Blog de Amazon Web Services (AWS)
Capture y ajuste las métricas de utilización de recursos de Amazon RDS para SQL Server
Amazon Relational Database Service (Amazon RDS) envía automáticamente métricas a Amazon CloudWatch en intervalos de 1 minuto. Los datos con un período de 1 minuto están disponibles durante 15 días, lo que significa que dispone de información histórica de su instancia que puede servir como punto de partida. Puede utilizar las métricas recopiladas para comprender, a un nivel alto, los patrones de carga de trabajo de las aplicaciones que impulsan la utilización de los recursos de la instancia de base de datos, como las conexiones a la base de datos, uso de CPU, memoria, disco, y red.
Amazon RDS proporciona las siguientes herramientas de supervisión para ayudarle a comprender el uso de los recursos de su instancia de RDS:
En este blog, mostraremos cómo capturar y ajustar las métricas de uso de recursos en Amazon RDS para SQL Server.
Monitorización mejorada de Amazon RDS
La monitorización mejorada (Enhanced Monitoring) proporciona métricas en tiempo real del sistema operativo en el que se ejecuta la instancia de base de datos. Estas métricas se pueden configurar con una granularidad de hasta 1 segundo y se puede acceder a ellas mediante la consola o la API de Amazon RDS. La monitorización avanzada recopila las métricas a través de un agente en la instancia de la base de datos, mientras que CloudWatch recopila las métricas en la capa del hipervisor. Para obtener más información, haga clic en el siguiente enlace en Supervisión mejorada.
Quizás se pregunte durante cuánto tiempo debe capturar las métricas de rendimiento. Lo ideal sería recopilar suficiente información durante los ciclos importantes, como las horas pico de trabajo, las operaciones normales y los eventos periódicos, como el procesamiento mensual de los trabajos (jobs) de la base de datos. Las métricas de monitorización avanzada se almacenan de forma predeterminada durante 30 días en los registros de CloudWatch, pero usted puede ampliar este período.
Las siguientes son algunas métricas importantes:
- Utilización de la CPU: la supervisión del uso de la CPU ayuda a identificar si los problemas de rendimiento se deben a la presión de la CPU. Por ejemplo, si el uso de la CPU era del 80% en el momento del problema de rendimiento y, a la misma hora de la semana pasada, el uso de la CPU fue similar y no se informó de ningún problema, es probable que la CPU no sea el cuello de botella.
- Disco: puede realizar un seguimiento de los patrones de uso de E/S y almacenamiento mediante métricas como las IOPS de lectura y escritura para establecer una tendencia. Esto también puede ayudar, durante la planificación de la capacidad de almacenamiento, a elegir entre los tipos de volumen disponibles, como los discos gp2 / gp3 e io1 / io2.
- Memoria: varios problemas de rendimiento pueden estar relacionados con cuellos de botella de memoria. Con la monitorización avanzada, puede realizar un seguimiento del uso y los patrones de la memoria del sistema (memoria total y memoria disponible) y de la memoria de SQL Server (memoria total de SQL Server) para identificar los cuellos de botella.
- Red: las métricas de rendimiento de la red (KB/s de lectura de red y KB/s de escritura de red) son útiles para rastrear la cantidad de datos transferidos a través de la red.
Con estas métricas, puede tener una buena indicación del uso de los recursos durante los días y horas importantes de sus procesos de negocio. Estos valores pueden proporcionar una visión holística de la utilización de los recursos, lo que puede resultar útil cuando es necesaria una comparación para identificar posibles obstáculos.
