Amazon Web Services ブログ
Amazon OpenSearch Serverless による手軽なログ分析
この記事は、Log analytics the easy way with Amazon OpenSearch Serverless を翻訳したものです。
先日、Amazon OpenSearch Service の新しいサーバーレスオプションである Amazon OpenSearch Serverless が発表されましたが、これにより OpenSearch クラスターを構成、管理、スケールする手間なく大規模な検索および分析ワークロードを容易に実行することができます。非常に要求が厳しく予測不可能なワークロードに対しても高速なデータ取り込みとクエリ応答を実現するために、基盤となるリソースを自動的にプロビジョニングし、スケールします。
OpenSearch Serverless は主に 2 つのユースケースをサポートしています。
- 運用、セキュリティ、ユーザー行動に関する洞察を得るための、機械が生成する大規模な半構造化時系列データの分析に重きを置いたログ分析
- 内部ネットワーク内の顧客アプリケーション (コンテンツ管理システムや法的文書) や、インターネット向けのアプリケーション (E コマースサイトのカタログ検索やコンテンツ検索) を強化するための全文検索
この記事では、OpenSearch Serverless を使用したシンプルなログ分析パイプラインの構築に焦点を当てます。
ソリューション概要
以下のセクションでは、OpenSearch Serverless でコレクションを作成してアクセスする手順を説明し、コレクションにデータをインデックス化するための 2 つの異なるデータ取り込みパイプラインを実演します。
コレクションを作成する
OpenSearch Serverless を使い始めるには、まずコレクションを作成します。OpenSearch Serverless のコレクションは、分析ワークロードを表す 1 つまたは複数のインデックスの論理的なグループです。
次の図は、コレクションを作成するためのクイックな手順を示しています。また、OpenSearch Serverless でコレクションを作成し設定する方法についてさらに知りたい場合は、このブログ記事を参照してください。
コレクションにアクセスする
AWS Identity and Access Management (IAM) ユーザーやロールのシークレットキーとアクセスキー ID を持つ IAM 認証情報を使用して、プラグラム的にコレクションにアクセスすることすることができます。または、OpenSearch ダッシュボードにアクセスするために、SAML 認証を設定することもできます。SAML 認証は OpenSearch のダッシュボードへのアクセスにのみ利用できることに注意してください。つまり、データのインデックス化や検索を行うためには、AWS Command Line Interface (AWS CLI)、API、OpenSearch クライアントを使用した操作を行うための IAM 認証情報が必要になります。この記事では、IAM 認証情報を使用してコレクションにアクセスします。
データ取り込みパイプラインを作成する
OpenSearch Serverless は、オープンソースの OpenSearch やマネージドクラスターと同じ取り込みパイプラインをサポートしています。これらのクライアントには、Logstash や Amazon Kinesis Data Firehose などのアプリケーションや、JavaScript、Python、Go、Java などの言語クライアントが含まれます。取り込みパイプラインとサポートされているクライアントの詳細については、ingesting data into OpenSearch Serverless collections を参照してください。
