À un moment donné, vous pouvez vous demander :
- Comment puis-je implémenter l’authentification AWS Identity and Access Management (IAM) ou l’autorisation pour Amazon Managed Streaming for Apache Kafka (MSK) ?
- Comment puis-je protéger mon cluster Apache Kafka contre les pics de trafic basés sur des scénarios spécifiques sans définir de quotas sur le cluster ?
- Comment puis-je valider que les requêtes correspondent à un schéma JSON ?
- Comment puis-je m’assurer que les paramètres sont inclus dans l’URI, la query string et les entêtes ?
- Comment Amazon MSK peut-il ingérer des messages depuis des clients légers sans utiliser d’agent ou le protocole Apache Kafka natif ?
Ces tâches sont toutes possibles au travers de serveurs proxy ou de passerelles personnalisées, mais ces options peuvent être difficiles à mettre en œuvre et à gérer. D’un autre côté, API Gateway possède ces fonctionnalités et est un service entièrement opéré par AWS.
Dans cet article, nous vous montrerons comment Amazon API Gateway peut répondre à ces besoins en tant que composant entre votre cluster Amazon MSK et vos clients.
Amazon MSK est un service entièrement opéré par AWS pour Apache Kafka qui facilite la mise en service des clusters Kafka en quelques clics, sans avoir besoin de provisionner des serveurs, de gérer le stockage ou de configurer Apache Zookeeper manuellement. Apache Kafka est une plate-forme open-source pour la création de pipelines et d’applications de streaming en temps réel.
Certains cas d’utilisation incluent l’ingestion de messages provenant d’objets IoT légers qui ne prennent pas en charge le protocole Kafka natif ou l’orchestration de vos services de streaming avec d’autres services back-end, y compris des API tierces.
Ce pattern inclus les compromis suivants :
- Coût et complexité dû à un autre service à exécuter et à maintenir,
- En termes de performance car il ajoute un traitement supplémentaire pour construire et faire des requêtes HTTP. En outre, un proxy REST doit analyser les demandes, transformer les données entre les différents formats, et ce pour produire et consommer les requêtes.
Lorsque vous implémentez cette architecture dans un environnement de production, vous devez tenir compte de ces points en fonction de votre cas d’utilisation métier et de vos SLA.
Aperçu de la solution
Pour implémenter la solution, procédez comme suit :
- Créez un cluster MSK, un client Kafka et un proxy REST Kafka
- Créez un topic Kafka et configurez le proxy REST sur un client Kafka
- Créez une API avec l’intégration du proxy REST via API Gateway
- Testez les processus de bout en bout en produisant et en consommant des messages vers Amazon MSK
Le diagramme suivant illustre l’architecture de la solution :
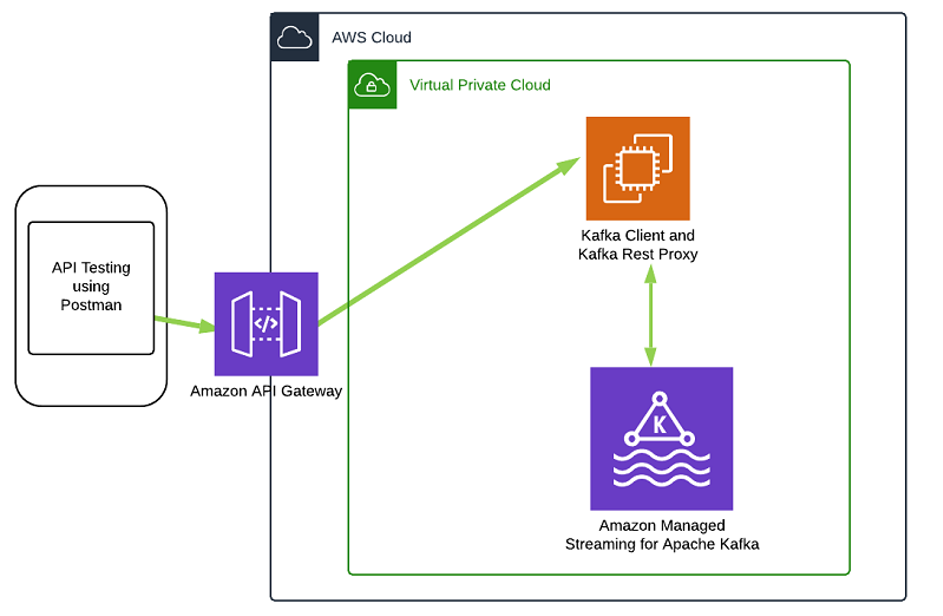
Dans cette architecture, vous créez un cluster MSK et configurez une instance Amazon EC2 avec le proxy REST et le client Kafka. Vous exposez ensuite le proxy REST via Amazon API Gateway et testez également la solution en produisant des messages vers Amazon MSK à l’aide de Postman.