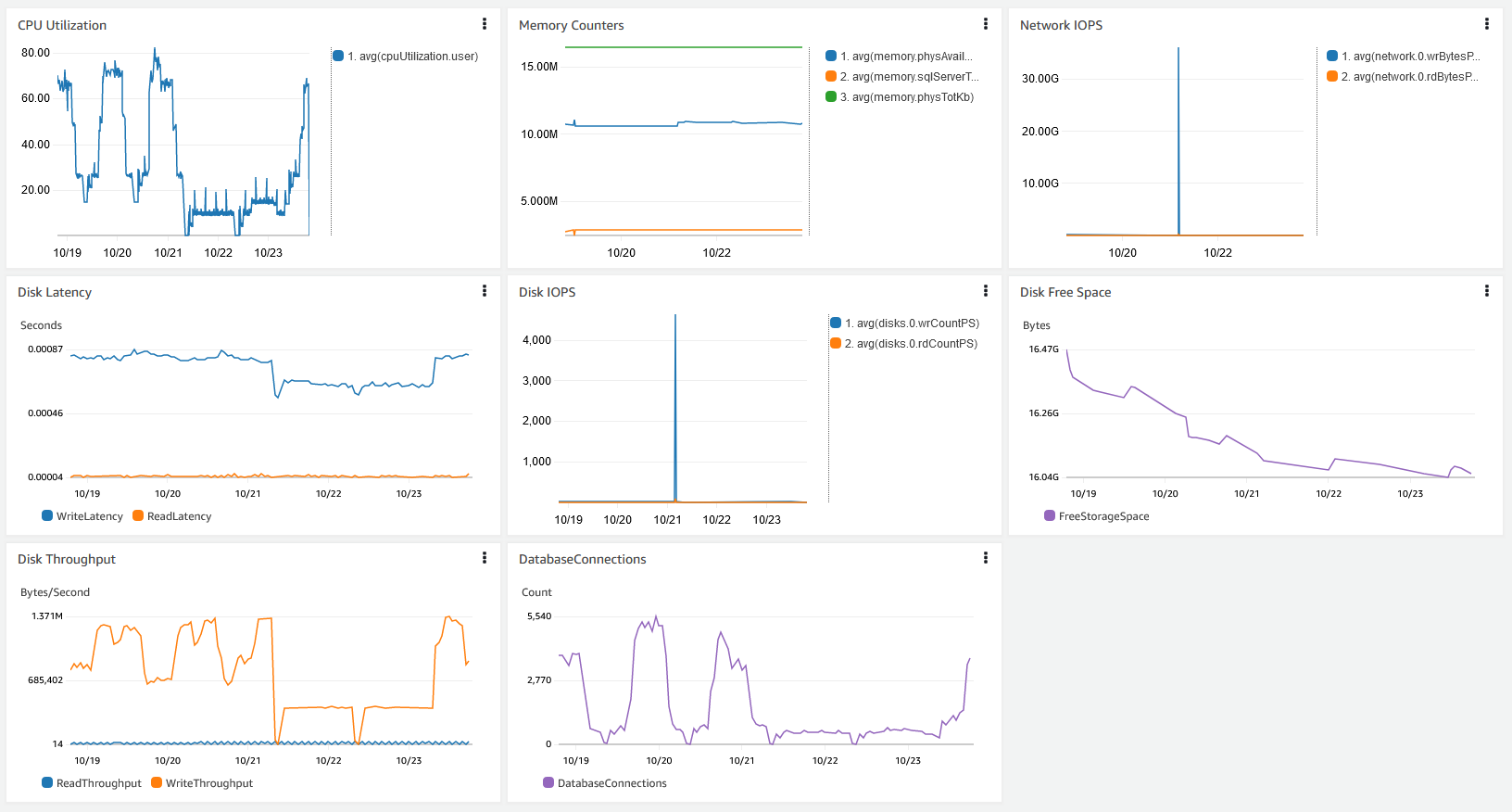
Puede crear un panel en CloudWatch para obtener una vista centralizada de estas métricas de rendimiento aquí descritas. La siguiente captura de pantalla muestra un panel consolidado con datos de CloudWatch y Enhanced Monitoring.