Logstash を使用する
Logstash のオープンソース版 (Logstash OSS) は、bulk API を使用してデータをコレクションにアップロードする便利な手段を提供しています。OpenSearch Serverless は logstash-output-opensearch 出力プラグインをサポートしており、データアクセスを制御するための IAM 認証情報をサポートしています。この記事では、ファイル入力プラグインを使用して、コマンドラインコンソールから OpenSearch Serverless コレクションにデータを送信する方法を説明します。以下のステップに従って進めてください。
logstash-oss-with-opensearch-output-pluginファイルをダウンロードします。(この例では、macos-x64 用のディストリビューションを使用します。他のディストロについては、Artifacts を参照してください)- ダウンロードした tar ファイルを解凍します。
logstash-output-opensearchプラグインを最新バージョンに更新します。OpenSearch Serverless の OpenSearch 出力プラグインは、認証に IAM 認証情報を使用します。この例では、ファイル入力プラグインを使用して、ファイルからデータを読み取り、OpenSearch Serverless コレクションに取り込む方法を説明します。
- 以下のサンプルデータを用いてログファイルを作成し、
sample.logと命名します。 - 新規ファイルを作成し、以下の内容を追加します。そして、ファイルパス、ホスト、リージョン、アクセスキー、シークレットアクセスキーに関する情報を記載したのち、
logstash-output-opensearch.confという名前でファイルを保存します。 - 以下のコマンドを使用して、前のステップで作成した設定ファイルを与えて Logstash を起動します。これにより、
logstash-sampleというインデックスが作成され、sample.logファイルの下に追加されたドキュメントを取り込みます。 - OpenSearch Dashboards を使って以下のクエリを実行して検索します。
GET logstash-sample/_search { "query": { "match_all": {} }, "track_total_hits" : true }

この手順では、Logstash のファイル入力プラグインを使用して、OpenSearch Serverless にデータを送信しました。入力プラグインを、Amazon Simple Storage Service (Amazon S3)、stdin、tcp など、Logstash がサポートする他のプラグインに置き換えて、OpenSearch Serverless コレクションにデータを送信することができます。
Python クライアントを使用する
OpenSearch は、いくつかの一般的なプログラミング言語の高レベルのクライアントを提供しており、これを使用してアプリケーションと統合することができます。OpenSearch Serverless では、既存の OpenSearch クライアントを引き続き使用して、コレクション内のデータをロードして、クエリを実行することができます。
このセクションでは、Python 用の opensearch-py クライアントを使用して、OpenSearch Serverless コレクションとの安全な接続の確立、インデックスの作成、サンプルログの送信、また OpenSearch Dashboards を使用してそれらのログデータを分析する方法を紹介します。この例では、商品や荷物を運ぶ船団から生成されたサンプルイベントを使用します。このデータには、配達元、配達先、天気、速度、交通量などの関連したフィールドが含まれています。以下がサンプルのレコードになります。