Pour l’implémentation en production, assurez-vous de configurer le proxy REST derrière un ELB avec un groupe Auto Scaling.
Prérequis
Avant de commencer, vous devez disposer des prérequis suivants :
- Un compte AWS qui donne accès aux services AWS,
- Un utilisateur IAM avec une clé d’accès et une clé d’accès secrète pour configurer l’AWS CLI,
- Une paire de clés Amazon EC2.
Création d’un cluster MSK, d’un client Kafka et d’un proxy REST
AWS CloudFormation provisionnera toutes les ressources requises, y compris le VPC, les sous-réseaux, les groupes de sécurité, le cluster Amazon MSK, le client Kafka et le proxy REST. Pour créer ces ressources, procédez comme suit :
- Lancement dans les régions
eu-west-3 (Paris) ou us-east-1 ou us-west-2  . Il faut environ 15 à 20 minutes à CloudFormation pour créer toutes les ressources.
. Il faut environ 15 à 20 minutes à CloudFormation pour créer toutes les ressources.
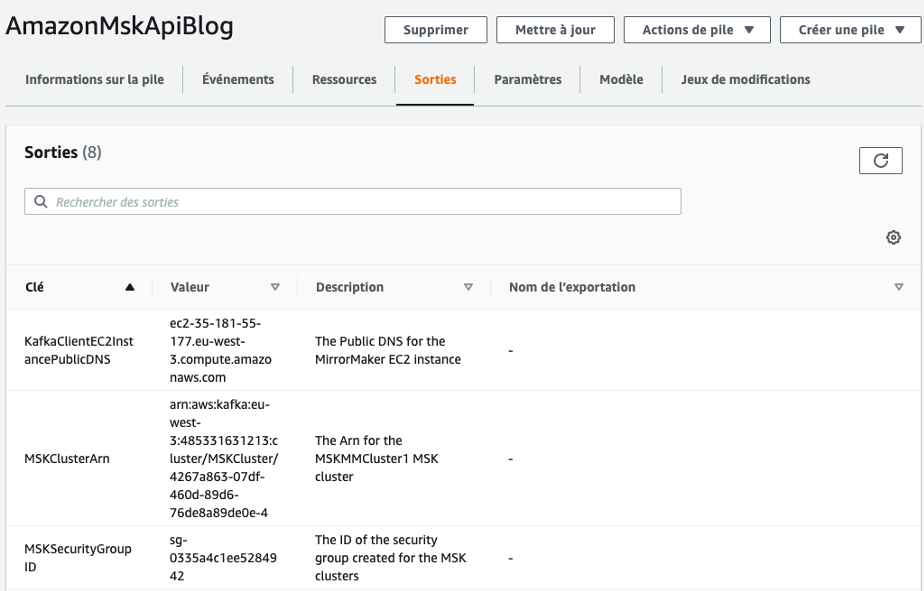
- Dans la console AWS CloudFormation, choisissez AmazonMskApiBlog.
- Sous Outputs, obtenez les détails MskClusterArn, KafkaClientec2InstancePublicDNS et MskSecurityGroupID.
