Le Blog Amazon Web Services
Classification des Meta-données, data lineage, et découverte des données avec Apache Atlas sur Amazon EMR
Dans un monde où les données jouent un rôle de plus en plus prépondérant, la gouvernance devient un aspect essentiel de la gestion des données. Nombreuses sont les entreprises qui utilisent un data lake comme réceptacle unique où sont déposées les données de ses différentes entités, et cela quelque soit leur format. L’exploitation des métadonnées, de catalogues de données et le « data lineage » deviennent alors un élément clé pour la réussite du data lake.
Introduction de Amazon EMR et Apache Atlas
Amazon EMR est un service managé qui simplifie l’implémentation des frameworks Big Data tels que Apache Hadoop et Spark. Il vous permet de choisir les applications qui seront présentes sur votre cluster soit à partir de liste préétablies, ou alors en les sélectionnant unitairement.
Apache Atlas est une solution qui facilite la gestion des meta-données, permettant aux entreprises de mettre en place de la gouvernance dans le but de construire un catalogue de leur actifs en termes de données.
Atlas supporte la classification des données, incluant le data lineage, qui décrit le cycle de vie de la donnée. Il offre également une fonctionnalité de recherche d’éléments clé ainsi que leur définition métier.
Parmi toutes les fonctionnalités que propose Apache Atlas, cet article se focalise sur la gestion des méta-données et le data lineage du Hive metastore. Une fois Atlas installé, ce dernier utilise un outil natif pour importer les tables Hive, les analyser, et extraire automatiquement les informations relatives au data lineage. Pour obtenir plus d’information sur Atlas et les fonctionnalités qu’il propose, consultez le site web Atlas.
Catalogue de données AWS Glue vs. Apache Atlas
Le catalogue de données AWS Glue fournit un référentiel unifié de méta-données qui s’applique sur diverses sources de données sous différents formats. Le catalogue de données Glue offre une intégration avec Amazon EMR, Amazon RDS, Redshift Spectrum ansi que Amazon Athena. Le catalogue de données peut être exploitable par toutes les applications compatibles avec le Metastore Hive.
L’installation de Apache Atlas sur EMR est suffisante pour que le metastore Hive fournisse des fonctionnalités de découverte, lineage et classification. Cette solution demeure une excellente alternative pour cataloguer les données présentes sur les régions AWS ou AWS Glue n’est pas disponible.
Architecture
Apache Atlas requiert que vous exécutiez un cluster EMR embarquant les applications telles qu’Apache Hadoop, HBase, Hue, et Hive. Apache Atlas s’appuie sur Apache Solr pour fournir sa fonctionnalité de recherche et utilise Apache Hbase comme solution de stockage. En installant Atlas sur un cluster EMR persistent, ce dernier embarquera donc Solr ainsi que HBase.
Cette architecture supporte les tables Hive internes et externes. Le metastore Hive peut être externalisé sur une instance Amazon RDS ou Amazon Aurora afin de pouvoir être réutilisé dans plusieurs clusters EMR. Un exemple de configuration du service Hive référençant un Hive metastore externe hébergé sur RDS est disponible au niveau de la documentation Amazon EMR.
Le diagramme suivant illustre l’architecture de notre solution :