Amazon RDS Performance Insights
Performance Insights es una herramienta de monitorización que proporciona información sobre el rendimiento de la base de datos RDS. La capa gratuita de Performance Insights recopila datos cada segundo de las bases de datos de RDS y los conserva durante 7 días. Para conocer las tendencias de rendimiento a largo plazo, puede aumentar los datos históricos de rendimiento continuo hasta dos años. Para cada motor de base de datos de RDS, Performance Insights muestra información ligeramente diferente en función de las métricas de rendimiento nativas del motor. Con Performance Insights, puede recopilar las tendencias de carga de las bases de datos, los principales tipos de esperas y las consultas clave de SQL durante un período de tiempo. Puede utilizar esta información para compararla con los datos actuales para aislar las posibles causas raíz.
La mayoría de los administradores de bases de datos de SQL Server están familiarizados con las DMV (vistas de administración dinámica) para diagnosticar y solucionar problemas de SQL Server. Con los DMV, los datos se recopilan tal cual, y es necesario desarrollar mecanismos para comprender las tendencias de uso. En esto es donde Performance Insights ayuda a automatizar la recopilación y retención de datos.
Las siguientes son algunas métricas importantes:
- Access Methods: divisiones de páginas: esto puede provocar cuellos de botella de E/S (I/O). Números altos pueden indicar que es necesaria una actividad de mantenimiento, como la reconstrucción de índices y la potencialmente, revisar la configuración del factor de relleno.
- Bloqueos y locks: La contención de bloqueos puede provocar problemas de rendimiento en SQL Server, y es importante realizar un seguimiento de esta información no solo para analizar tendencias, sino también para descubrir las sentencias SQL que deben ajustarse para que la base de datos funcione mejor. Puede realizar un seguimiento de los procesos bloqueados (Processes Blocked) y del número de bloqueos mutuos (Number of deadlocks).
- Administrador de memoria: La métrica Concesiones de Memoria Pendientes (Memory Grants Pending) puede ayudar a detectar problemas de memoria durante un período de tiempo.
- Estadísticas de SQL: hay varias estadísticas de SQL disponibles en Performance Insights que le ayudan a comprender las tareas que contribuyen a la carga normal de la base de datos, como: Batch Request, SQL Compilation, y SQL Re-Compilations.
- Administrador de búferes: el contador Duración prevista de la página (Page Life Expectancy) y Frecuencia de aciertos de caché del búfer (Buffer cache hit ratio) pueden ayudarlo a detectar presión de memoria. Las Lecturas de página en comparación con las Escrituras de página pueden proporcionar orientación sobre rutas de optimización, por ejemplo, si es necesario revisar la indexación.
Estas métricas proporcionan información sobre el rendimiento de SQL Server. Puede profundizar en las métricas del sistema operativo y las bases de datos, incluidas las métricas de rendimiento, para entender la causa raíz del problema. La siguiente captura de pantalla muestra un ejemplo de estas métricas.

DMV y Almacén de consultas
Después de identificar una anomalía, puede utilizar los DMV para profundizar y solucionar los problemas de rendimiento. Para obtener más información revise Vistas de administración dinámica del sistema.
A partir de SQL Server 2016, Amazon RDS para SQL Server también soporta el almacén de consultas, el cual usted puede utilizar para realizar un seguimiento y gestionar los planes de ejecución de las consultas para las sentencias SQL. Para obtener más información, consulte Amazon.
Diagnosticando y depurando problemas: utilización de CPU
Analicemos un escenario común en el que la aplicación funcionaba perfectamente hasta ayer y ahora tiene un rendimiento degradado. En este caso de uso, se le informó al respecto mediante una alerta de CloudWatch o a través de quejas de los usuarios.
Usted empieza a diagnosticar el problema investigando las métricas. Con CloudWatch, puede ver que la métrica de utilización de la CPU es alta, quizás superior al 90%. Desea saber si el proceso de SQL Server contribuye al alto porcentaje de uso. Puede hacerlo a través de la consola de Amazon RDS, en la pestaña Monitoring, bajo Process List.