- Récupérez le ZooKeeperConnectionString et d’autres informations sur votre cluster avec la commande suivante (indiquez votre région, l’ARN du cluster et le nom de votre profil AWS) :
$ aws kafka describe-cluster --region <Remplacer_par_us-east-1_or_us-west-2_or_eu-west-3> --cluster-arn <Remplacer_par_votre_cluster-arn> --profile <Remplacer_par_votre_profile>
L’exemple de code suivant montre l’une des lignes de l’output de cette commande :
{
…
…
"ZookeeperConnectString": "z-2.mskcluster.XXXXXX.c4.kafka.eu-west-3.amazonaws.com:2181,z-3.mskcluster.XXXXXX.c4.kafka.eu-west-3.amazonaws.com:2181,z-1.mskcluster.XXXXXX.c4.kafka.eu-west-3.amazonaws.com:2181"
}
- Obtenez le BootStrapBrokerString avec la commande suivante (indiquez votre région, l’ARN du cluster et le nom de votre profil AWS) :
$ aws kafka get-bootstrap-brokers --region <Remplacer_par_us-east-1_or_us-west-2_or_eu-west-3> --cluster-arn <Remplacer_par_votre_cluster-arn> --profile <Remplacer_par_votre_profile>
La commande suivante montre le résultat de cette commande :
{
"BootstrapBrokerString": "b-2.mskcluster.XXXXXX.c4.kafka.eu-west-3.amazonaws.com:9092,b-3.mskcluster.XXXXXX.c4.kafka.eu-west-3.amazonaws.com:9092,b-1.mskcluster.XXXXXX.c4.kafka.eu-west-3.amazonaws.com:9092"
}
Création d’un topic Kafka et configuration d’un proxy REST Kafka.
Pour créer un topic Kafka et configurer un proxy REST Kafka sur un client Kafka, procédez comme suit :
- Connectez-vous en SSH à votre instance Amazon EC2. Nous vous recommandons d’utiliser AWS Systems Manager pour des environnements de production afin d’augmenter le niveau de sécurité. Avec la commande suivante :
ssh -i <Remplacer_par_votre_fichier_pem> ec2-user@<Remplacer_avec_le_dns_du_client_kafka>
- Allez dans le dossier bin (
kafka/kafka_2.12-2.2.1/bin/) de l’installation Kafka sur l’instance EC2.
- Créez un topic avec la commande suivante (indiquez la valeur que vous avez obtenue pour ZookeeperConnectString à l’étape précédente) :
/kafka-topics.sh --create --zookeeper <Remplacer_par_la_valeur_ZookeeperConnectString> --replication-factor 3 --partitions 1 --topic amazonmskapigwblog
Si la commande réussit, le message suivant s’affiche: Created topic amazonmskapigwblog
- Pour connecter le server REST au cluster Amazon MSK, modifiez le fichier
kafka-rest.properties dans le répertoire (/home/ec2-user/confluent-5.3.1/etc/kafka-rest/) pour le pointer vers les URLs de connection ZookeeperConnectString et BootstrapserversConnectString de votre cluster AmazonMSK.
sudo vi /home/ec2-user/confluent-5.3.1/etc/kafka-rest/kafka-rest.properties
zookeeper.connect=<Remplacer_par_la_valeur_ZookeeperConnectString>
bootstrap.servers=< Remplacer_par_la_valeur_BootstrapConnectString >
Comme étape supplémentaire et facultative, vous pouvez mettre en place une connection SSL pour sécuriser la communication entre les clients REST et le proxy REST (HTTPS). Si SSL n’est pas requis, vous pouvez ignorer les étapes suivantes.
- Générez les certificats serveur et client. Plus d’informations sur le site de Confluent
- Ajoutez les configurations de propriétés nécessaires au fichier de configuration kafka-rest.properties. Voir l’exemple de code suivant :
listeners=http://0.0.0.0:8082,https://0.0.0.0:8085
ssl.truststore.location=<Replace_With_Your_tuststore.jks>
ssl.truststore.password=<Replace_With_Your_tuststorepassword>
ssl.keystore.location=<Replace_With_Your_keystore.jks>
ssl.keystore.password=<Replace_With_Your_keystorepassword>
ssl.key.password=<Replace_With_Your_sslkeypassword>
Pour obtenir des instructions plus détaillées, consultez la section Encryption et Authentification avec SSL sur le site web de Confluent.
Vous avez maintenant créé un topic Kafka et configuré le proxy REST Kafka pour vous connecter à votre cluster Amazon MSK.