Workflow Apache Atlas sur Amazon EMR
Afin de démontrer les fonctionnalités d’Apache Atlas, nous allons :
- Lancer un cluster Amazon EMR en utilisant la CLI AWS ou AWS CloudFormation,
- En utilisant Hue, nous allons déclarer et remplir une table externe Hive,
- Consulter le Data lineage d’une table Hive,
- Créer une classification,
- Découvrir les metadata en utilisant le langage spécifique de Apache Atlas.
1A. Lancer un cluster Amazon EMR en utilisant la CLI AWS
Les étapes suivantes montrent comment installer Atlas sur Amazon EMR en utilisant la CLI AWS. Cette installation prévoit le déploiement d’un cluster Amazon EMR avec Hadoop, HBase, Hive et Zookeeper, ainsi que l’exécution d’une étape qui lance un script se trouvant dans une bucket Amazon S3 dont le but est d’installer Apache Atlas dans le dossier /apache/atlas.
Assurez-vous de remplir les conditions suivantes avant d’aller plus loin dans la procédure d’installation :
- Vous disposez d’une copie locale de la CLI AWS configuré avec un clé d’accès et une clé secrète.
- Vous disposez d’une paire de clé par default, d’un VPC et de sous réseaux dans la région AWS ou vous prévoyez le déploiement de votre cluster.
- Vous disposez de permissions suffisantes pour créer un bucket S3 et un cluster EMR dans la région par défaut configuré au niveau de la CLI AWS
Une fois la commande ci-dessus exécuté avec succès, celle-ci vous retourne un ID de cluster :
Utilisez la commande suivante pour vérifier la liste des clusters Amazon EMR qui sont actifs (le votre y figurera une fois qu’il sera prêt) :
Intéressez-vous au cluster EMR-Atlas au niveau du résultat retournée par la commande ci-dessus (à moins que vous n’ayez choisi d’utiliser un autre nom de cluster). Il est également possible de parser le résultat en utilisant la commande jq afin de ne garder que le nom et l’identifiant du cluster Amazon EMR :
Sample output:
{
"external hive store on rds-external-store": "j-1MO3L3XSXZ45V"
}
{
"EMR-Atlas": "j-301TZ1GBCLK4K"
}Une fois que votre cluster EMR figure sur la liste des cluster actifs, vous êtes prêts pour passer aux étapes suivantes.
1B. Lancer un cluster Amazon EMR avec apache atlas en utilisant AWS CloudFormation
AWS CloudFormation peut également être utilisée pour lancer votre cluster EMR. Vous pouvez utiliser le fichier de template suivant pour ce faire. Ou lancer le déploiement directement, à partir de votre console AWS en cliquant sur le bouton suivant :

Vous devrez toutefois spécifier les valeurs des paramètres suivants :
- VPC : <VPC cible>,
- EMRLogDir : <Nom du compartiment cible pour le loggin, ex: s3://xxx>
- KeyName: <Nom de l’EC2 key pair>
Déployer un cluster Amazon EMR en utilisant un template Cloudformation représente une alternative à la CLI AWS et permet d’obtenir le même résultat.
Avant d’aller plus loin, assurez-vous que votre stack CloudFormation soit complètement déployée, en vérifiant que le dernier événement remonté corresponde bien à un “CREATE_COMPLETE”.
2. Utilisation de HUE pour creer une table HIVE
La prochaine étape consiste à se connecter à Apache Atlas et Hue pour créer une table Hive.
Afin se connecter à Apache Atlas, vous devez retrouver le nom DNS publique du nœud master de votre cluster Amazon EMR. Cela est possible à partir de la console Amazon EMR. Il sera nécessaire par la suite d’établir un tunnel SSH (Secure Shell) vers le nœud master EMR.
Si la commande précédente ne fonctionne pas, assurez-vous d’appliquer les droits nécessaires sur votre clé (*.pem). Il est aussi important de vérifier que le security group associé au nœud master de votre cluster EMR accepte bien les connexions SSH entrantes (sur le port 22).
Une fois votre tunnel SSH établi, utilisez l’URL suivante pour accéder à l’interface Web Atlas : http://localhost:21000
Vous devriez voir s’afficher l’écran suivant. Le login par défaut est admin, le mot de passe par défaut est admin. Il est fortement recommandé de changer le mot de passe du compte admin dans le cas d’un cluster EMR persistent.

Afin de vous connecter à l’interface utilisateur Hue, suivez les instructions décrites dans la documentation EMR. Tel que vous l’avez pour Apache Atlas, créez un tunnel SSH sur le port distant 8888 :
Une fois le tunnel SSH établi, utilisez l’URL suivante pour afficher l’interface utilisateur Hue : http://localhost:8888/
Lors de votre première connexion, vous devrez créer un super utilisateur Hue. Tel que le montre la capture d’écran suivante, assurez-vous ne pas perdre ses informations de connexions.