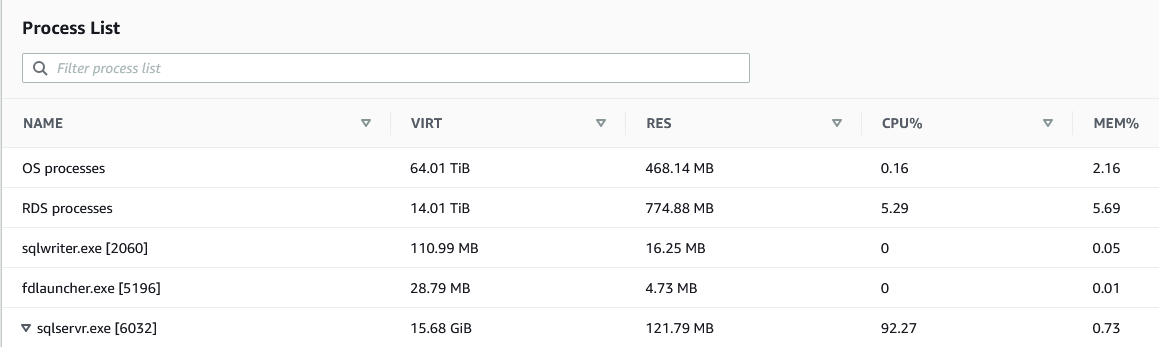
En esta situación es cuando el seguimiento del uso de los recursos de la instancia de RDS puede ayudarle. Con los datos capturados, resulta eficiente identificar las tendencias de uso de la CPU a lo largo del tiempo. Con la monitorización avanzada, puede rastrear la tendencia del uso de la CPU de tu instancia durante los últimos 30 días, lo que puede indicar si el comportamiento es normal o atípico.
El siguiente paso consiste en utilizar los datos capturados en Performance Insights para identificar las consultas que contribuyen a la carga de la CPU. La siguiente captura de pantalla muestra un gráfico con los datos acumulados a lo largo del tiempo.
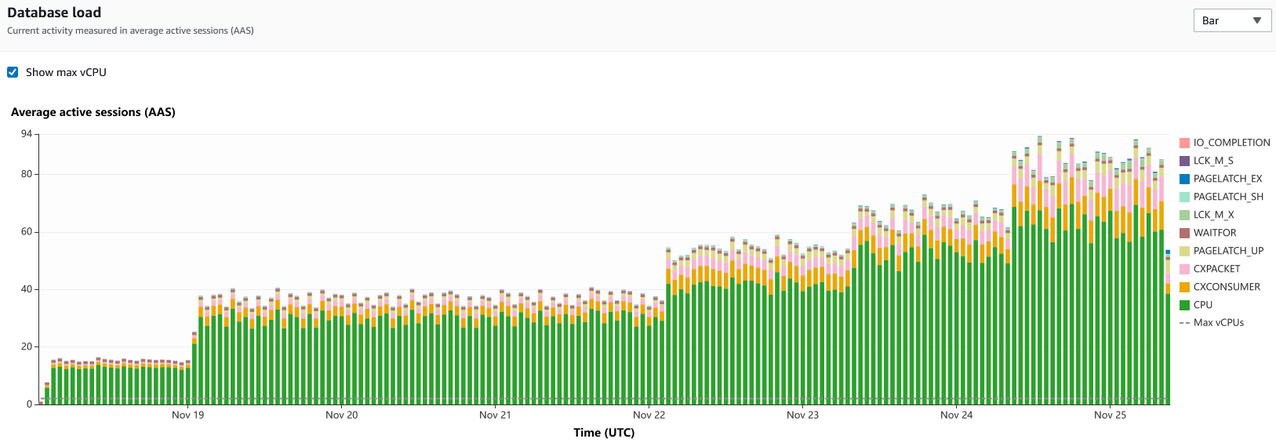
De acuerdo con este gráfico, podemos ver que la CPU es el tipo de espera más grande de la instancia y ha crecido durante un período de tiempo. La tendencia también proporciona los datos necesarios para la planificación de capacidad.
Puede profundizar en una fecha u hora específica para ver una lista de las principales consultas de T-SQL ordenadas por uso de la CPU. Puede obtener planes de ejecución y más detalles sobre las consultas a través de los DMV.
