Quelle est la différence entre la science des données et l’intelligence artificielle ?
Quelle est la différence entre la science des données et l’intelligence artificielle ?
La science des données et l’intelligence artificielle (IA) sont des termes généraux désignant les méthodes et techniques liées à la compréhension et à l’utilisation des données numériques. Les organisations modernes collectent des informations à partir de divers systèmes physiques et en ligne sur tous les aspects de la vie humaine. Nous disposons de données textuelles, audio, vidéo et d’images en grande quantité. La science des données combine des outils, des méthodes et des technologies statistiques pour générer du sens à partir des données. L’intelligence artificielle va encore plus loin et utilise les données pour résoudre les problèmes cognitifs généralement associés à l’intelligence humaine, tels que l’apprentissage, la reconnaissance des formes et l’expression humaine. Il s’agit d’un ensemble d’algorithmes complexes qui « apprennent » au fur et à mesure et améliorent leur capacité à résoudre les problèmes au fil du temps.
Similitudes entre la science des données et l’intelligence artificielle
L’IA et la science des données incluent des outils, des techniques et des algorithmes permettant d’analyser et d’utiliser de grands volumes de données. Voici quelques points communs.
Applications prédictives
Les technologies de l’intelligence artificielle et de la science des données permettent toutes deux de faire des prédictions sur la base de nouvelles données, en appliquant des modèles et des méthodes appris lors de l’analyse de données précédentes. Par exemple, la prévision des ventes mensuelles futures de parapluies sur la base des données des années précédentes est un exemple d’analyse de données de séries temporelles dans le cadre de la science des données.
De même, une voiture autonome est un exemple de système d’intelligence artificielle prédictive. Lorsqu’une voiture autonome circule, elle calcule la distance par rapport à la voiture qui précède et la vitesse des deux voitures. Elle maintient sa vitesse à un rythme qui permettrait d’éviter un accident, en prédisant le freinage brusque de la voiture qui le précède.
Exigences relatives à la qualité des données
Tant les technologies de l’IA que celles de la science des données donnent des résultats moins précis si les données d’apprentissage sont incohérentes, biaisées ou incomplètes. Par exemple, la science des données et les algorithmes d’IA peuvent :
- filtrer les nouvelles données si elles sont complètement nouvelles et ne font pas partie de leur jeu de données d’origine.
- prioriser les attributs spécifiques au jeu de données par rapport à tous les autres si les données d’entrée ne variaient pas.
- créer des informations inexistantes ou fictives en raison de l’inexactitude des données d’entrée.
Machine learning
Le machine learning (ML) est considéré comme un sous-type à la fois de la science des données et de l’IA. Cela signifie que tous les modèles ML sont considérés comme des modèles de science des données et que tous les algorithmes de ML sont également considérés comme des algorithmes d’IA. Il existe une idée fausse courante selon laquelle toutes les IA utilisent le ML, mais ce n’est pas le cas. Le ML n’est pas toujours nécessaire dans les solutions d’IA complexes. De même, toutes les solutions de science des données n’impliquent pas le ML.
Principales différences : la science des données par rapport à l’intelligence artificielle
La science des données consiste à analyser les données afin de déterminer les tendances sous-jacentes et les points d’intérêt permettant d’établir des prévisions. La science des données appliquée utilise les modèles et les méthodes utilisés dans l’analyse des données et les applique à de nouvelles données dans des situations réelles afin de produire des résultats probabilistes. En revanche, l’IA utilise des techniques de science des données appliquées et d’autres algorithmes pour composer et exécuter des systèmes complexes basés sur des machines qui se rapprochent de l’intelligence humaine.
La science des données peut également être utilisée dans des applications autres que l’IA et l’informatique.
Objectifs
L’objectif de la science des données est d’appliquer les modèles et méthodes statistiques et informatiques existants pour comprendre les points d’intérêt ou les tendances des données collectées. Les résultats sont prédéterminés et faciles à définir dès le départ. Par exemple, vous pouvez utiliser les données pour prévoir les ventes futures ou déterminer quand une machine est prête à être réparée.
L’objectif de l’IA est d’utiliser des ordinateurs pour produire un résultat à partir de nouvelles données complexes qui ne peuvent être distinguées du raisonnement humain intelligent. Les résultats sont génériques et difficiles à définir : par exemple, la génération de texte créatif ou la génération d’images à partir de texte. Les détails de l’ensemble des problèmes sont trop importants pour être définis avec précision et le système d’IA interprète le problème par lui-même.
Champ d’application
La science des données a une portée plus restreinte, car le résultat est prédéterminé. Le processus commence par l’identification des questions auxquelles il est possible de répondre à partir des données. Le champ d’application comprend :
- La collecte et le prétraitement des données.