Une fois le super utilisateur Hue créé, vous pourrez utiliser la console Hue pour executer des requêtes Hive.

Assurez-vous de suivre les étapes suivantes et exécuter les requêtes Hive qui suivent :
- Exécuter la requête HQL suivante pour créer une nouvelle base de données
- Créer une table externe qui s’appellera
trip_details, et dont les données seront stockées sur S3. Assurez-vous de mettre à jour le nom du bucket S3 en mettant un bucket qui vous appartient.
- Créer une seconde table externe nommé
trip_zone_lookup, et dont les données seront également stockées sur S3
- Créer une dernière table qui représentera la jointure des deux tables
trip_detailsettrip_zone_lookup:
Ensuite, vous devez effectuer un import Hive. Afin de permettre à Apache Atlas d’importer les métadonnées dans Atlas, vous devrez utiliser l’outil d’import Atlas pour Hive. Ce dernier n’est disponible que sur la ligne de commande de votre cluster Amazon EMR (Il est impossible de le lancer à partir d’une interface graphique). Connectez-vous donc en SSH au nœud master de votre cluster Amazon EMR :
Et exécutez la commande suivante. Le script vous demandera de saisir un nom d’utilisateur et un mot de passe pour pouvoir se connecter à Atlas. Pour rappel le nom d’utilisateur par défaut est admin. Le mot de passe par défaut est admin également.
Un import qui se terminera en succès ressemble à cela :
Une fois vos données importées dans Hive. Vous pouvez retourner sur l’interface Web Atlas afin de rechercher et consulter la base de données Hive ou les tables que vous avez importées. Sur le panel gauche de l’interface Atlas, sélectionnez l’onglet Search et saisissez les informations suivantes sur le formulaire de recherche :
- Search By Type:
hive_table - Search By Text:
trip_details
Le résultat de la recherche devrait correspondre aux éléments suivants :

3. Consulter le data lineage de vos tables Hive en utilisant Atlas
Afin de consulter le data lineage des tables Hive que vous avez créées, vous pouvez utiliser la fonctionnalité de recherche de l’interface Web de Atlas. Par exemple, afin de consulter les informations de Data lineage de la table trip_details_by_zone, renseignez les informations suivantes dans le formulaire de recherche :
- Search By Type:
hive_table - Search By Text:
trip_details_by_zone
Le résultat de la recherche devrait correspondre aux éléments suivants :

Sélectionnez par la suite la table trip_details_by_zone afin de consulter le détail de la table :

Cliquez sur l’onglet Lineage, afin de consulter les informations relatives au lineage de la table. Tel que le montre la capture d’écran suivante, le lineage nous indique que notre table trip_details_by_zone a été créée suite à une opération (jointure) entre deux tables de base (trip_details et trip_zone_lookup)

4. Creation de classification pour la gestion des meta-données
Atlas peut également vous aider à classifier les méta-données afin d’être conforme aux exigences en termes de gouvernance de la donnée qui sont spécifiques à votre entreprise. Dans ce qui suit, nous verrons comment créer une classification relative au données personnelles (PII).
Afin de créer une classification, vous devez suivre les étapes suivantes :
- Sélectionnez l’onglet “Classification” sur le panel gauche de l’interface Web Atlas et cliquer sur +
- Entrez
PIIau niveau du champ Name, etPersonally Identifiable Informationau niveau du champ Description - Cliquez sur Create

Pour la suite, nous allons classifier les tables qui disposent de données personnelles, en leur appliquant la classification PII créée lors de l’étape précédente :
- Effectuer une recherche en retournant sur l’onglet Search au niveau du panel gauche de l’interface Web Atlas.
- Dans le champ Search By Text, saisissez:
trip_zone_lookup

- Cliquez sur la table et sélectionnez l’onglet Classification et cliquez sur le bouton (+)
- Sélectionnez la classification (PII) à partir de la liste

- Cliquez sur Add pour valider la classification de votre table.
Les colonnes et les bases de données peuvent être classifiées de la même manière.
Afin de consulter toutes les entités faisant partie de la classification PII :
- Naviguez vers l’onglet Classification sur le panel gauche de l’interface Web Atlas
- Sélectionnez la classification
PII. - Toutes les entités faisant partie de cette classification s’affichent sur l’écran principal.