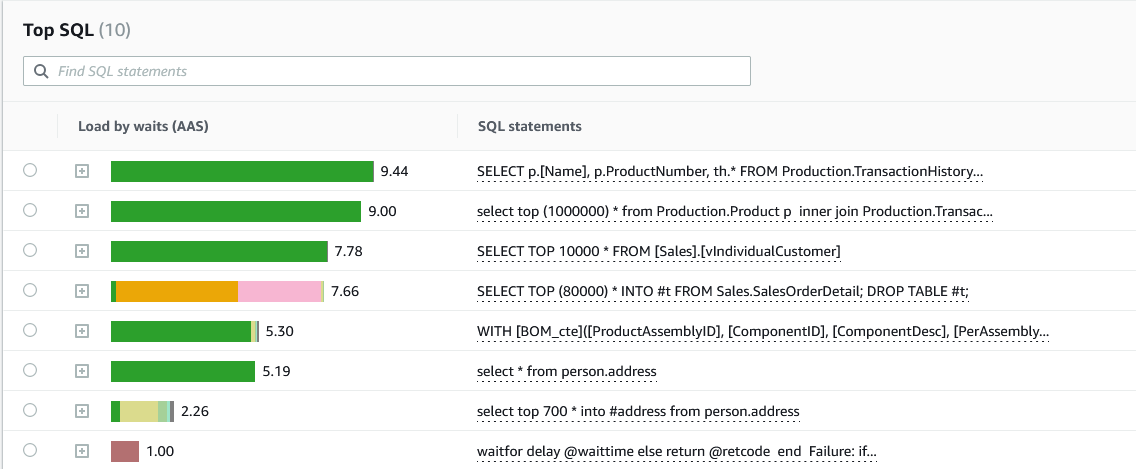 En este ejemplo, hemos podido identificar las tres consultas principales que contribuyen a la elevada carga de la CPU. Además de las consultas en sí mismas, puede identificar los servidores y los usuarios principales que ejecutan estas consultas, lo que facilita aún más el proceso de solución de problemas.
En este ejemplo, hemos podido identificar las tres consultas principales que contribuyen a la elevada carga de la CPU. Además de las consultas en sí mismas, puede identificar los servidores y los usuarios principales que ejecutan estas consultas, lo que facilita aún más el proceso de solución de problemas.
Usemos la primera consulta como ejemplo. Para obtener las estadísticas de ejecución y el plan de ejecución de consultas a través de SQL Server Management Studio (SSMS), primero necesita información sobre la consulta, que puede obtener a través de Performance Insights.

El SQL ID es el valor que usted proporciona a los DMV para obtener las estadísticas y el plan de ejecución. Debe poner el prefijo 0x al SQL ID, como se muestra en la siguiente captura de pantalla.
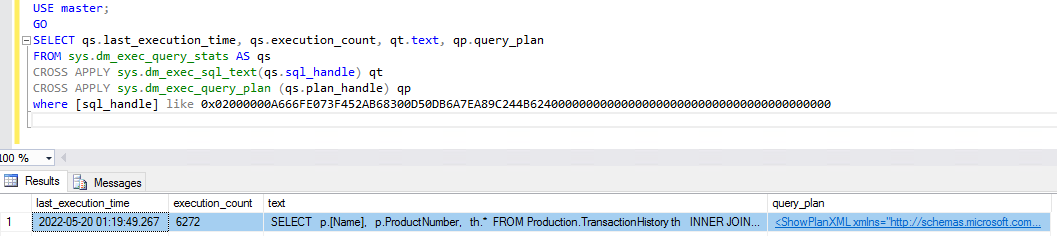
Una vez que haya obtenido el plan de consultas, el siguiente paso es optimizar la consulta mediante métodos de optimización de consultas conocidos.
Conclusión
En esta publicación, conocimos las estadísticas de Monitorización Mejorada (Enhanced Monitoring) y rendimiento de Amazon RDS para SQL Server, que proporcionan una buena manera de capturar y analizar la integridad y los patrones de uso de la instancia. Disponer de esta información le ayuda a optimizar y resolver los problemas de rendimiento. Puede usar el método de esta publicación para ayudarle a mejorar el rendimiento de su instancia.
