Amazon Web Services ブログ
Category: Analytics

Amazon Redshift Serverless と Tableau の統合を最適化する
本記事では、Tableau と Amazon Redshift Serverless の統合を最適化するための戦略を紹介します。データモデルアーキテクチャ、セキュリティ構成、パフォーマンス最適化、コスト管理、クエリ最適化の 5 つの領域について、RPU を最大限に活用しながらサブ秒レベルのインサイトを提供するためのベストプラクティスを解説します。

Amazon OpenSearch Service の新エンジンでログ分析コストを大幅に削減
Amazon OpenSearch Service にログ分析に特化した新エンジンが加わりました。価格性能比は最大 4 倍、取り込み速度は 2 倍、ストレージコストは最大 70% 削減されます。OpenSearch の強みである全文検索も犠牲にならず、同じデータに対してそのまま使えます。

AWS Weekly Roundup: Amazon Connect Customer 向け Agentic CX Designer、EC2 AMI ウォーターマーク、MySQL 向けのオープンガバナンスなど (2026 年 6 月 29 日)
AWS Summit が各地で開催されており、多忙な日々を過ごしています。私は New York City S […]

Amazon Quick on Desktop が東京リージョンに対応 – AWS Summit New York 2026 アップデート –
Amazon Quick on Desktop が AWS アジアパシフィック (東京) リージョンで利用可能になりました。本ブログでは、Amazon Quick on Desktop の機能やアップデートについて紹介します。

もぐもぐ AWS – 現場の SA が語るお昼 30 分の技術トーク
昼休み30分でAWSの最新AI技術をキャッチアップ。現場のソリューションアーキテクトが配信。AIエージェント、Bedrock、セキュリティまで。参加無料。
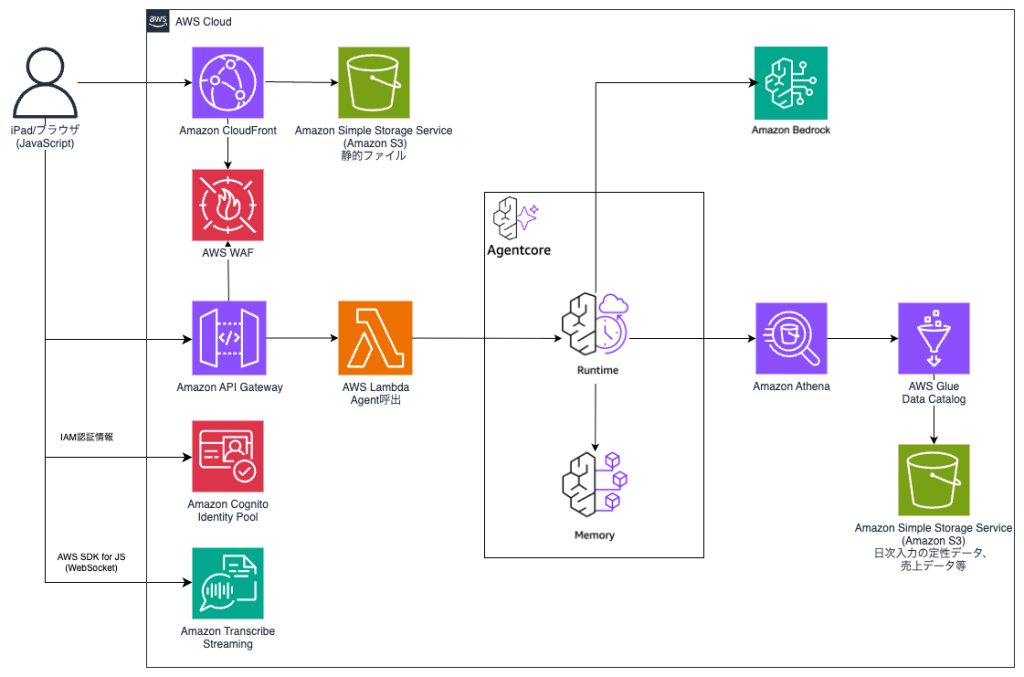
店舗の気づきを本部に届ける AI エージェント SMART のご紹介 — Amazon Bedrock AgentCore × Strands Agents によるユナイテッドアローズでの取り組み
本記事では、AWS サンプルアセットである AI エージェント SMART(Store Manager Agent for Retail Tech) についてのご紹介と、それを活用した株式会社ユナイテッドアローズ(以下、ユナイテッドアローズ)の取り組みについてご紹介します。小売業にとって、店舗の声をどう本部に届けるかは永遠のテーマです。売上数字の裏には、現場スタッフだけが感じている気づきが必ずあります。しかし店舗の日報や週報のフォーマットだけでは、その気づきを届けるのは難しいのが実情です。SMART は、店舗の気づきを AI の力で引き出し言語化して、本部に届けることを支援するために誕生しました。
Accelerating Smart Product SDLC with AI Agent Workshop のご紹介
IoT やコネクテッドデバイスの普及により、製造業の製品はハードウェア単体からソフトウェアで価値を提供する「ス […]

Amazon OpenSearch Service による「EC サイト検索ワークショップ」と「Observability Stack ワークショップ」のご紹介
2025 年 3 月に Amazon OpenSearch Service による検索ワークショップ(日本語版)のご紹介 という記事を公開し、OpenSearch の基本概念から AI を活用した検索までを学べる日本語ワークショップをご案内しました。
このたび、2 つの日本語版ワークショップが仲間入りいたしましたので、ご紹介いたします。
EC サイト検索ワークショップ:架空の EC サイトを題材に、検索機能を全文検索からセマンティック検索、マルチモーダル検索、エージェント検索へと段階的に育てていくワークショップです。また、ユーザーの行動ログを使った品質計測、機械学習による最適化を体験いただける実験的なラボも付属しています。
OpenSearch Observability Stack ワークショップ:OpenSearch を Observability のバックエンドとして使い、マイクロサービスの APM・ログ・メトリクスを横断しながら、Agentic AI も活用して障害の原因を調査するワークショップです。Agent Trace といった新しい OpenSearch の Observability 関連機能もお試しいただけます。
AWS Summit Japan 2026 〜 広告・マーケティングブースのご案内
こんにちは。広告・マーケティング業界を担当するソリューションアーキテクトチームです。いよいよ 6 月 25 日 […]

実践企業に学ぶ生成 AI 導入の勘所 〜眠るデータを企業価値に変える〜 – AWS Local Executive Roadshow 名古屋編(#3/8)開催レポート
こんにちは。Amazon Web Services Japan のソリューションアーキテクト、田中 里絵 です […]