- L’application de modèles et d’algorithmes appropriés aux données pour répondre à ces questions.
- L’interprétation des résultats.
En revanche, l’IA a une portée beaucoup plus large et les étapes varient en fonction du problème à résoudre. Le processus commence par l’identification d’une tâche manuelle nécessitant une main-d’œuvre importante ou d’une tâche de raisonnement complexe que les humains exécutent avec succès et que nous voulons que la machine reproduise. Le champ d’application peut inclure :
- L’analyse exploratoire des données.
- La division de la tâche en composants algorithmiques dans le but de former un système.
- La collecte de données de test dans le but d’examiner et d’affiner l’adéquation du flux logique et la complexité du système.
- Le test du système.

Méthodes
La science des données dispose d’un large éventail de techniques pour modéliser les données. Le choix de la bonne technique dépend des données et de la question posée. Il s’agit notamment de la régression linéaire, de la régression logistique, de la détection des anomalies, de la classification binaire, du regroupement des k-moyennes, de l’analyse en composantes principales et bien d’autres encore. Une analyse statistique mal appliquée produira des résultats inattendus.
Les applications d’IA reposent généralement sur des composants complexes, préconstruits et industrialisés. Il peut s’agir de la reconnaissance faciale, du traitement du langage naturel, de l’apprentissage par renforcement, des graphes de connaissances, de l’intelligence artificielle générative (IA générative) et bien d’autres encore.
Applications : la science des données comparée à l’intelligence artificielle
La science des données peut être appliquée partout où il existe suffisamment de données de qualité et un modèle pour aider à répondre à une question particulière. Les applications incluent :
- Prévision de la demande.
- Détection des fraudes.
- Cotes sportives.
- Évaluation des risques.
- Prévisions de consommation d’énergie.
- Optimisation des revenus.
- Processus de sélection des candidats.
Les applications de l’IA sont quasiment infinies. Les applications les plus populaires incluent :
- Lignes de production robotisées.
- Chatbots.
- Systèmes de reconnaissance biométrique.
- Analyse d’imagerie médicale.
- Maintenance prédictive.
- Urbanisme.
- Personnalisation du marketing.
Carrières : la science des données comparée à l’intelligence artificielle
L’objectif principal d’un scientifique des données est généralement technique, c'est-à-dire qu'il travaille en profondeur dans les données. Les scientifiques des données peuvent travailler sur la collecte et le traitement des données, en choisissant les bons modèles pour les données et en interprétant les résultats pour formuler des recommandations. Le travail peut être effectué dans le cadre de logiciels ou de systèmes spécifiques, ou même dans le cadre de systèmes de construction eux-mêmes.
Types de rôles
Les emplois en science des données incluent des postes de scientifique des données, d’analyste de données, d’ingénieur des données, d’ingénieur en machine learning, de chercheur, de spécialiste de la visualisation de données, des rôles d’analyste spécifiques à un domaine, etc. L’IA englobe également tous ces rôles. Cependant, la portée du domaine étant si vaste, il existe de nombreux autres rôles et domaines d’activité associés, tels que développeur de logiciels, chef de produit, spécialiste du marketing, testeur d’IA, ingénieur IA, etc.
Ensemble de compétences
Les scientifiques des données ont des compétences dans l’application pratique de méthodes statistiques et algorithmiques pour qualifier et analyser les données afin de trouver des informations pertinentes. Les scientifiques des données ont besoin d’une formation en mathématiques statistiques et en informatique et d’une maîtrise des outils applicables.
Selon le rôle au sein de l’IA, les compétences requises peuvent être davantage techniques ou non techniques. Pour certains rôles, il se peut qu’aucune expérience technique ne soit requise. Par exemple, un développeur de logiciels d’IA aurait besoin de connaissances pratiques sur les langages de programmation, les bibliothèques et les outils pertinents. Cependant, un testeur d’IA pour un outil d’IA générative nécessiterait des compétences linguistiques, une pensée créative et une compréhension de la manière dont les utilisateurs devraient interagir avec le système.
Progression de carrière
À mesure que les outils et les flux de travail liés à la science des données sont de plus en plus automatisés et produits, le nombre de rôles relevant uniquement de la science des données diminue. Les professionnels de la science des données à la recherche de rôles purement scientifiques ont tendance à se tourner vers des applications académiques et de pointe. Les rôles d’analyste dans lesquels le scientifique des données est propriétaire du fonctionnement des outils restent pertinents. À partir d’un poste débutant, les scientifiques des données accèdent à des postes plus élevés, passent à la gestion des personnes ou à la gestion de projets, et passent même au poste de directeur des données.