Este artículo fue traducido del Blog da AWS en Inglés.
Acerca de los autores
 Barry Ooi es un arquitecto de soluciones sénior especializado en bases de datos en AWS. Su experiencia consiste en diseñar, crear e implementar plataformas de datos que utilicen servicios en la nube nativos para los clientes como parte de su viaje a AWS. Sus áreas de interés incluyen el análisis y la visualización de datos. En su tiempo libre, le encanta la música y las actividades al aire libre.
Barry Ooi es un arquitecto de soluciones sénior especializado en bases de datos en AWS. Su experiencia consiste en diseñar, crear e implementar plataformas de datos que utilicen servicios en la nube nativos para los clientes como parte de su viaje a AWS. Sus áreas de interés incluyen el análisis y la visualización de datos. En su tiempo libre, le encanta la música y las actividades al aire libre.
 Rita Ladda es arquitecta sénior de soluciones de Microsoft en Amazon Web Services, con más de 20 años de experiencia con muchas tecnologías de Microsoft. Se especializa en el diseño de soluciones de bases de datos en SQL Server y otras bases de datos. Proporciona orientación arquitectónica a los clientes para migrar y modernizar sus cargas de trabajo de Microsoft a AWS.
Rita Ladda es arquitecta sénior de soluciones de Microsoft en Amazon Web Services, con más de 20 años de experiencia con muchas tecnologías de Microsoft. Se especializa en el diseño de soluciones de bases de datos en SQL Server y otras bases de datos. Proporciona orientación arquitectónica a los clientes para migrar y modernizar sus cargas de trabajo de Microsoft a AWS.
Revisores
 Bruno Lopes es un arquitecto de soluciones sénior en el equipo de AWS LATAM. Lleva más de 14 años trabajando con soluciones de TI, y en su cartera cuenta con numerosas experiencias en cargas de trabajo de Microsoft, entornos híbridos y formación técnica para clientes como Technical Trainer y Evangelista. Ahora actúa como arquitecto de soluciones, combinando todas las capacidades para reducir la burocracia en la adopción de las mejores tecnologías a fin de ayudar a los clientes a superar sus desafíos diarios.
Bruno Lopes es un arquitecto de soluciones sénior en el equipo de AWS LATAM. Lleva más de 14 años trabajando con soluciones de TI, y en su cartera cuenta con numerosas experiencias en cargas de trabajo de Microsoft, entornos híbridos y formación técnica para clientes como Technical Trainer y Evangelista. Ahora actúa como arquitecto de soluciones, combinando todas las capacidades para reducir la burocracia en la adopción de las mejores tecnologías a fin de ayudar a los clientes a superar sus desafíos diarios.
 David Carvalho Queiroz es consultor sénior de bases de datos en el equipo de Servicios Profesionales de Amazon Web Services, con más de 10 años de experiencia en bases de datos. Su función consiste en diseñar soluciones y estrategias de migración para educar y capacitar a las empresas globales en su transición a AWS.
David Carvalho Queiroz es consultor sénior de bases de datos en el equipo de Servicios Profesionales de Amazon Web Services, con más de 10 años de experiencia en bases de datos. Su función consiste en diseñar soluciones y estrategias de migración para educar y capacitar a las empresas globales en su transición a AWS.
 Gaston Lyons es un arquitecto de Soluciones en AWS. Tiene más de 10 años de experiencia en TI, incluyendo cargas de trabajo Microsoft. Como arquitecto de soluciones ayuda a los clientes a diseñar arquitecturas de nube para afrontar sus retos de transformación digital.
Gaston Lyons es un arquitecto de Soluciones en AWS. Tiene más de 10 años de experiencia en TI, incluyendo cargas de trabajo Microsoft. Como arquitecto de soluciones ayuda a los clientes a diseñar arquitecturas de nube para afrontar sus retos de transformación digital.