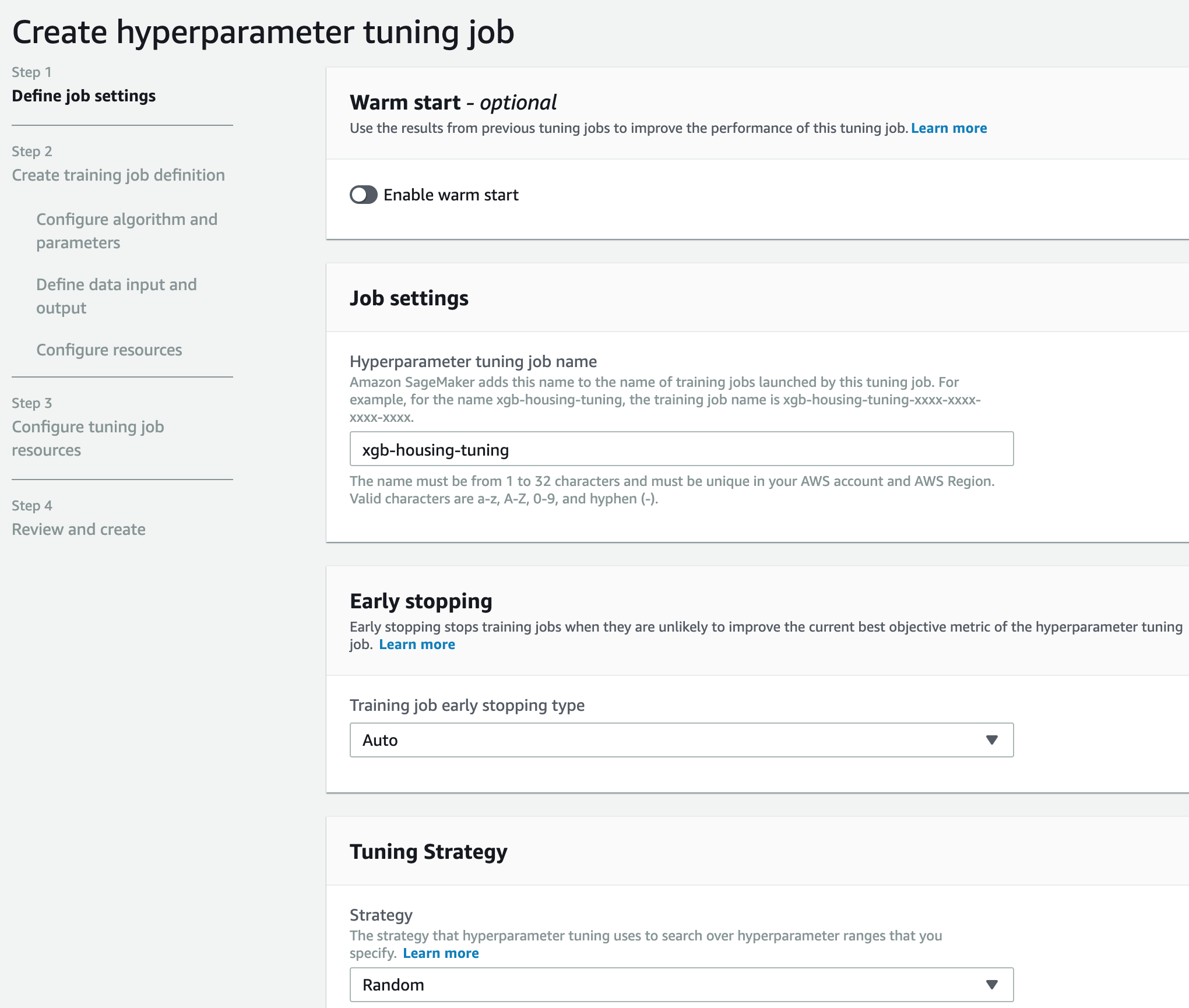
第二步:tuning job内部需要先有一个training job,然后通过不断优化超参,来使得training job的评估指标最优。这一步就是创建这个training job,设置名字叫 xgb-housing-training-job 的训练job,然后在后续的界面中按照图示设置如何自动调参。
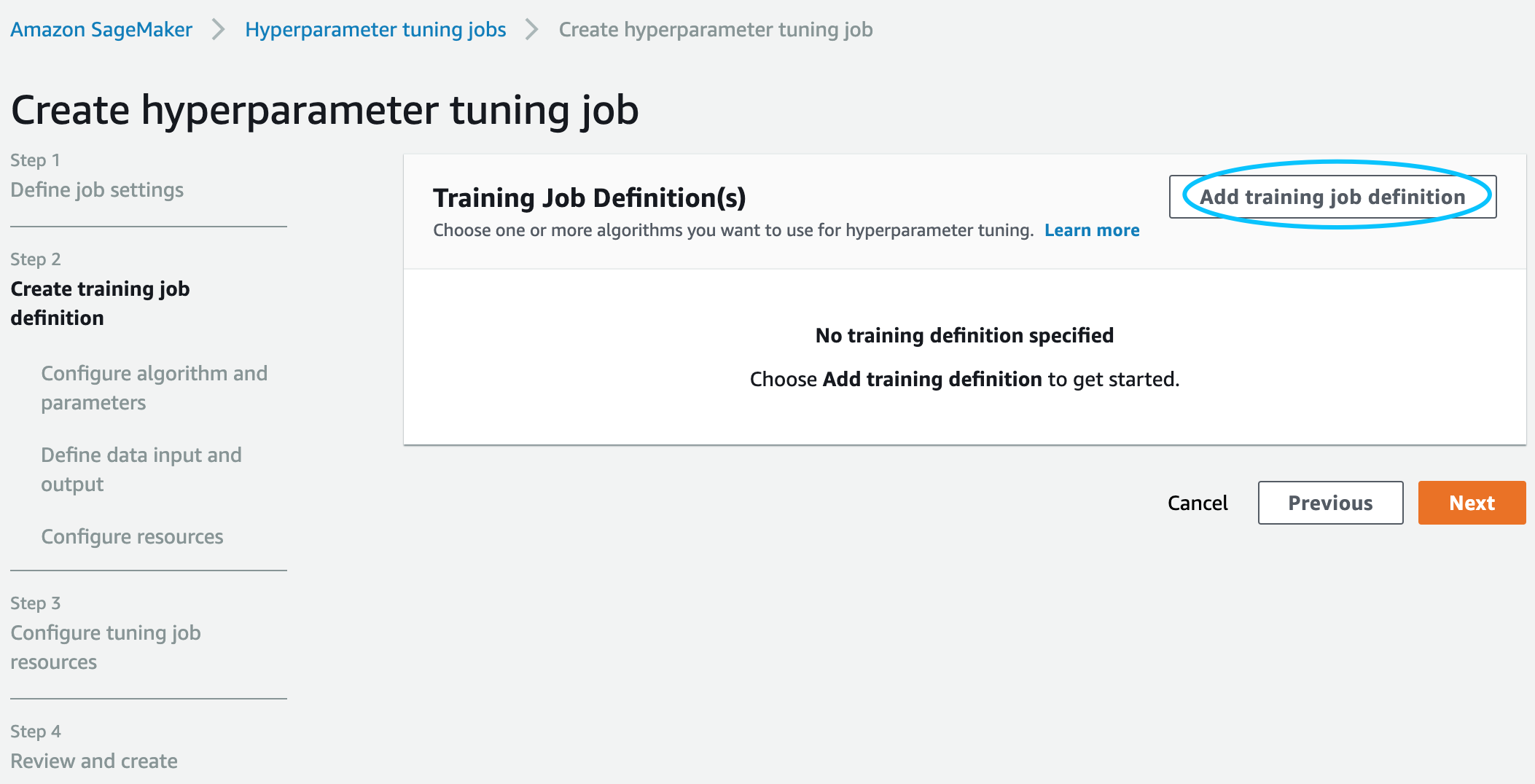
可以设置跟notebook相同的role。设置算法的时候选择Amazon SageMaker内置的XGBoost算法。
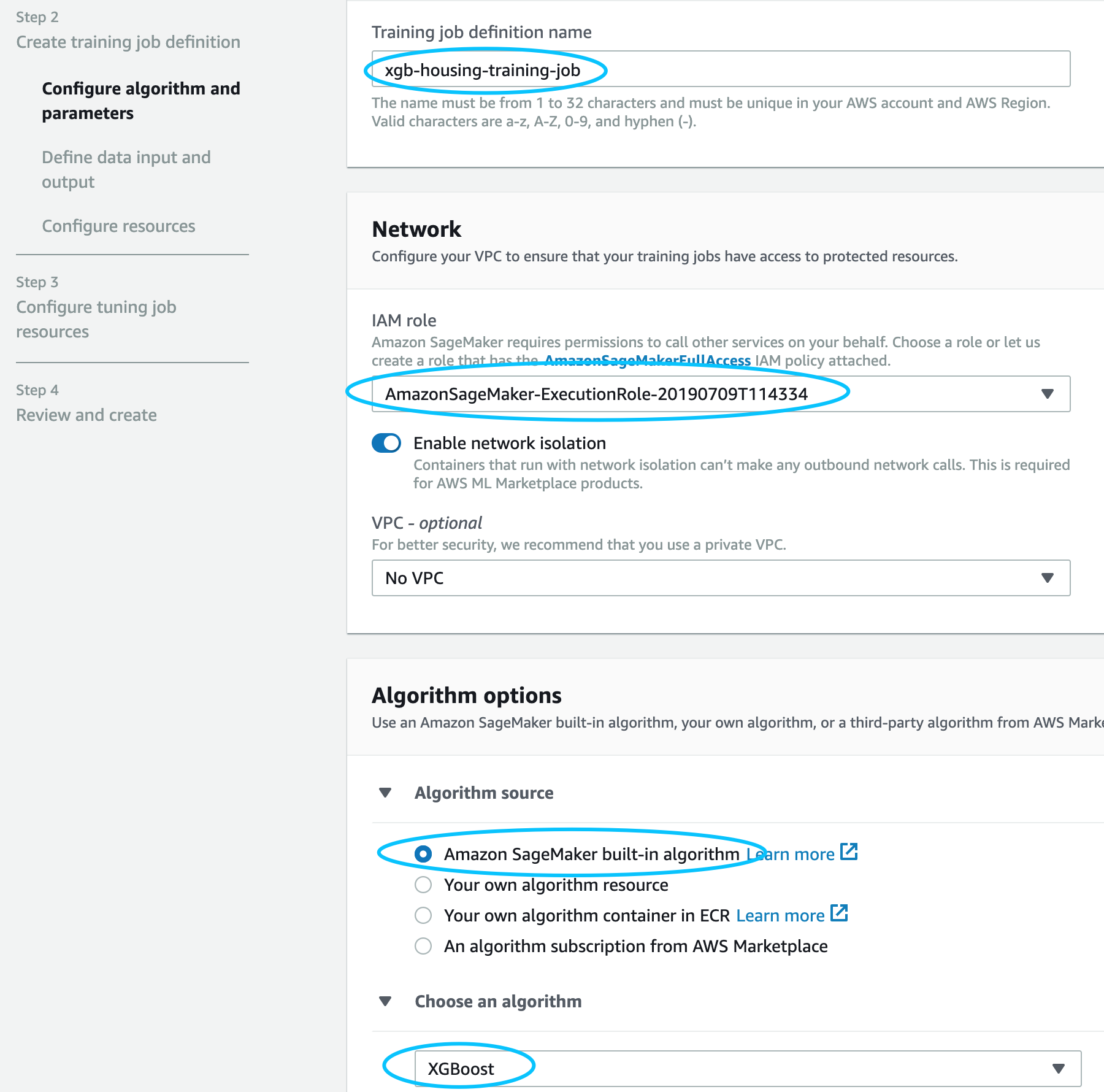