Création d’une API avec l’intégration du proxy
Pour créer une API avec l’intégration de Proxy REST Kafka via API Gateway, procédez comme suit :
- Dans la console API Gateway, choisissez Créer une API.
- Pour le type d’API, choisissez API REST
- Choisissez Build
- Choisissez Nouvelle API
- Pour Nom d’API, entrez un nom (par exemple, amazonmsk-restapi)
- Comme étape facultative, pour Description, entrez une brève description
- Choisissez Créer une API. L’étape suivante consiste à créer une ressource enfant
- Sous Ressources, sélectionnez un élément de ressource parent
- Sous Actions, choisissez Créer une ressource. Le volet Nouvelle ressource enfant s’ouvre.
- Sélectionnez Configurer en tant que ressource proxy.
- Pour Nom de la ressource, entrez proxy.
- Pour Chemin de ressource, saisissez /{proxy+}.
- Sélectionnez Activer le CORS d’API Gateway.
- Choisissez Créer une ressource.
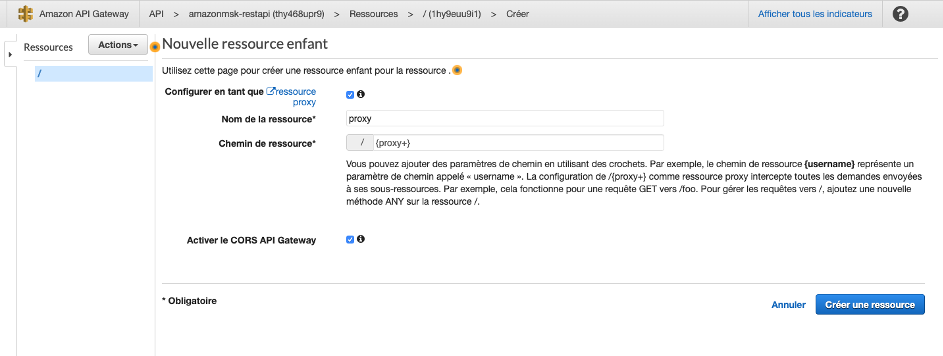
Après avoir créé la ressource, la fenêtre Créer une méthode s’ouvre.
- Pour Type d’intégration, sélectionnez Proxy HTTP
- Pour URL de point de terminaison, entrez une URL de ressource de backend HTTP (le DNS Public de votre instance Amazon EC2 Kafka Client; par exemple,
http://KafkaClientEC2InstancePublicDNS:8082/{proxy} ou https://KafkaClientEC2InstancePublicDNS:8085/{proxy}).
- Utilisez les paramètres par défaut pour les champs restants
- Choisissez Enregistrer
- Si vous utilisez SSL, pour URL de point de terminaison, utilisez le point de terminaison HTTPS
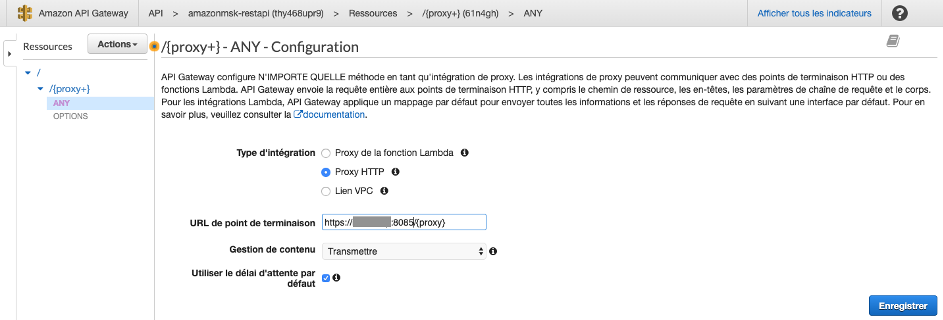
Dans l’API que vous venez de créer, le chemin de ressource de {proxy+} devient l’espace réservé de l’un des points de terminaisons backend http://KafkaClientEC2InstancePublicDNS:8082/
- Choisissez l’API que vous venez de créer
- Sous Actions, choisissez Déployer l’API
- Pour Etape de déploiement, choisissez Nouvelle étape
- Pour Nom de l’environnement, entrez le nom de l’environnement (par exemple,
dev, test ou prod)
- Cliquez sur Déployer

- Enregistrez l’URL après avoir déployé l’API

- Votre proxy REST Kafka, qui a été exposé via API Gateway, ressemble maintenant à
https://VotreURLApiGateway/dev/topics/amazonmskapigwblog. Vous utilisez cette URL à l’étape suivante.
