Amazon Web Services ブログ
Category: Artificial Intelligence

オープンウェイトモデル( gpt-oss )の日本語精度は? – AWS パートナー アクロクエストによる徹底検証
2025年8月にAmazon Bedrock上で利用可能になったOpenAIのオープンウェイトモデル「gpt-oss」」の日本語能力を、AWSパートナーのアクロクエストテクノロジー様に検証いただきました。
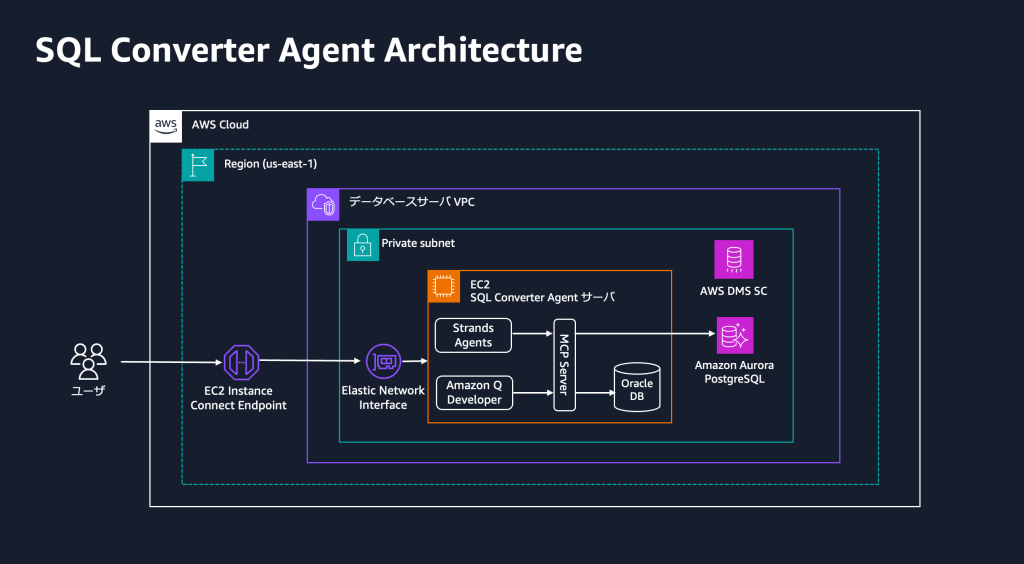
Oracle Database から Amazon Aurora PostgreSQL への移行を加速する生成 AI エージェント
本ブログは三菱電機ビルソリューションズ株式会社様と Amazon Web Services Japan 合同会 […]

AWS re:Invent 2025 広告・マーケティングテクノロジーのためのガイド
本記事は 2025 年 11 月 20 日に公開された Anthony Hayes による “Your gui […]

AI ワークロードのパフォーマンスとコストの一致に役立つ新しい Amazon Bedrock サービスティア
2025 年 11 月 18 日、アプリケーションに必要なパフォーマンスレベルを維持しながら、AI ワークロー […]

週刊生成AI with AWS – 2025/11/17 週
週刊生成AI with AWS, 充実の2025年11月17日週号 – 三遠ネオフェニックス様、NTT西日本様・エルガナ様、ANAシステムズ様の国内事例ブログを紹介。Kiro Week in Japan特集として5日間の連載記事とre:Invent 2025セッションガイドを公開。サービスアップデートでは、SageMaker の AI エージェント機能、Bedrock の Model Import 拡張と Priority/Flex ティア、EC2 P6 B300 インスタンス、Polly 生成的TTSエンジンをはじめとする23件のアップデートを紹介。