objective metric就是评估指标,我们这里还是选择mae。在Hyperparameter configuration这里,Amazon SageMaker会自动的把XGBoost相关的超参列出来供我们进行调整,可以针对相关的超参选择取值,以及取值范围。这里我们主要设置了eta 的取值范围和max_depth。

在设置输入数据的时候要设置两个channel,分别对应training set和validation set。默认有一个名叫train的channel,另外一个channel则需要自己添加,这里注意自己添加的这个channel的名字一定要叫validation,如果用其他的名字会报错。其他需要设置的包括Input mode,Content type,S3 location,按照图示设置就可以了。

在设置training job最后一个界面可以勾选使用spot training,这样可以利用spot instance大大节省调参的成本。

第三步,设置最大同时训练任务数(3次)和总共训练多少次(9次)
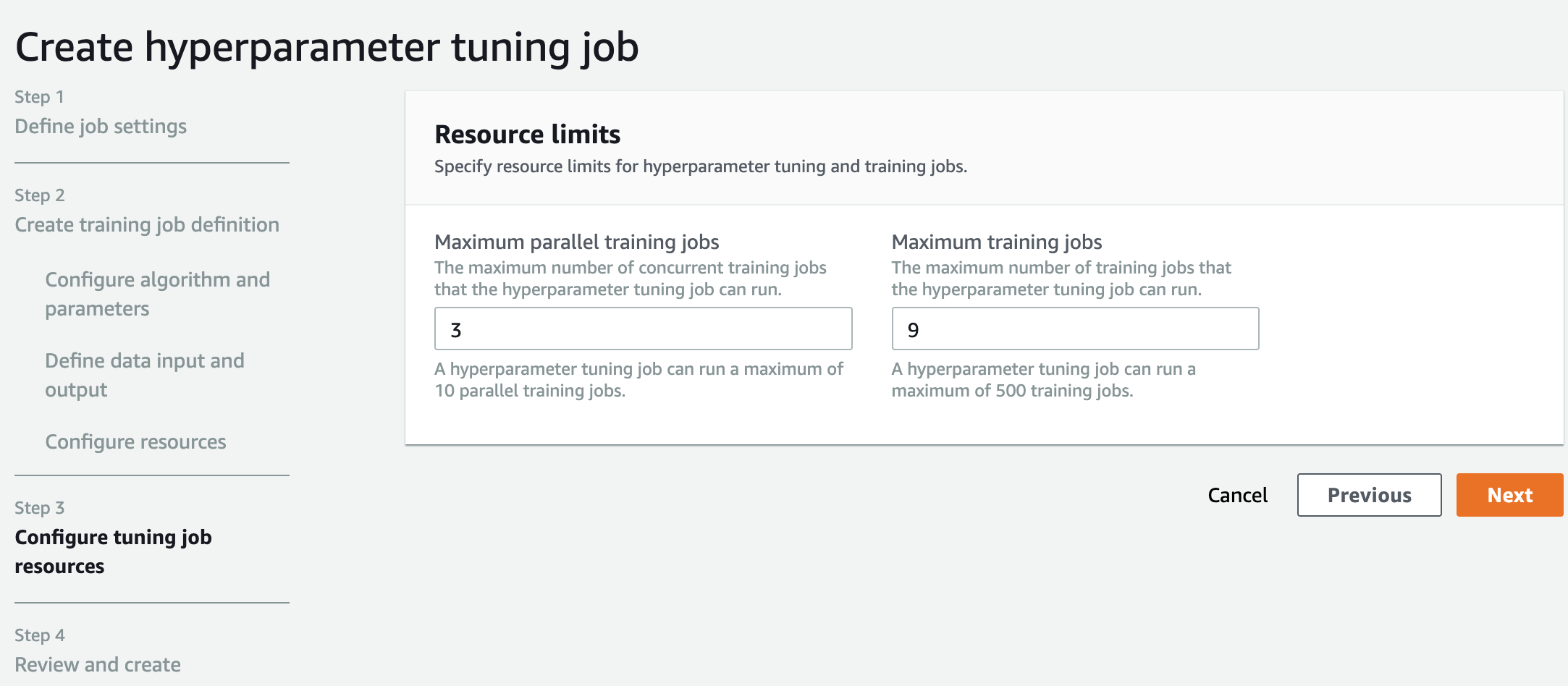
完成以上hyperparameter tuning job的创建后,就可以看到调参的运行情况,这里我们可以看到已经有3个训练任务在同时运行了。

完成后我们可以看到所有9个训练任务的结果,其中mae最小值是16320.2998046875,查看这个训练任务的详情我们就可以得到最佳的超参配比了。

从上面的最优训练结果进入训练结果界面的,在界面的上半部分我们可以到这次的训练,SageMaker使用spot training的方式,实际帮我们节省了73%的开销。

在同一个界面的下部可以看到每个超参的取值是多少:
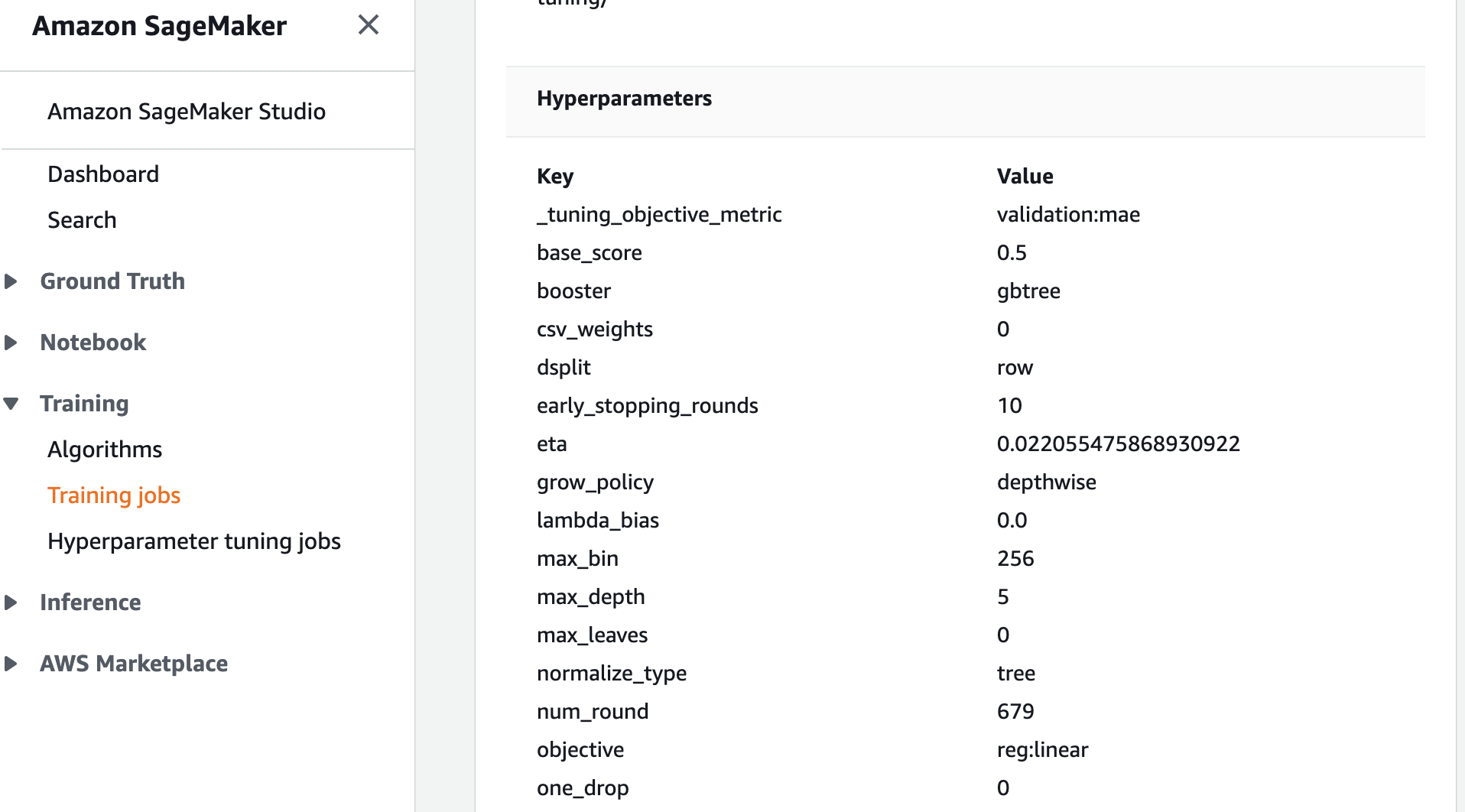
模型部署