Test des processus de bout en bout
Pour tester les processus de bout en bout en produisant et en consommant des messages à Amazon MSK. Procédez comme suit :
- Connectez-vous en SSH à l’instance Amazon EC2 du client Kafka avec la ligne de commande suivante :
ssh -i "xxxxx.pem" ec2-user@KafkaClientEC2InstancePublicDNS
- Allez dans le répertoire confluent-5.3.1/bin et démarrez le service kafka-rest avec la commande suivante :
./kafka-rest-start /home/ec2-user/confluent-5.3.1/etc/kafka-rest/kafka-rest.properties. Si le service a déjà démarré, vous pouvez l’arrêter avec la ligne de commande suivante : ./kafka-rest-stop /home/ec2-user/confluent-5.3.1/etc/kafka-rest/kafka-rest.properties
- Ouvrez une autre fenêtre de terminal
- Dans le répertoire
kafka/kafka_2.12-2.2.1/bin, démarrez le Kafka console consumer avec la ligne de commande suivante : ./kafka-console-consumer.sh --bootstrap-server "BootstrapserversConnectString" --topic amazonmskapigwblog --from-beginning. Vous pouvez désormais produire des messages à l’aide de Postman. Postman est un client HTTP pour tester les services Web. Assurez-vous d’ouvrir les ports TCP sur le groupe de sécurité du client Kafka pour votre IP
- Dans Headers, sélectionnez la clé Content-Type et la valeur
application/vnd.kafka.json.v2+json
- Dans Body, sélectionnez raw
- Choisissez JSON. Cela génère le code suivant :
{"records":[{"value":{"deviceid": "AppleWatch4","heartrate": "72","timestamp":"2019-10-07 12:46:13"}}]}
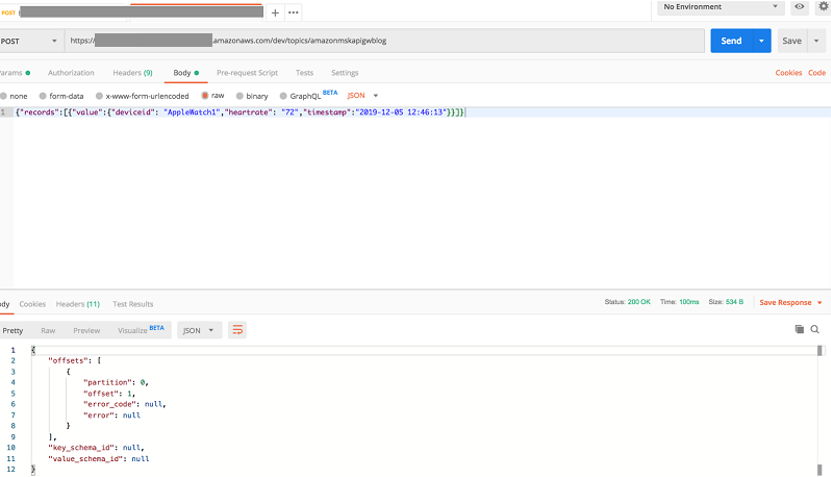
La capture d’écran suivante montre les messages envoyés au consommateur Kafka à partir du point de terminaison REST API Gateway.

Conclusion
Cet article a illustré comment configurer des points de terminaison REST pour Amazon MSK avec API Gateway. Cette solution peut vous aider à produire et à consommer des messages vers Amazon MSK à partir de n’importe quel appareil IoT ou langage de programmation sans dépendre du protocole ou des clients Kafka natifs.
Article original par Prasad Alle, Senior Big Data Consultant, et Francisco Oliveira, Senior Solutions Architect Data Lakes & Analytics. Traduit de l’anglais par Jean-Robin Foehn, Solutions Architect accompagnant les clients français dans leur transformation digitale et leur adoption du cloud.