5. Découverte des metadonnées en utilisant le langage spécifique à ATLAS
Atlas peut également permettre de rechercher des entités en utilisant un langage qui lui est spécifique (DSL), qui ressemble au langage SQL.
Ce langage dispose d’une structure simple qui facilite aux utilisateurs la navigation dans l’entrepôt de données d’Atlas. La syntaxe ressemble énormément au très populaire langage SQL qui nous vient du monde des base de données relationnelles.
Afin de rechercher une table en utilisant le DSL Atlas :
- Sélectionnez l’onglet Search. au niveau de l’onglet gauche de l’interface Web Atlas
- Choisissez Advanced Search.
- Dans le champ Search By Type, sélectionnez
hive_table - Dans le champ Search By Query, saisissez la requête suivante pour retrouver la table
trip_details
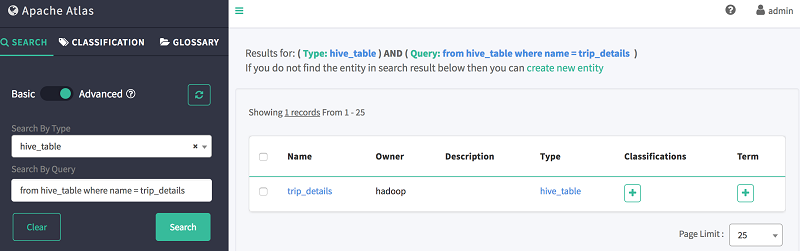
- Sélectionnez l’onglet Search. au niveau de l’onglet gauche de l’interface Web Atlas
- Choisissez Advanced Search.
- Dans le champ Search By Type, sélectionnez
hive_column - Dans le champ Search By Query, saisissez la requête suivante pour retrouver la colonne
location_id
Atlas retrouve bien la colonne au niveau de deux tables créées précédemment :

Il est aussi possible de compter le nombre de tables en utilisant le DSL d’Atlas :
- Sélectionnez l’onglet Search. au niveau de l’onglet gauche de l’interface Web Atlas
- Choisissez Advanced Search.
- Dans le champ Search By Type, sélectionnez
hive_table - Dans le champ Search By Query, saisissez la requête suivante pour trouver le nombre de tables
Atlas renvoie bien le nombre de table comme résultat :

La dernière étape de cet article consiste à nettoyer. Afin d’éviter les coûts non nécessaires, pensez à arrêter votre cluster Amazon EMR une fois vos expérimentations finies.
La manière la plus simple pour cela, si vous avez utilisé CloudFormation, est de supprimer la stack CloudFormation déployée précédemment. Par défaut, le cluster est créé avec une protection contre la terminaison. Afin de pouvoir supprimer le cluster, vous devrez d’abord désactiver la protection contre la terminaison à travers la console Amazon EMR.
Conclusion
Dans cet article, nous avons détaillé les étapes requises pour installer et configurer un cluster Amazon EMR avec Apache Atlas en utilisant la CLI AWS et CloudFormation. Nous avons également exploré la manière avec laquelle il était possible d’importer des données dans Atlas, et utilisé la console de ce dernier pour lancer des requêtes afin de consulter le data lineage, ainsi que toutes les métadonnées.
Pour plus d’information sur Amazon EMR, ou pour tout autre sujet concernant le Big Data sur la plateforme AWS, consultez Les articles Amazon EMR sur le blog AWS Big Data (en anglais)
Article initialement publié par Nikita Jaggi et Andrew Park, respectivement Consultante Big Data Senior et Architecte infrastructure cloud, chez AWS. Traduit en Français par Nadir Djadi, Architect de solutions AWS, LinkedIn.
Article en anglais : https://aws.amazon.com/blogs/big-data/metadata-classification-lineage-and-discovery-using-apache-atlas-on-amazon-emr/