创建模型
通过上面的不断训练评估调参,如果我们最终得到了一个比较满意的超参配比。这个超参配比就是我们上面调参的最终目的,然后就可以训练得到最终的模型,训练最终模型的时候要先把training set和validation set的数据合并到一起,这样做是为了使样本数量最齐全,从而得到最好的训练效果。简言之,要想得到最好的模型,我们需要最全的观察数据 + 最好的超参配比。完成最后这一步的方法跟上一节训练的方法完全一样,最终也可以看到一个training job界面,类似上图,在这个界面点击“Create Model”就可以把训练结果制作成一个可部署的模型了。建好后,就可以向下图一样在左边的菜单里的inference->Models下面看到创建好的模型了。

由此可见,我们为了得到一个真正由于生产环境的模型,可能需要在training这个阶段做非常多次的训练,得到非常多的training job,其中可能只有一个有幸被选中作为最终的、能够被部署的模型。
模型部署
点击上面任何一个模型后选择“Create endpoint”就可以进入模型的部署界面了。
模型负载均衡
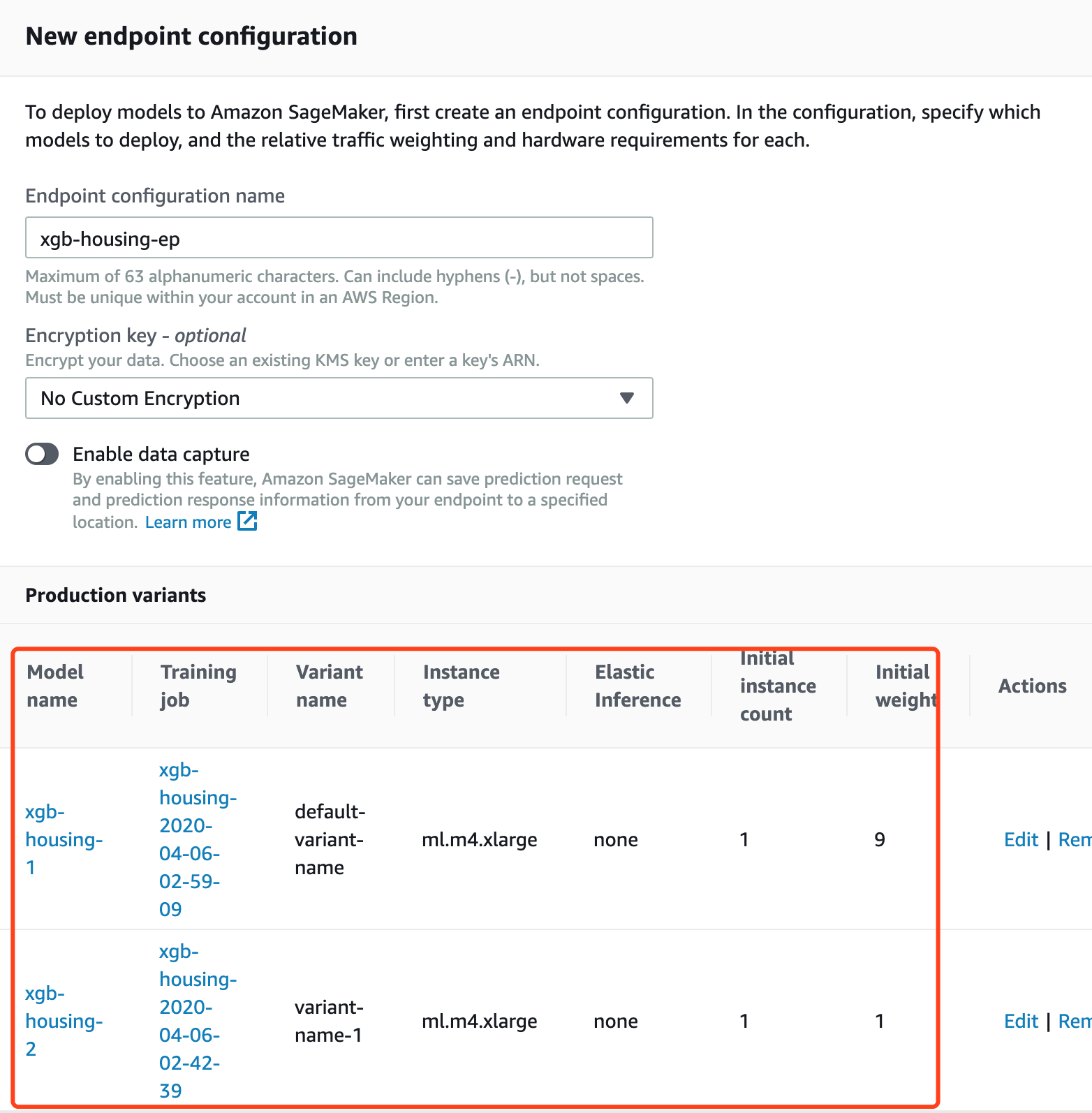
在Create and configure endpoint这个部署界面,我们除了可以设置一个endpoint name以外,还可以通过设置endpoint configuration来对不同的模型设置不同的weight来做负载均衡,从而实现A/B testing的功能,如下图:
模型弹性伸缩
在完成以上endpoint的部署后,进入完成部署的endpoint可以看到刚才endpoint里面包含的多个模型,可以单独对任何一个模型,设置权重、调整instance数量、设置弹性伸缩。