イベントストーミングから要件・設計・タスクへ。Kiro を活用した仕様駆動開発
イベントストーミングは、ビジネスの流れを可視化し、業務のエキスパートや開発メンバーが同じ理解を持てるようにするためのプラクティスです。Big Picture を使ってサブドメイン間の関係性を整理したり、業務内容をコードに落とし込むための設計に活用したりと、業務分析から設計まで幅広く役立ちます。しかし、イベントストーミングで得られた成果物を「どこから実装に落とし込むのか」「どうテストするのか」といった部分は、開発者がつまずきやすいポイントではないでしょうか。
本ブログでは、Kiro の Spec 機能を活用して、イベントストーミングの成果物を要件定義・設計・実装タスクへと変換していくプロセスを紹介します。

道に迷わないために: Kiro のチェックポイント機能の紹介
このブログでは、Kiro のチェックポイント機能についてご紹介します。チェックポイント機能は、開発セッション中の任意の時点に Kiro の変更を巻き戻す力を与えます。Kiro がコードベースを変更すると、チャット履歴に自動的にチェックポイントマーカーが作成されます。ビデオゲームのオートセーブポイントのようなものだと考えてください。物事がうまくいかず、想定以上のダメージを受けた場合、以前のチェックポイントに戻って別のアプローチを試すことができます。

Kiro を組織で利用するためのセキュリティとガバナンス
本ブログは Kiroweeeeeek (X:#kiroweeeeeeek) の第 3 日目です。本ブログでは、Kiro を組織で利用するにあたって気になるセキュリティとガバナンス機能についてご紹介します。

三遠ネオフェニックス様の AWS 生成 AI 事例「Amazon Bedrock と Step Functions を活用したバスケットボール・スカウティングレポート自動生成システムの構築」のご紹介
本記事では、三遠ネオフェニックス様が、AWS Step Functions と Amazon Bedrock を活用し、生成 AI による AI Analyst 機能を構築されましたので、その事例をご紹介します。
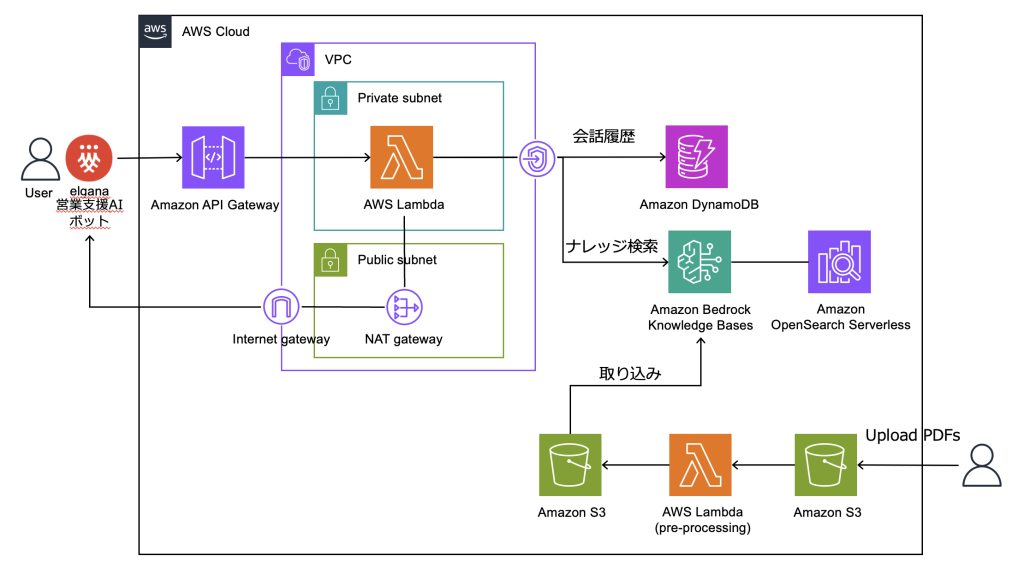
NTT西日本の AWS 事例:Amazon Bedrock Knowledge Bases を活用した営業支援 AI ボットの開発
本ブログでは、NTT西日本の寄稿により、Amazon Bedrock Knowledge Bases を活用した営業支援 AI ボットについて、取り組み背景、実現方法、トライアル結果について解説します