Amazon Web Services ブログ
Category: Analytics

AWS Summit Japan 2026 ブース紹介 生産ラインの未来
急な需要の変化に対して、工場の生産ラインをもっと柔軟に変更したいと言う困りごとはないでしょうか。このブログでは、AWS Summit Japan 2026 の 製造展示の中から生産ラインの未来のテーマをご紹介しています。 AI エージェント、デジタルツイン、ソフトウェアで定義された工場のキーワードで、需要の変化に追随できる新しい工場の姿をご紹介しています。
Amazon Redshift Data Sharing を活用した位置情報ビッグデータ分析基盤の進化 ~KDDI Location Analyzer の新機能開発事例~
本ブログは、KDDI株式会社 高山 伸也 氏、アマゾン ウェブ サービス ジャパン合同会社 ソリューションアー […]

2026 AWS Life Sciences Symposium ハイライト:創薬研究領域
英語版ブログ: “ Highlights from the 2026 AWS Life Sciences Sy […]
Fivetran の CDC 機能で実現するラーメン山岡家の Iceberg on AWS データパイプライン
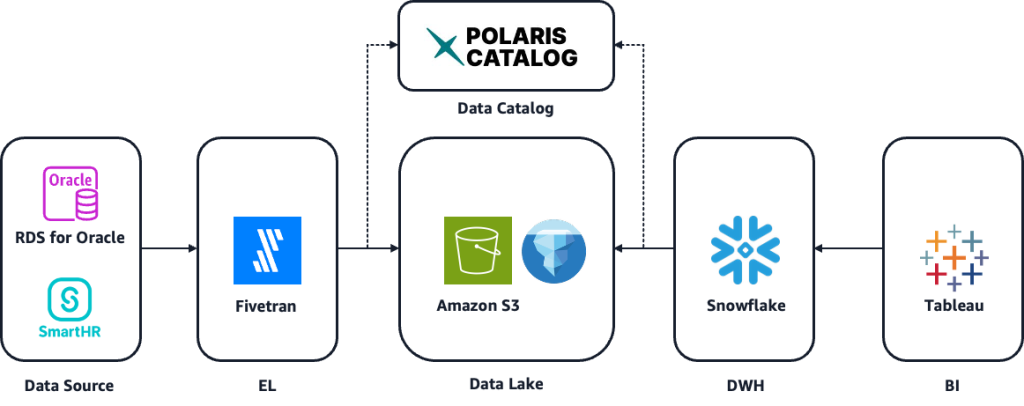
ラーメンチェーン「山岡家」を展開する株式会社丸千代山岡家が、Fivetran の CDC(Change Data Capture)機能を活用して Amazon RDS for Oracle から Amazon S3 上の Apache Iceberg テーブルへのデータ同期を実現した事例をご紹介します。アーキテクチャの検討プロセスや Fivetran 採用の理由、約 5 分のデータ反映、月あたりの運用工数を 6 日から 0.5 日に削減、PoC から本番稼働まで約 1 ヶ月という短期導入といった導入効果を解説します。

AWS Weekly Roundup: AWS での Claude Opus 4.8、Kiro Powers を利用する Aurora MySQL など (2026 年 6 月 1 日)
私の前回の Week in Review の記事では、私が開催している AI-Driven Developme […]

AI エージェントアプリケーションを構築する次世代 Amazon OpenSearch Serverless の発表
AI エージェント向けにフルマネージドの検索およびベクトルエンジン、次世代 Amazon OpenSearch Serverless を発表します。コンピューティングリソースをゼロから 1 秒あたり数千リクエストを処理できる規模までスケールアップし、アイドル時はゼロまでスケールダウン。ピーク容量にプロビジョニングしたクラスターと比べて最大 60% のコスト削減を実現します。

次世代の Amazon OpenSearch Serverless: エージェント向けにゼロから構築
Amazon OpenSearch Serverless のアーキテクチャをゼロから刷新し、オートスケーリングが従来比で最大 20 倍に高速化、コンピューティングをゼロまでスケール可能、ピーク負荷に合わせたプロビジョニングと比べて最大 60% のコスト削減を実現した次世代アーキテクチャ NextGen を発表します。コンピューティングとストレージを完全に分離し、エージェントワークロードに最適化されました。本記事ではアーキテクチャの仕組みと、ハンズオンチュートリアルでの使い始め方を解説します。

AWS Weekly Roundup: イスタンブールの AWS ローカルゾーン、オープンソースの ExtendDB、Kiro Web など (2026 年 5 月 25 日)
スタートアップとの仕事には、本当に刺激的な何かがあります。私は 2 年以上にわたって、このような仕事に精力的に […]

寄稿:生成 AI で“探せなかった開示情報”を見つけ出す 〜 JPX の AI 開示情報検索サービス J-LENS〜
本稿は、日本取引所(以下「JPX」)グループの戦略的なデータ・デジタル事業を担う株式会社 JPX 総研による「 […]

AWS における AI エージェント対応のデータ基盤 (2) — SageMaker Catalog で行・列レベルのアクセス権を透過的に適用する
本記事は、シリーズ「AWS における AI エージェント対応のデータ基盤」の第 2 回です。第 1 回では、A […]