点击“Configure auto scaling”后就可以通过设置“Maximum instance count”和“Target value”来完成这个弹性伸缩的设置:

调用模型推理

现在我们要使用上图中的部署好的endpoint来做推理。跟上面在训练的时候提到的Estimator类似,Amazon SageMaker Python SDK也对推理调用有统一的抽象,这个名字是Predictors,任何的推理调用都要首先创建一个RealTimePredictor,然后调用它的predict方法,如下:
注意这里举例调用predict方法时,是使用的Xvalid的第一行,这个不同于存放在Xvalid.csv文件的中的数据(这个数据是Xvalidxgb),Xvalid这个pandas dataframe中的数据是不包含label列的,而Xvalid.csv文件的第一列是label列。
总结
在本文中,我们以房价评估为例,使用Amazon SageMaker的内置的XGBoost算法,展示了Amazon SageMaker在ML的整个生命周期中的各项功能。Amazon SageMaker提供了一连贯的功能,帮助数据科学家高效的、低成本实现端到端,从模型构建到生成环境部署的各种工作。这些功能包括全托管Jupyter notebook 用来构建模型,后续的自动调参、模型构建、部署、负载均衡、弹性伸缩直达生产环境。其中当数据科学家临时需要GPU的时候,可以通过简单的界面操作就可以更换notebook为GPU实例,在自动训练和自动调参的过程中可以使用spot training大大节省训练成本。
这一系列的功能,大大降低了企业使用ML所需要的资金门槛和人才门槛,是当今企业通过ML来提升竞争力的强有力的平台。