OpenSearch 用の Python クライアントをセットアップするためには、以下の前提条件が必要になります。
- ローカルマシンまたはこのコードを実行するサーバーに Python3 がインストールされていること。
- Package Installer for Python (PIP) がインストールされていること。
- AWS CLI が設定されていること。認証情報用のシークレットキーとアクセスキーを保存するために使用します。
Python クライアントをセットアップするために、以下の手順に従って進めてください。
- OpenSearch Python クライアントをプロジェクトに追加し、Python の仮想環境を使用して必要なパッケージをセットアップします。
- 以下のコマンドを使用し、アクセスキー、シークレットキー、リージョンを指定して、頻繁に利用する構成設定や認証情報を AWS CLI が管理するファイルに保存します。(aws configure を使用したクイック設定を参照してください)
- 以下のサンプルコードでは、Python 用の
opensearch-pyクライアントを使用して、指定した OpenSearch Serverless コレクションへの安全な接続を確立し、サンプルドキュメントをインデックス化して時系列のインデックスを作成します。ここでは、regionとhostに値を指定する必要があります。また、OpenSearch Serviceのサービス名としてaossを使用する必要があることに注意してください。コードをコピーして、sample_python.pyとしてファイルに保存します。 - サンプルコードを実行します。

- OpenSearch Service コンソールでコレクションを選択します。
- OpenSearch Dashboards で Dev Tools を選択します。
- 以下の検索クエリを実行し、ドキュメントを取得します。

データを取り込んだ後は、OpenSearch Dashboards を使ってデータを可視化することができます。次の例では、データを視覚的に分析し、ある船団が消費した燃料の平均、交通状況、移動距離、船団の平均総走行距離など、さまざまな面からの洞察を得ることができます。
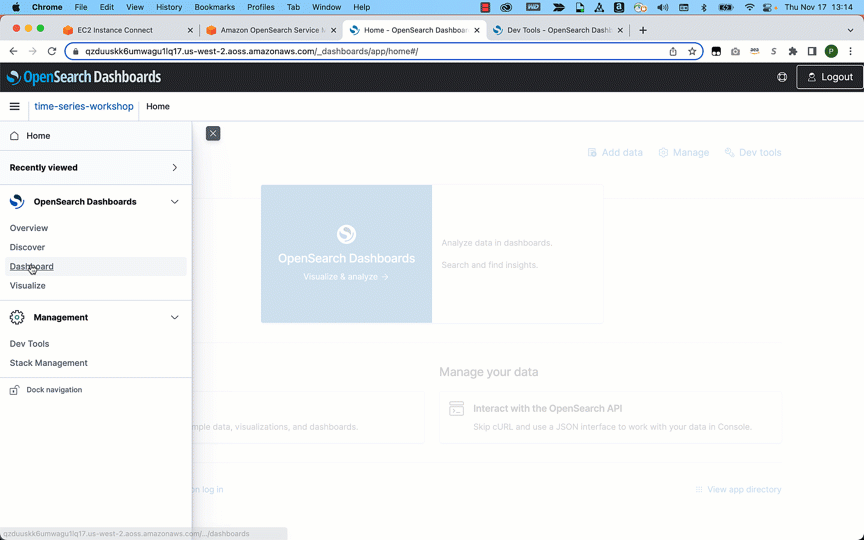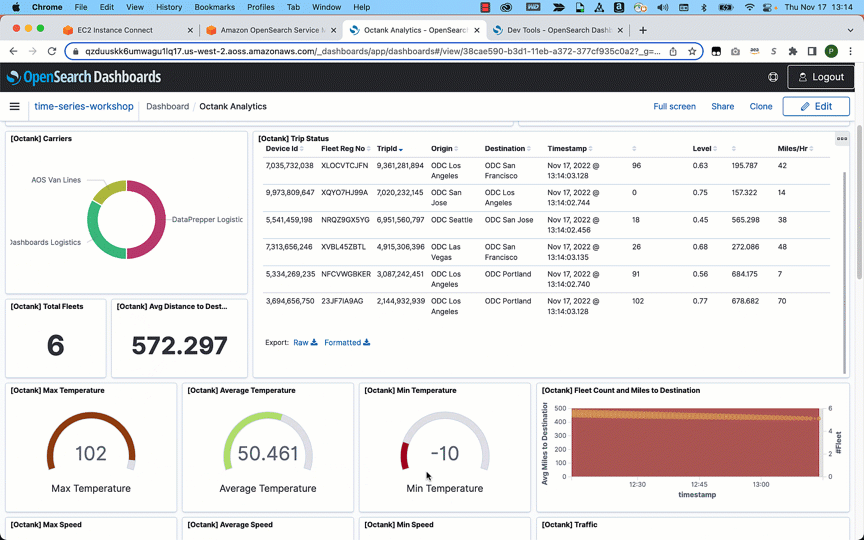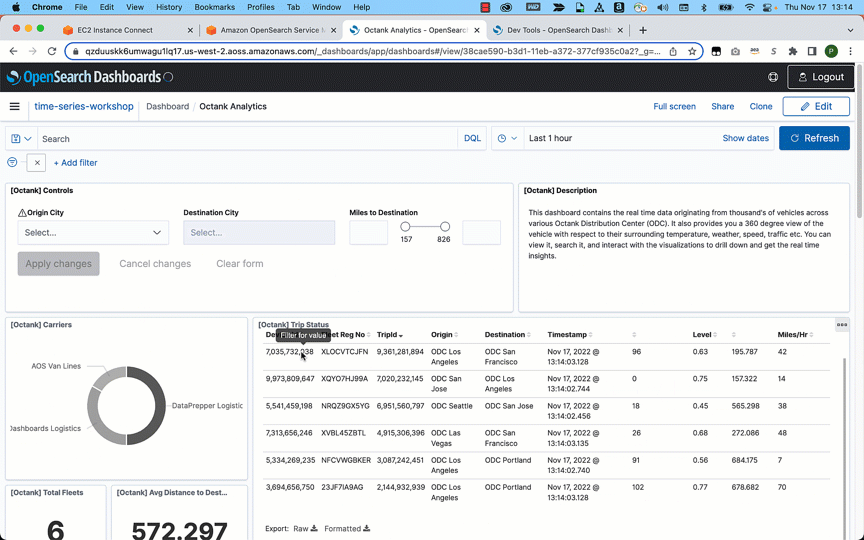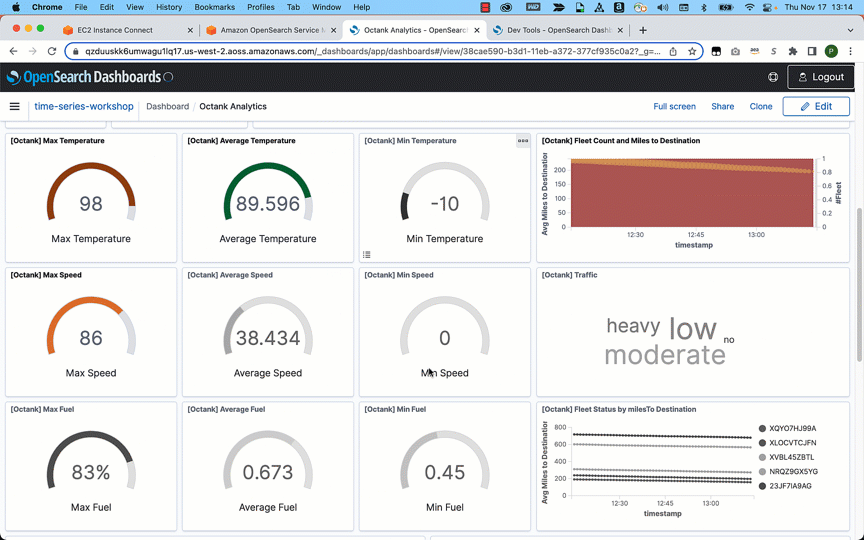
結論
この記事では、OpenSearch Service の新しいサーバーレスオプションである OpenSearch Serverless を使用して、ログ分析パイプラインを作成しました。OpenSearch Serverless を使用すると、基盤となるインフラストラクチャのプロビジョニング、チューニング、スケーリングを気にすることなく、アプリケーションの構築に集中することができます。OpenSearch Serverless は、オープンソースの OpenSearch と同じ取り込みパイプラインと高レベルのクライアントをサポートしています。使い慣れた OpenSearch のインデクシングやクエリ API を使用してデータをロードして検索し、OpenSearch Dashboards を使ってデータを可視化することで、簡単に使い始めることができます。
効果的なログ分析や検索アプリケーションを構築するのに利用可能なさまざまなオプションに焦点を当てた一連の記事をご期待ください。Getting Started with Amazon OpenSearch Serverless ハンズオンを使って OpenSearch Serverless を体験し、この記事で説明したものと同様のログ分析パイプラインを構築してみましょう。