Selon l’objectif du rôle de l’IA lui-même, une progression de carrière peut être attendue de la même manière. Vous pouvez passer au poste de directeur de la technologie, de directeur du marketing, de directeur des produits, etc. Réfléchir de manière critique aux emplois qui seront automatisés au cours des dix prochaines années peut contribuer à pérenniser l’orientation de carrière.
Résumé des différences : la science des données par rapport à l’intelligence artificielle
|
Science des données |
Intelligence artificielle |
|
|
Qu'est-ce que c'est ? |
L’utilisation de la modélisation statistique et algorithmique pour obtenir des informations à partir des données. |
L’IA est un terme générique désignant les applications basées sur des machines qui imitent l’intelligence humaine. |
|
Idéal pour |
répondre à une question à partir d’un ensemble de données. |
accomplir efficacement une tâche humaine complexe. |
|
Methods |
Régression linéaire, régression logistique, détection d’anomalies, classification binaire, regroupement des k-moyennes, analyse en composantes principales, etc. |
Reconnaissance faciale, traitement du langage naturel, apprentissage par renforcement, graphes de connaissances, IA générative, etc. |
|
Champ d’application |
Questions prédéfinies auxquelles il est possible de répondre à partir des données. |
Large et difficile à définir, axé sur les tâches. |
|
Mise en œuvre |
Utilise différents outils pour capturer, nettoyer, modéliser, analyser et générer des rapports sur les données. |
En fonction de la tâche. S’appuie généralement sur des composants complexes, préconstruits et industrialisés. |
Comment AWS peut répondre à vos besoins en matière de science des données et d’intelligence artificielle ?
AWS propose une gamme complète de produits et services de science des données et d’IA conçus pour vous aider à renforcer et à développer l’intelligence et l’analytique des données organisationnelles et individuelles.
Cela inclut des modèles de science des données et d’IA basés sur des API pour les données structurées et non structurées et des environnements entièrement gérés qui permettent la création et le déploiement de bout en bout de solutions de science des données et d’IA.
- Amazon SageMaker Studio est un environnement de développement intégré (IDE) qui inclut une pile d’outils spécialement conçue pour développer des solutions de science des données et de machine learning.
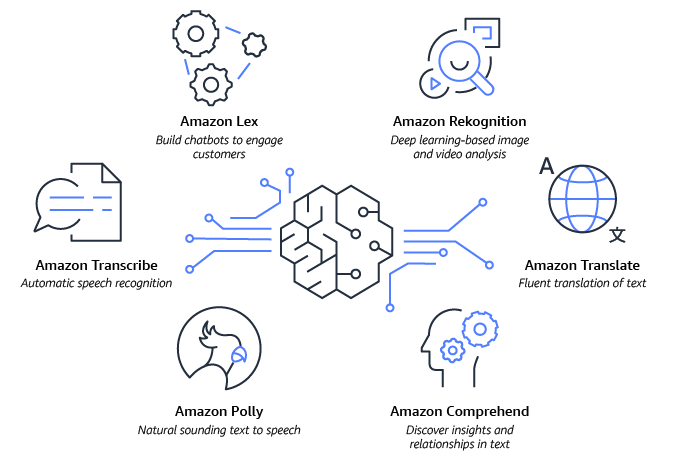
- Amazon Lex vous aide à créer vos propres chatbots grâce à l’IA conversationnelle.
- Amazon Rekognition offre des fonctionnalités de vision par ordinateur (CV) pré-entraînées et personnalisables pour extraire des informations de vos images et vidéos.
- Amazon Comprehend vous aide à tirer des informations précieuses du texte contenu dans les documents et à les comprendre.
- Amazon Personalize exploite le machine learning pour vous aider à personnaliser l’expérience client.
- Amazon Forecast permet d’effectuer des prévisions sur des séries temporelles.
- Amazon Fraud Detector vous aide à créer, déployer et gérer des modèles de détection des fraudes.
AWS propose également une liste croissante de solutions d’IA générative de classe mondiale capables de créer de nouveaux contenus et de nouvelles idées, notamment des conversations, des histoires, des images, des vidéos et de la musique. Les solutions d’IA générative incluent :
- Amazon Bedrock aide les entreprises à créer et à mettre à l’échelle des solutions d’IA générative.
- AWS Trainium permet d’entraîner plus rapidement des modèles d’IA générative.
- Amazon Q Developer est un assistant de développement de logiciels basé sur l’IA générative.
Commencez à utiliser la science des données et l’intelligence artificielle sur AWS en créant un compte dès aujourd’hui.
Browse all cloud computing concepts
Browse all cloud computing concepts content here:
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages